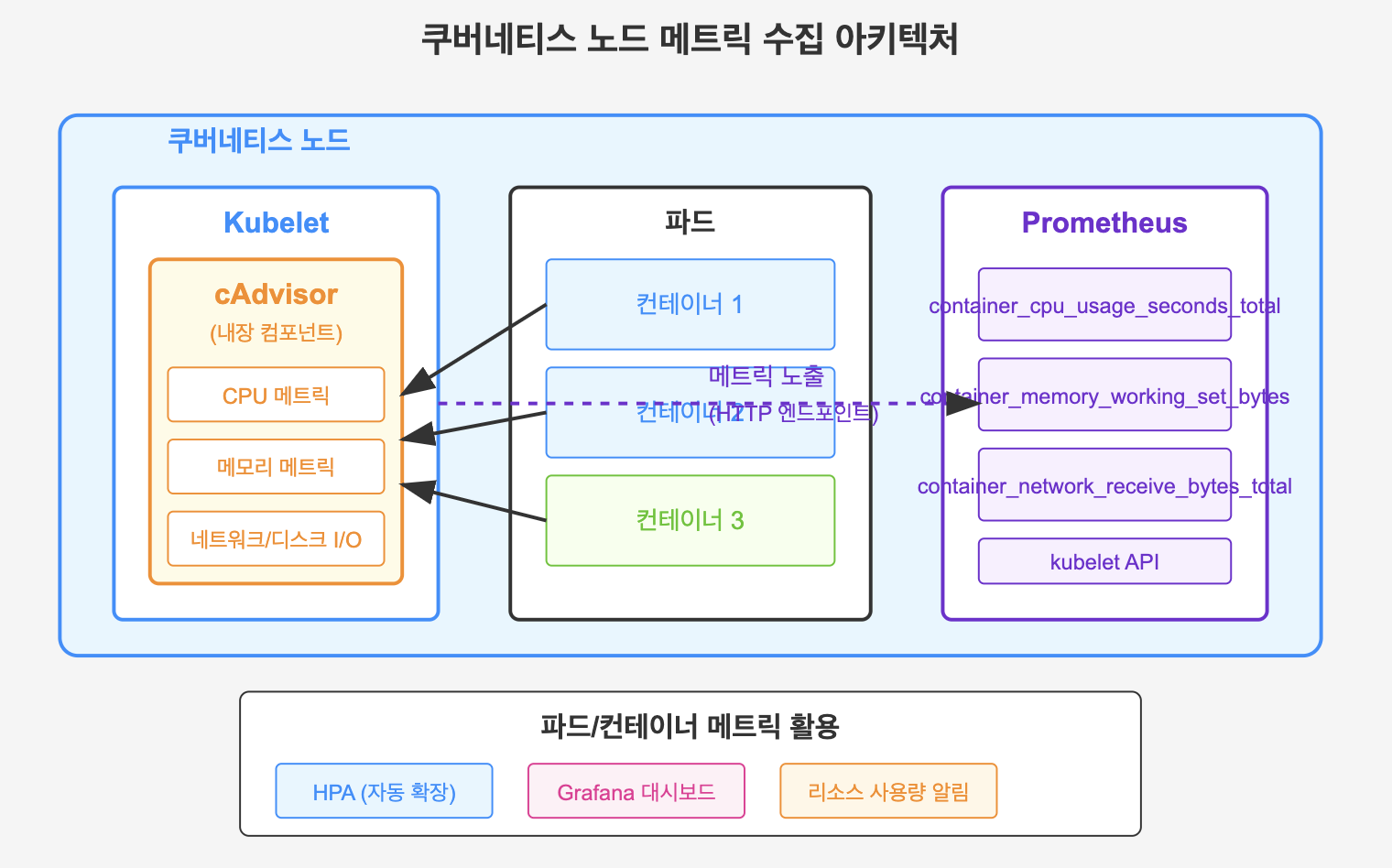
이번 글에서는 쿠버네티스 클러스터에서 파드와 네임스페이스 수준의 리소스를 모니터링하는 방법에 대해 깊이 있게 알아보겠습니다. 노드 수준을 넘어서 실제 워크로드가 실행되는 파드와 이를 논리적으로 구분하는 네임스페이스에 대한 모니터링은 애플리케이션 성능 최적화와 리소스 사용 효율성을 높이는 데 필수적입니다. Prometheus와 Grafana를 활용하여 파드의 CPU, 메모리 사용량을 추적하고, 네임스페이스별 리소스 쿼터 관리 방법, 효과적인 알림 설정, 그리고 실제 문제 상황에서의 트러블슈팅 접근법까지 실무에 바로 적용할 수 있는 내용을 다루겠습니다.📌 파드와 네임스페이스 모니터링의 중요성쿠버네티스에서 파드는 애플리케이션의 배포 단위이며, 네임스페이스는 이러한 파드들을 논리적으로 그룹화하는 방법입니다. ..