이번 글에서는 쿠버네티스 클러스터에서 파드와 네임스페이스 수준의 리소스를 모니터링하는 방법에 대해 깊이 있게 알아보겠습니다. 노드 수준을 넘어서 실제 워크로드가 실행되는 파드와 이를 논리적으로 구분하는 네임스페이스에 대한 모니터링은 애플리케이션 성능 최적화와 리소스 사용 효율성을 높이는 데 필수적입니다. Prometheus와 Grafana를 활용하여 파드의 CPU, 메모리 사용량을 추적하고, 네임스페이스별 리소스 쿼터 관리 방법, 효과적인 알림 설정, 그리고 실제 문제 상황에서의 트러블슈팅 접근법까지 실무에 바로 적용할 수 있는 내용을 다루겠습니다.
📌 파드와 네임스페이스 모니터링의 중요성
쿠버네티스에서 파드는 애플리케이션의 배포 단위이며, 네임스페이스는 이러한 파드들을 논리적으로 그룹화하는 방법입니다. 이러한 리소스를 효과적으로 모니터링하면 다음과 같은 이점이 있습니다:
✅ 리소스 사용 최적화
- 파드별 리소스 사용량 파악으로 요청(requests)과 제한(limits) 최적화
- 네임스페이스별 리소스 할당량 관리 및 비용 최적화
✅ 성능 문제 조기 발견
- 비정상적인 리소스 사용 패턴 식별
- 병목 현상 및 성능 저하의 조기 감지
✅ 효과적인 용량 계획
- 워크로드 증가에 따른 확장 계획 수립
- 클러스터 확장 시기 예측
▶️ 실제 사례: 한 기업에서는 특정 네임스페이스에서 갑작스러운 메모리 사용량 증가를 탐지하여 메모리 누수 버그를 조기에 발견했습니다. 이로 인해 프로덕션 장애를 예방할 수 있었습니다.
📌 쿠버네티스 메트릭 시스템 이해하기
쿠버네티스에서 파드와 네임스페이스 리소스를 모니터링하기 위해 중요한 메트릭 시스템을 알아보겠습니다.
✅ cAdvisor와 Kubelet
쿠버네티스는 각 노드에서 실행되는 Kubelet의 일부로 cAdvisor를 내장하고 있습니다. 이것이 컨테이너 메트릭의 주요 소스입니다:
[cAdvisor와 Kubelet의 관계를 나타내는 다이어그램.
- 각 노드에 kubelet과 통합된 cAdvisor
- 컨테이너에서 메트릭 수집
- Prometheus에 데이터 노출
- 파드와 컨테이너 수준의 메트릭 흐름 표시]
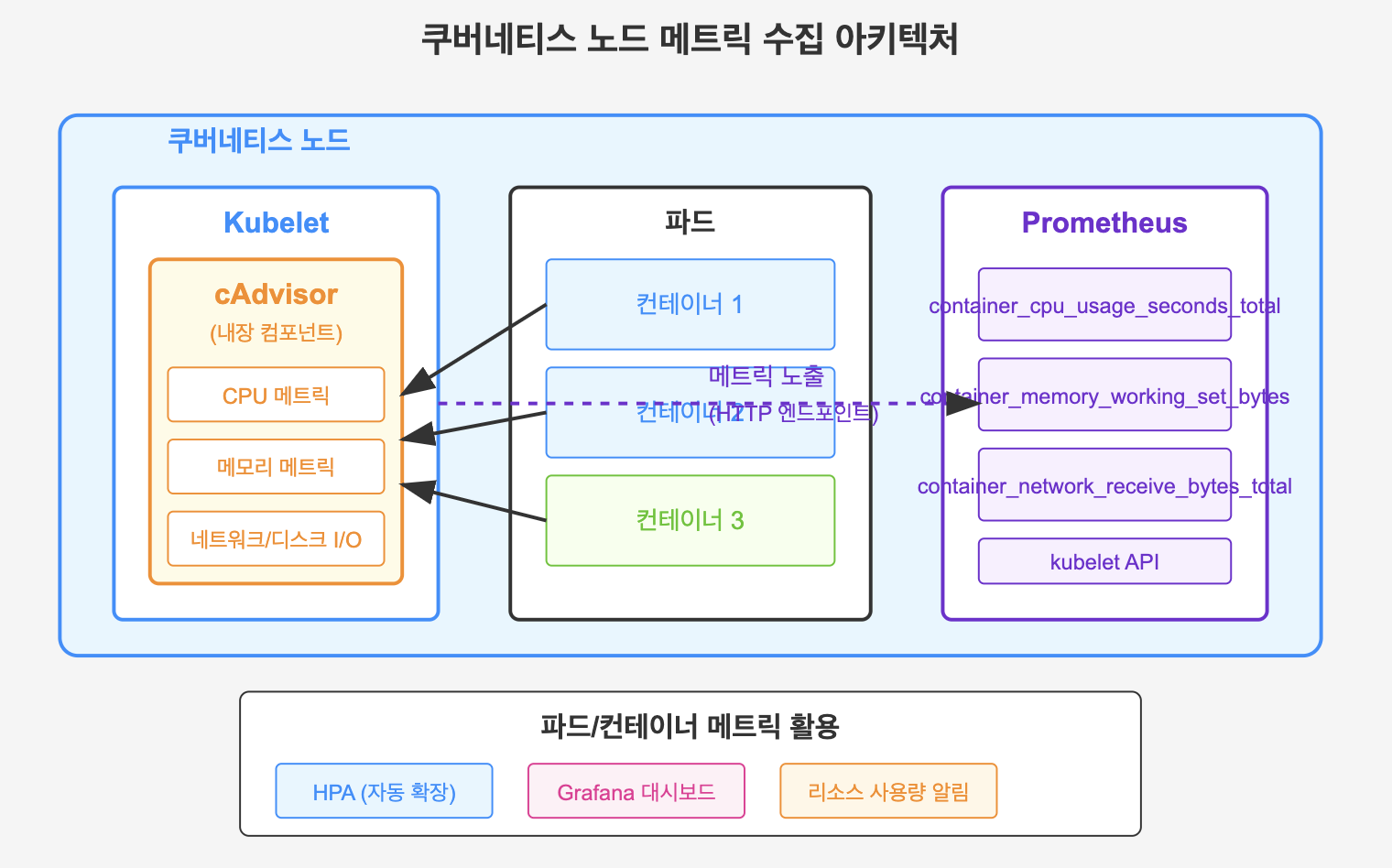
cAdvisor는 다음 메트릭을 수집합니다:
- 컨테이너 CPU 사용량
- 컨테이너 메모리 사용량
- 컨테이너 네트워크 I/O
- 컨테이너 디스크 I/O
✅ 메트릭 서버 (Metrics Server)
메트릭 서버는 CPU 및 메모리 사용량과 같은 리소스 메트릭을 집계하며, kubectl top 명령어와 HPA(Horizontal Pod Autoscaler)에 데이터를 제공합니다:
# 메트릭 서버 설치 (아직 설치하지 않은 경우)
# kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
#
# 이 명령어는 다음을 수행합니다:
# - metrics-server 네임스페이스 또는 kube-system에 리소스 생성
# - 필요한 RBAC 설정 (Role, ClusterRole, ServiceAccount 등) 생성
# - API 서비스 등록 (metrics.k8s.io API 그룹)
# - metrics-server 디플로이먼트 생성 (보통 1개 레플리카로 실행)
# - 서비스 생성 (API 접근용, 내부 클러스터 통신에 사용)
# - TLS 인증서 설정 (안전한 통신을 위해)
# 메트릭 서버 상태 확인
# 정상적으로 배포된 경우 Ready 상태가 1/1로 표시되어야 함
# 이 명령어는 디플로이먼트의 현재 상태, 레플리카 수, 업데이트 상태를 보여줌
kubectl get deployment metrics-server -n kube-system
# 메트릭 서버 파드 확인
# READY 열이 1/1인지, STATUS가 Running인지, RESTARTS가 적정한지 확인
# 파드 이름은 보통 'metrics-server-'로 시작하며 무작위 문자열이 뒤따름
kubectl get pods -n kube-system | grep metrics-server
▶️ 참고: 메트릭 서버는 메트릭을 장기간 저장하지 않습니다. 이는 가볍게 설계되어 실시간 리소스 사용량만 제공합니다. 장기적인 메트릭 스토리지와 분석에는 Prometheus를 사용해야 합니다.
✅ kube-state-metrics
kube-state-metrics는 쿠버네티스 API 서버를 리스닝하고 쿠버네티스 객체의 상태에 대한 메트릭을 생성합니다:
# kube-state-metrics 상태 확인 (Prometheus Operator로 설치한 경우)
# 이 명령어로 kube-state-metrics 파드의 상태를 확인
# READY가 1/1이고 STATUS가 Running이어야 정상 작동 중
kubectl get pods -n monitoring | grep kube-state-metrics
# 서비스 확인 (API가 노출되는 방식)
# 서비스 이름, 타입(보통 ClusterIP), IP, 포트(기본 8080) 정보 확인
# 이 서비스를 통해 Prometheus가 메트릭을 스크래핑함
kubectl get svc -n monitoring | grep kube-state-metrics
kube-state-metrics가 제공하는 주요 메트릭:
- 파드 상태 (running, pending, failed 등)
- 파드 리소스 요청 및 제한
- 네임스페이스 리소스 할당량
- 디플로이먼트 상태 및 복제본 수
- PVC 상태 및 스토리지 용량
▶️ 참고: cAdvisor는 컨테이너 리소스 사용량을 측정하고, kube-state-metrics는 쿠버네티스 객체의 상태 정보를 제공합니다. 이 두 가지는 상호 보완적인 역할을 합니다.
📌 파드 리소스 모니터링
개별 파드와 컨테이너의 리소스 사용량을 모니터링하는 방법을 살펴보겠습니다.
✅ 파드 CPU 및 메모리 사용량 모니터링
# 네임스페이스별 상위 10개 CPU 사용량 파드
# container_cpu_usage_seconds_total: 컨테이너가 사용한 CPU 시간(초) 측정 메트릭
# rate(): 지정된 시간 범위에서 초당 평균 변화율 계산
# container!="POD",container!="": 실제 애플리케이션 컨테이너만 선택(POD 인프라 컨테이너 제외)
# pod: 파드 이름으로 그룹화
# namespace: 네임스페이스로 그룹화 (다중 네임스페이스 환경에서 중요)
# [5m]: 5분 기간 동안의 데이터 사용 (급격한 변동 완화, 안정적인 추세 확인)
# topk(10, ...): 값이 가장 큰 상위 10개 결과만 반환 (가장 많은 리소스 사용 파드 식별)
# 결과는 CPU 코어 단위 (예: 0.5는 0.5 CPU 코어 사용)
topk(10, sum by (pod, namespace) (rate(container_cpu_usage_seconds_total{container!="POD",container!=""}[5m])))
# 네임스페이스별 상위 10개 메모리 사용량 파드
# container_memory_working_set_bytes: 컨테이너 메모리 작업 세트 크기 측정
# 이 메트릭은 OOM Killer가 고려하는 실제 메모리 사용량을 나타냄
# 캐시와 버퍼를 제외한 실제 애플리케이션이 사용 중인 메모리
# container!="POD",container!="": 실제 애플리케이션 컨테이너만 선택
# sum by (pod, namespace): 동일 파드 내 여러 컨테이너의 메모리 사용량 합산
# topk(10, ...): 상위 10개만 표시하여 가장 많은 메모리 사용 파드 식별
# 결과는 바이트 단위로 표시됨 (UI에서는 보통 MB/GB로 변환)
topk(10, sum by (pod, namespace) (container_memory_working_set_bytes{container!="POD",container!=""}))
✅ 컨테이너 리소스 요청 대비 사용량 비율
# CPU 요청 대비 사용량 비율
# kube_pod_container_resource_requests: 컨테이너 리소스 요청 값 메트릭
# resource="cpu": CPU 리소스만 필터링 (memory와 같은 다른 리소스 제외)
# group_left: 다중 대 일 관계에서 레이블 결합 허용 (조인 수행)
# 결과는 백분율로 표시 (100% = 요청한 CPU 양과 같은 사용량)
# 100% 이상이면 요청보다 많은 리소스 사용 중, 제한에 도달할 위험 있음
# 지속적으로 낮은 값(예: <30%)은 요청이 과도하게 설정되었을 수 있음을 의미
sum by (namespace, pod, container) (
rate(container_cpu_usage_seconds_total{container!="POD",container!=""}[5m])
) /
sum by (namespace, pod, container) (
kube_pod_container_resource_requests{resource="cpu"}
) * 100
# 메모리 요청 대비 사용량 비율
# kube_pod_container_resource_requests: 컨테이너 리소스 요청 값 메트릭
# resource="memory": 메모리 리소스만 필터링 (다른 리소스 제외)
# container_memory_working_set_bytes: 실제 메모리 사용량 (OOM Killer 기준)
# container!="POD",container!="": 인프라 컨테이너 제외
# 100% 이상은 요청보다 많은 메모리 사용 중을 의미
# 메모리는 압축할 수 없는 리소스이므로 100%에 가까울수록 주의 필요
# 결과는 백분율로 표시됨 (예: 85.7 = 요청의 85.7% 사용 중)
sum by (namespace, pod, container) (
container_memory_working_set_bytes{container!="POD",container!=""}
) /
sum by (namespace, pod, container) (
kube_pod_container_resource_requests{resource="memory"}
) * 100
✅ 컨테이너 리소스 제한 대비 사용량 비율
# CPU 제한 대비 사용량 비율
# kube_pod_container_resource_limits: 컨테이너 리소스 제한 값 메트릭
# resource="cpu": CPU 리소스만 필터링
# ignoring: 일치하지 않는 레이블 무시 (조인 수행 시)
# 결과는 백분율로 표시 (100% = 제한에 도달)
# 100%에 가까울수록 CPU 스로틀링 위험 증가
# CPU 제한이 설정되지 않은 컨테이너는 결과에 포함되지 않음
# 90% 이상이 지속되면 스로틀링 발생 가능성 높음
sum by (namespace, pod, container) (
rate(container_cpu_usage_seconds_total{container!="POD",container!=""}[5m])
) /
sum by (namespace, pod, container) (
kube_pod_container_resource_limits{resource="cpu"}
) * 100
# 메모리 제한 대비 사용량 비율
# kube_pod_container_resource_limits: 컨테이너 리소스 제한 값 메트릭
# resource="memory": 메모리 리소스만 필터링
# 결과는 백분율로 표시 (100% = 제한에 도달)
# 높은 비율(80% 이상)은 OOM 킬 위험 의미
# 메모리 제한이 설정되지 않은 컨테이너는 결과에 포함되지 않음
# 90% 이상이면 OOM 킬 발생 가능성 높아짐
sum by (namespace, pod, container) (
container_memory_working_set_bytes{container!="POD",container!=""}
) /
sum by (namespace, pod, container) (
kube_pod_container_resource_limits{resource="memory"}
) * 100
✅ 파드 재시작 및 상태 모니터링
파드의 안정성은 애플리케이션 가용성의 중요한 지표입니다:
# 파드 재시작 횟수 (지난 1시간)
# kube_pod_container_status_restarts_total: 컨테이너 재시작 총 횟수 메트릭
# increase(): 지정된 시간 범위 동안의 증가량 계산
# [1h]: 1시간 기간 동안의 증가 측정
# sum by (namespace, pod): 파드/네임스페이스별로 결과 집계
# 결과가 0보다 크면 해당 파드가 최근 1시간 내에 재시작됨을 의미
# 높은 값은 파드가 불안정하거나 문제가 있음을 나타냄
# 주기적으로 모니터링하여 재시작 패턴 파악 가능
sum by (namespace, pod) (
increase(kube_pod_container_status_restarts_total[1h])
)
# 비정상 상태 파드 (Ready가 아닌 파드)
# kube_pod_status_ready: 파드가 Ready 상태인지 여부 나타내는 메트릭
# condition="true": Ready=true인 파드만 선택
# == 0: 값이 0인 파드 필터링 (Ready=true이지만 값이 0 = 준비되지 않음)
# 이 쿼리는 실제로 Ready 상태가 아닌 모든 파드 목록 반환
# 결과에 포함된 파드는 준비되지 않아 트래픽을 처리할 수 없는 상태
# 장시간 이 상태로 남아있는 파드는 문제 해결 필요
kube_pod_status_ready{condition="true"} == 0
📌 네임스페이스 리소스 모니터링
네임스페이스는 쿠버네티스에서 리소스를 논리적으로 분리하는 단위입니다. 네임스페이스 수준의 모니터링을 통해 팀 또는 애플리케이션별 리소스 사용량을 파악할 수 있습니다.
✅ 네임스페이스별 CPU 및 메모리 사용량
# 네임스페이스별 CPU 사용량
# sum by (namespace): 네임스페이스별로 결과 집계 (동일 네임스페이스 내 모든 컨테이너 합산)
# container_cpu_usage_seconds_total: 컨테이너 CPU 사용 시간 메트릭
# rate(): 지정된 시간 범위에서 초당 변화율 계산
# [5m]: 5분 간격으로 계산 (단기 스파이크 완화)
# container!="POD",container!="": 실제 애플리케이션 컨테이너만 포함
# 결과는 각 네임스페이스가 사용 중인 CPU 코어 수 표시
# 예: 0.75는 해당 네임스페이스가 0.75 CPU 코어 사용 중임을 의미
sum by (namespace) (
rate(container_cpu_usage_seconds_total{container!="POD",container!=""}[5m])
)
# 네임스페이스별 메모리 사용량 (바이트)
# sum by (namespace): 네임스페이스별로 결과 집계
# container_memory_working_set_bytes: 실제 메모리 작업 세트 크기
# container!="POD",container!="": 실제 애플리케이션 컨테이너만 포함
# 결과는 바이트 단위로 반환되므로 GB 변환 가능 (/ 1024^3)
# 각 네임스페이스가 현재 사용 중인 총 메모리 양 표시
# 시간에 따른 추세를 관찰하여 메모리 증가/감소 패턴 파악 가능
sum by (namespace) (
container_memory_working_set_bytes{container!="POD",container!=""}
)
✅ 네임스페이스 리소스 쿼터 사용량
네임스페이스 리소스 쿼터(ResourceQuota)에 대한 사용량을 모니터링하는 것은 리소스 제한을 관리하는 데 중요합니다:
# CPU 쿼터 사용률 (%)
# kube_resourcequota_hard: 설정된 하드 쿼터 값 메트릭
# kube_resourcequota_used: 현재 사용 중인 쿼터 값 메트릭
# resource="requests.cpu": CPU 요청 쿼터만 필터링 (다른 리소스 제외)
# sum by (namespace, resourcequota): 네임스페이스와 쿼터 이름별로 그룹화
# 결과는 백분율로 표시 (100% = 쿼터 한도에 도달)
# 90% 이상 값은 쿼터 한도에 가까워 새 파드 생성이 제한될 수 있음을 의미
# 주기적으로 높은 값이 관찰되면 쿼터 증가 고려 필요
sum by (namespace, resourcequota) (
kube_resourcequota_used{resource="requests.cpu"}
) /
sum by (namespace, resourcequota) (
kube_resourcequota_hard{resource="requests.cpu"}
) * 100
# 메모리 쿼터 사용률 (%)
# resource="requests.memory": 메모리 요청 쿼터만 필터링
# kube_resourcequota_used: 현재 사용 중인 쿼터 값
# kube_resourcequota_hard: 설정된 하드 쿼터 값
# 결과는 백분율로 표시 (예: 75.5 = 쿼터의 75.5% 사용 중)
# 지속적으로 높은 값은 메모리 쿼터 증가 또는 최적화가 필요함을 의미
# 낮은 값(예: <30%)은 쿼터가 과도하게 설정되었을 수 있음
sum by (namespace, resourcequota) (
kube_resourcequota_used{resource="requests.memory"}
) /
sum by (namespace, resourcequota) (
kube_resourcequota_hard{resource="requests.memory"}
) * 100
✅ 네임스페이스별 파드 상태 분포
각 네임스페이스에서 파드의 상태 분포를 모니터링하면 전반적인 건강 상태를 파악할 수 있습니다:
# 네임스페이스별 Running 파드 수
# kube_pod_status_phase: 파드의 현재 상태 메트릭
# phase="Running": Running 상태인 파드만 선택
# sum by (namespace): 네임스페이스별로 결과 집계
# 결과는 각 네임스페이스에서 현재 실행 중인 파드 수 표시
# 갑작스러운 변화는 배포/롤백 또는 문제 상황을 나타낼 수 있음
# 일정한 값이 유지되는 것이 일반적으로 안정적인 상태를 의미
sum by (namespace) (
kube_pod_status_phase{phase="Running"}
)
# 네임스페이스별 비정상 파드 수 (Failed 또는 Pending)
# phase="Failed": 실패한 파드 (0이 아닌 종료 코드로 종료됨)
# phase="Pending": 대기 중인 파드 (노드에 스케줄링되지 않음, 이미지 다운로드 중 등)
# sum by (namespace): 네임스페이스별로 결과 집계
# or 연산자: Failed 또는 Pending 상태인 파드 모두 포함
# 결과는 각 네임스페이스의 비정상 파드 수 표시
# 0이 아닌 값은 문제가 있을 수 있음을 나타냄
# Pending 상태가 지속되면 리소스 부족, 이미지 문제 등 원인 조사 필요
sum by (namespace) (
kube_pod_status_phase{phase="Failed"} or
kube_pod_status_phase{phase="Pending"}
)
📌 효과적인 모니터링 대시보드 구성
수집한 파드 및 네임스페이스 메트릭을 시각화하기 위한 Grafana 대시보드를 구성해 보겠습니다.
✅ 핵심 대시보드 컴포넌트
효과적인 파드/네임스페이스 모니터링 대시보드는 다음 섹션을 포함해야 합니다:
- 파드 건강 상태 패널
- 전체 파드 수 및 상태별 분포
- 비정상 파드 수
- 최근 재시작 파드 목록
- 네임스페이스 리소스 사용량 패널
- 네임스페이스별 CPU/메모리 사용량
- 쿼터 사용률
- 시간별 추세
- 상위 리소스 소비 파드 패널
- CPU/메모리 상위 소비 파드
- 리소스 요청 대비 비율
- 이상 탐지 지표
[파드 및 네임스페이스 모니터링을 위한 Grafana 대시보드 레이아웃.
- 상단: 전체 클러스터 개요 및 네임스페이스 요약
- 중간: 네임스페이스별 리소스 사용량 그래프
- 하단: 상위 리소스 소비 파드 테이블 및 세부 지표]
✅ 파드 모니터링 대시보드 쿼리 예제
네임스페이스와 파드를 선택할 수 있는 변수를 설정하는 것이 유용합니다:
-- 네임스페이스 변수
-- label_values: Prometheus 데이터에서 고유한 레이블 값 목록 가져오기
-- namespace: 대상 레이블 (메트릭에서 namespace 레이블의 모든 값 추출)
-- 결과: 클러스터의 모든 네임스페이스 목록이 드롭다운으로 표시됨
-- 사용자는 이 드롭다운에서 특정 네임스페이스 선택 가능
-- 'All' 옵션을 포함하여 모든 네임스페이스를 한 번에 볼 수 있게 구성 가능
-- 변수명: $namespace로 다른 쿼리에서 참조 가능
label_values(namespace)
-- 선택된 네임스페이스의 파드 변수
-- label_values: 고유한 레이블 값 목록 가져오기
-- kube_pod_info{namespace="$namespace"}: 선택된 네임스페이스($namespace)의 파드 정보
-- pod: 대상 레이블 (pod 레이블의 모든 값 추출)
-- $namespace: 앞서 정의한 네임스페이스 변수 참조
-- 결과: 선택한 네임스페이스 내 모든 파드 목록이 드롭다운으로 표시
-- 네임스페이스 선택이 변경되면 파드 목록도 자동으로 업데이트됨
-- 변수명: $pod로 다른 쿼리에서 참조 가능
label_values(kube_pod_info{namespace="$namespace"}, pod)
CPU 사용량 패널:
# 선택한 파드의 시간별 CPU 사용량
# $pod: Grafana 변수 (사용자가 UI에서 선택한 파드 이름)
# $namespace: Grafana 변수 (사용자가 UI에서 선택한 네임스페이스)
# rate(): 지정된 기간 동안 초당 변화율 계산
# [1m]: 1분 간격 레이트 계산 (더 촘촘한 데이터 포인트 생성)
# container!="POD",container!="": 실제 애플리케이션 컨테이너만 선택
# sum(): 선택한 파드의 모든 컨테이너 CPU 사용량 합산
# 결과: CPU 코어 사용량의 시계열 그래프 (예: 0.35 = 0.35 CPU 코어 사용)
# 그래프 범위는 보통 0부터 파드의 CPU 제한(또는 요청의 2배)까지 설정
sum(
rate(container_cpu_usage_seconds_total{pod="$pod",namespace="$namespace",container!="POD",container!=""}[1m])
)
메모리 사용량 패널:
# 선택한 파드의 시간별 메모리 사용량
# container_memory_working_set_bytes: 실제 메모리 작업 세트 크기 측정
# pod="$pod": 선택한 파드로 필터링 (Grafana 변수)
# namespace="$namespace": 선택한 네임스페이스로 필터링 (Grafana 변수)
# container!="POD",container!="": 인프라 컨테이너 제외
# sum(): 파드 내 모든 컨테이너의 메모리 사용량 합산
# 결과: 메모리 사용량의 시계열 그래프 (바이트 단위, 보통 MB/GB로 표시됨)
# 그래프에 메모리 요청/제한 수평선을 추가하면 사용량 대비 설정값 비교 용이
sum(
container_memory_working_set_bytes{pod="$pod",namespace="$namespace",container!="POD",container!=""}
)
✅ 네임스페이스 대시보드 쿼리 예제
네임스페이스 리소스 사용률:
# 네임스페이스별 CPU 사용률 (요청 대비 %)
# on(namespace): namespace 레이블로 조인 수행
# rate(): 지정된 기간 동안 초당 변화율 계산
# [5m]: 5분 간격으로 계산 (단기 스파이크 완화)
# kube_pod_container_resource_requests: 컨테이너 리소스 요청 메트릭
# resource="cpu": CPU 자원만 필터링
# 결과: 각 네임스페이스가 요청한 CPU 대비 실제 사용 비율 (백분율)
# 100% 이상이면 요청보다 많은 리소스 사용 중, 스케줄링 문제 발생 가능
# 지속적으로 낮은 값은 리소스가 과도하게 요청되었음을 의미
sum by (namespace) (
rate(container_cpu_usage_seconds_total{container!="POD",container!=""}[5m])
) /
sum by (namespace) (
kube_pod_container_resource_requests{resource="cpu"}
) * 100
네임스페이스별 파드 상태:
# 네임스페이스별 파드 상태 분포
# kube_pod_status_phase: 파드의 현재 상태 메트릭
# by (namespace, phase): 네임스페이스와 상태별로 그룹화
# phase: 파드 상태 (Running, Pending, Failed, Succeeded, Unknown)
# 결과: 각 네임스페이스의 각 상태별 파드 수 표시
# 파이 차트, 막대 그래프, 테이블 등으로 시각화 가능
# 상태별 색상 구분 (Running=녹색, Pending=노란색, Failed=빨간색 등)
# 비정상 상태(Failed, Pending, Unknown)가 많으면 문제 상황 의심
sum by (namespace, phase) (
kube_pod_status_phase
)
📌 알림 및 이상 탐지 설정
파드 및 네임스페이스 수준에서 효과적인 알림 규칙을 설정하는 방법을 알아보겠습니다.
✅ 파드 관련 알림 규칙
# 파드 상태 알림 규칙
# 파일명: pod-alerts.yaml
# 적용 방법: kubectl apply -f pod-alerts.yaml
# 주요 알림:
# 1. 파드 재시작 횟수 증가 - 애플리케이션 불안정성 감지
# 2. 파드 준비 상태 이상 - 트래픽을 처리할 수 없는 파드 감지
# 3. 리소스 사용량 임계값 초과 - 메모리 한계 접근 파드 감지
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: pod-alerts
namespace: monitoring
labels:
app: kube-prometheus-stack # kube-prometheus-stack에서 인식하기 위한 레이블
release: prometheus # 일반적인 Helm 릴리스 이름, 환경에 맞게 조정 필요
spec:
groups:
- name: pod.rules # 규칙 그룹 이름 (관련 규칙 묶음)
rules:
# 파드 재시작 알림
# increase(): 지정된 기간 동안의 증가량 계산
# kube_pod_container_status_restarts_total: 컨테이너 재시작 총 횟수
# > 5: 1시간 동안 5회 이상 재시작된 경우만 알림
# for: 10m: 이 조건이 10분 이상 지속될 경우만 알림 발생 (일시적 문제 필터링)
# severity: warning: 알림 심각도 (critical보다 낮은 수준)
- alert: PodFrequentlyRestarting
expr: increase(kube_pod_container_status_restarts_total[1h]) > 5
for: 10m
labels:
severity: warning
annotations:
summary: "파드 잦은 재시작 ({{ $labels.namespace }}/{{ $labels.pod }})"
description: "파드 {{ $labels.namespace }}/{{ $labels.pod }}가 지난 1시간 동안 5회 이상 재시작했습니다.\n 현재 재시작 횟수: {{ $value }}"
# 파드 준비 상태 알림
# kube_pod_status_ready{condition="true"} == 0: Ready 상태가 아닌 파드
# kube_pod_owner: 파드 소유자 정보
# owner_kind!="Job": Job이 아닌 리소스가 소유한 파드만 대상 (Job은 일시적으로 준비 안 된 상태 정상)
# for: 15m: 15분 이상 준비 안 된 상태가 지속될 경우 알림
- alert: PodNotReady
expr: sum by(namespace, pod) (kube_pod_status_ready{condition="true"} == 0) * on(namespace, pod) group_left(owner_kind) kube_pod_owner{owner_kind!="Job"} > 0
for: 15m
labels:
severity: warning
annotations:
summary: "파드 준비 안됨 ({{ $labels.namespace }}/{{ $labels.pod }})"
description: "파드 {{ $labels.namespace }}/{{ $labels.pod }}가 15분 이상 준비 상태가 아닙니다."
# 메모리 사용량 높음 알림
# container_memory_working_set_bytes: 실제 메모리 사용량
# kube_pod_container_resource_limits: 설정된 메모리 제한
# > 90: 메모리 제한의 90% 이상 사용 시 알림
# for: 10m: 10분 이상 지속될 경우 알림 (일시적 스파이크 무시)
# humanizePercentage: 백분율 형식으로 값 출력 (예: 95%)
- alert: PodMemoryUsageHigh
expr: sum by(namespace, pod) (container_memory_working_set_bytes{container!="POD",container!=""}) / sum by(namespace, pod) (kube_pod_container_resource_limits{resource="memory"}) * 100 > 90
for: 10m
labels:
severity: warning
annotations:
summary: "파드 메모리 사용량 높음 ({{ $labels.namespace }}/{{ $labels.pod }})"
description: "파드 {{ $labels.namespace }}/{{ $labels.pod }}의 메모리 사용량이 제한의 90%를 초과했습니다.\n 현재 사용률: {{ $value | humanizePercentage }}"
✅ 네임스페이스 관련 알림 규칙
# 네임스페이스 알림 규칙
# 파일명: namespace-alerts.yaml
# 적용 방법: kubectl apply -f namespace-alerts.yaml
# 주요 알림:
# 1. 네임스페이스 쿼터 높은 사용률 - 리소스 소진 위험 알림
# 2. 네임스페이스 내 파드 장애 비율 높음 - 불안정한 네임스페이스 감지
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: namespace-alerts
namespace: monitoring
labels:
app: kube-prometheus-stack # kube-prometheus-stack에서 인식하기 위한 레이블
release: prometheus # Helm 릴리스 이름에 맞게 조정
spec:
groups:
- name: namespace.rules # 규칙 그룹 이름
rules:
# 네임스페이스 CPU 쿼터 사용량 알림
# container_cpu_usage_seconds_total: 컨테이너 CPU 사용 시간
# kube_resourcequota: 리소스 쿼터 정보
# resource="requests.cpu", type="hard": CPU 요청의 하드 쿼터 값
# > 90: CPU 쿼터의 90% 이상 사용 시 알림
# for: 15m: 15분 이상 지속될 경우만 알림 (일시적 사용량 급증 무시)
- alert: NamespaceCpuQuotaUsageHigh
expr: sum by (namespace) (rate(container_cpu_usage_seconds_total{container!="POD",container!=""}[5m])) / sum by (namespace) (kube_resourcequota{resource="requests.cpu", type="hard"}) * 100 > 90
for: 15m
labels:
severity: warning
annotations:
summary: "네임스페이스 CPU 쿼터 사용량 높음 ({{ $labels.namespace }})"
description: "네임스페이스 {{ $labels.namespace }}의 CPU 쿼터 사용량이 90%를 초과했습니다.\n 현재 사용률: {{ $value | humanizePercentage }}"
# 네임스페이스 메모리 쿼터 사용량 알림
# container_memory_working_set_bytes: 실제 메모리 사용량
# kube_resourcequota: 리소스 쿼터 정보
# resource="requests.memory", type="hard": 메모리 요청의 하드 쿼터 값
# > 90: 메모리 쿼터의 90% 이상 사용 시 알림
# 쿼터 제한에 가까워지면 새 파드 생성이 제한될 수 있음
- alert: NamespaceMemoryQuotaUsageHigh
expr: sum by (namespace) (container_memory_working_set_bytes{container!="POD",container!=""}) / sum by (namespace) (kube_resourcequota{resource="requests.memory", type="hard"}) * 100 > 90
for: 15m
labels:
severity: warning
annotations:
summary: "네임스페이스 메모리 쿼터 사용량 높음 ({{ $labels.namespace }})"
description: "네임스페이스 {{ $labels.namespace }}의 메모리 쿼터 사용량이 90%를 초과했습니다.\n 현재 사용률: {{ $value | humanizePercentage }}"
# 네임스페이스 내 파드 실패 비율 알림
# kube_pod_status_phase: 파드의 현재 상태
# phase=~"Failed|Pending": Failed 또는 Pending 상태인 파드
# phase=~"Failed|Pending|Running|Succeeded": 모든 상태의 파드
# > 10: 전체 파드 중 10% 이상이 비정상 상태일 경우 알림
# 높은 실패율은 해당 네임스페이스에 문제가 있음을 의미
- alert: NamespacePodFailureRateHigh
expr: sum by(namespace) (kube_pod_status_phase{phase=~"Failed|Pending"}) / sum by (namespace) (kube_pod_status_phase{phase=~"Failed|Pending|Running|Succeeded"}) * 100 > 10
for: 10m
labels:
severity: warning
annotations:
summary: "네임스페이스 파드 실패율 높음 ({{ $labels.namespace }})"
description: "네임스페이스 {{ $labels.namespace }}의 파드 실패율이 10%를 초과했습니다.\n 현재 실패율: {{ $value | humanizePercentage }}"
✅ 효과적인 알림 임계값 설정
알림 임계값을 설정할 때 고려해야 할 사항:
- 기준선 이해:
- 애플리케이션의 정상 리소스 사용 패턴 파악
- 최소 2주간의 기준 데이터 수집
- 일간/주간 패턴 및 사용량 추세 분석
- 점진적 접근:
- 처음에는 보수적인 임계값 설정 (예: 90%)
- 실제 알림 패턴에 따라 점진적으로 조정
- 알림 발생 후 검토 및 미세 조정 프로세스 수립
- 컨텍스트 고려:
- 네임스페이스마다 다른 임계값 적용 가능
- 중요도에 따라 다른 감도 설정 (핵심 서비스는 더 엄격한 임계값)
- 환경별 차별화(개발, 스테이징, 프로덕션)
- 알림 피로 방지:
- 짧은 스파이크에 알림이 발생하지 않도록 지속 시간 설정
- 중복 알림 억제 규칙 구성
- 알림 그룹화 및 라우팅 전략 수립
▶️ 실제 사례: 한 회사는 처음에 메모리 사용량 80% 임계값으로 시작했지만, 너무 많은 알림이 발생했습니다. 데이터 분석 후 90%로 조정하고 지속 시간을 5분에서 15분으로 늘려 중요한 알림만 받을 수 있도록 했습니다.
📌 파드 및 네임스페이스 모니터링 모범 사례
파드 및 네임스페이스 모니터링을 효과적으로 수행하기 위한 모범 사례를 살펴보겠습니다.
✅ 리소스 요청 및 제한 적절히 설정
정확한 모니터링을 위해서는 모든 컨테이너에 적절한 리소스 요청(requests)과 제한(limits)을 설정해야 합니다:
# 리소스 요청 및 제한 예제
# apiVersion: apps/v1: Deployment 리소스 API 버전
# kind: Deployment: 리소스 종류
# spec.template.spec.containers[].resources: 컨테이너 리소스 설정
# requests: 최소 보장 리소스 (스케줄링 시 고려됨)
# limits: 최대 사용 가능 리소스 (초과 시 제한/종료됨)
# cpu: 100m = 0.1 CPU 코어 (1000m = 1 코어)
# memory: 메모리 양 (Mi = MiB, Gi = GiB)
apiVersion: apps/v1
kind: Deployment
metadata:
name: example-app
spec:
template:
spec:
containers:
- name: example-container
resources:
requests:
cpu: 100m # 0.1 CPU 코어 요청 - 최소 보장값
memory: 256Mi # 256 MiB 메모리 요청 - 최소 보장값
limits:
cpu: 500m # 0.5 CPU 코어 제한 - 최대 사용값
memory: 512Mi # 512 MiB 메모리 제한 - 최대 사용값 (초과 시 OOM Kill)
✅ 네임스페이스 쿼터 설정
네임스페이스에 리소스 쿼터를 설정하여 리소스 사용량을 제한하고 효과적으로 모니터링할 수 있습니다:
# 네임스페이스 리소스 쿼터 예제
# apiVersion: v1: ResourceQuota API 버전
# kind: ResourceQuota: 리소스 종류
# metadata.namespace: 쿼터 적용 네임스페이스
# spec.hard: 하드 리소스 제한 값 목록
# requests.cpu/memory: CPU/메모리 요청 총량 제한
# limits.cpu/memory: CPU/메모리 제한 총량 제한
# pods: 최대 파드 수
# configmaps, secrets: 구성 리소스 수 제한
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources
namespace: example-namespace
spec:
hard:
requests.cpu: "10" # 10 CPU 코어 요청 총량 (모든 파드 합산)
requests.memory: 20Gi # 20GB 메모리 요청 총량 (모든 파드 합산)
limits.cpu: "20" # 20 CPU 코어 제한 총량 (모든 파드 합산)
limits.memory: 40Gi # 40GB 메모리 제한 총량 (모든 파드 합산)
pods: "50" # 최대 50개 파드 허용
configmaps: "20" # 최대 20개 ConfigMap 허용
secrets: "20" # 최대 20개 Secret 허용
✅ 레이블 전략 수립
효과적인 모니터링을 위해 일관된 레이블 전략을 수립합니다:
# 레이블 전략 예제
# metadata.labels: 리소스의 레이블 지정
# app: 애플리케이션 이름 (애플리케이션 식별)
# component: 애플리케이션 내 구성 요소 (역할 식별)
# env: 환경 구분 (dev, staging, prod 등)
# tier: 아키텍처 계층 (frontend, backend, database 등)
# team: 담당 팀 (소유권/책임 식별)
# 이런 레이블을 통해 Prometheus에서 쉽게 필터링/그룹화 가능
apiVersion: apps/v1
kind: Deployment
metadata:
name: api-server
labels:
app: bookstore # 애플리케이션 식별자
component: api # 구성 요소 (API 서버)
env: production # 환경 (프로덕션)
tier: backend # 티어 (백엔드)
team: platform-eng # 담당 팀 (플랫폼 엔지니어링)
spec:
template:
metadata:
labels:
app: bookstore
component: api
env: production
tier: backend
team: platform-eng
이러한 레이블을 사용하여 PromQL 쿼리를 작성할 수 있습니다:
# 팀별 CPU 사용량 쿼리
# sum by (team): team 레이블로 결과 그룹화
# rate(): 지정된 기간 동안 초당 변화율 계산
# [5m]: 5분 간격으로 계산
# 결과: 각 팀이 사용 중인 총 CPU 코어 수
# 이를 통해 팀별 리소스 사용 추세 및 비용 분석 가능
# 예: 플랫폼 엔지니어링 팀이 2.5 CPU 코어 사용 중
sum by (team) (
rate(container_cpu_usage_seconds_total{container!="POD",container!=""}[5m])
)
✅ 모니터링 비용 최적화
대규모 클러스터에서는 모니터링 자체의 리소스 사용량도 고려해야 합니다:
- 스크래핑 간격 조정:
- 덜 중요한 메트릭은 스크래핑 간격 늘리기 (예: 1분→5분)
- 단기 트렌드보다 장기 패턴이 중요한 메트릭에 적합
- 모든 메트릭을 기본 15초 간격으로 수집 시 비용 증가
- 메트릭 필터링:
- 필요한 메트릭만 수집
- 사용하지 않는 메트릭 드롭
- 특정 네임스페이스/앱에 집중
# Prometheus 메트릭 릴레이션 설정 예제
# apiVersion: monitoring.coreos.com/v1: Prometheus Operator API 버전
# kind: PodMonitor: 파드 메트릭 스크래핑 설정
# spec.selector: 대상 파드 선택 기준 (레이블 기반)
# spec.podMetricsEndpoints: 메트릭 엔드포인트 설정
# port: 메트릭 노출 포트
# interval: 스크래핑 간격 (초 단위)
# relabelings: 메트릭 수집 전 레이블 조작 설정
# action: keep - 매칭되는 메트릭만 유지, 나머지 드롭
# regex: 필터링할 정규식 패턴 ('|'로 여러 패턴 구분)
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: example-app
namespace: monitoring
spec:
selector:
matchLabels:
app: example-app
podMetricsEndpoints:
- port: metrics
interval: 30s # 30초마다 스크래핑 (기본값보다 긴 간격)
relabelings:
- sourceLabels: [__name__]
regex: 'example_app_(requests|errors|latency).*' # 필요한 메트릭만 필터링
action: keep # 매칭되는 메트릭만 유지, 나머지 무시
- 적절한 보존 기간 설정:
- 장기 스토리지와 단기 스토리지 분리
- 시간에 따른 다운샘플링 구성
- 중요도에 따른 메트릭별 보존 기간 차별화
# Prometheus 보존 및 압축 설정
# 파일명: prometheus-values.yaml
# Helm 차트 배포 시 사용 (prometheus.prometheusSpec 섹션)
# retention: 데이터 보존 기간 (15d = 15일)
# retentionSize: 최대 저장 크기 (디스크 공간 제한)
# tsdb 압축 설정으로 스토리지 효율화
# minBlockDuration: 최소 블록 지속 시간 (최소 압축 단위)
# maxBlockDuration: 최대 블록 지속 시간 (장기 압축 단위)
prometheus:
prometheusSpec:
retention: 15d # 15일간 데이터 보존
retentionSize: 10GB # 최대 10GB 크기로 제한
tsdb:
outOfOrderTimeWindow: 10m # 시간순이 아닌 샘플 허용 창
minBlockDuration: 2h # 최소 블록 지속 시간 (2시간)
maxBlockDuration: 24h # 최대 블록 지속 시간 (24시간)
📌 실제 트러블슈팅 시나리오
파드 및 네임스페이스 모니터링을 통해 발견할 수 있는 실제 문제 시나리오와 해결 방법을 살펴보겠습니다.
✅ 시나리오 1: 메모리 누수 탐지
문제: 시간이 지남에 따라 특정 파드의 메모리 사용량이 지속적으로 증가
탐지 쿼리:
# 메모리 사용량 증가율 측정
# deriv(): 시계열의 시간에 따른 변화율 (기울기) 계산
# container_memory_working_set_bytes: 실제 메모리 작업 세트 크기
# namespace="app-namespace": 특정 네임스페이스로 필터링
# container!="POD",container!="": 실제 애플리케이션 컨테이너만 선택
# [30m]: 30분 간격으로 추세 계산 (단기 변동 완화)
# > 0: 양의 기울기(증가)만 필터링 (메모리 사용량이 증가하는 컨테이너만)
# 결과: 초당 메모리 증가율 (바이트/초)
# 지속적으로 양수 값이 나오면 메모리 누수 의심
deriv(
container_memory_working_set_bytes{namespace="app-namespace",container!="POD",container!=""}[30m]
) > 0
해결 단계:
- 해당 파드의 로그 분석
- 애플리케이션 프로파일링
- 메모리 제한 임시 증가
- 파드 주기적 재시작 설정
# 파드 주기적 재시작 설정
# apiVersion: batch/v1: CronJob API 버전
# kind: CronJob: 주기적 작업 설정
# spec.schedule: 실행 일정 (cron 형식: 분 시 일 월 요일)
# spec.jobTemplate: 실행할 작업 템플릿
# serviceAccountName: 필요한 권한을 가진 서비스 계정
# command: 실행할 명령어
# kubectl rollout restart: 디플로이먼트 롤링 재시작 명령
# 이 예제는 매일 자정에 디플로이먼트 롤링 재시작 수행
apiVersion: batch/v1
kind: CronJob
metadata:
name: restart-deployment
namespace: app-namespace
spec:
schedule: "0 0 * * *" # 매일 00:00에 실행 (자정)
jobTemplate:
spec:
template:
spec:
serviceAccountName: deployment-restarter # 적절한 RBAC 권한 필요
containers:
- name: kubectl
image: bitnami/kubectl:latest # kubectl 명령어가 포함된 이미지
command:
- /bin/sh
- -c
- kubectl rollout restart deployment leaky-app -n app-namespace # 롤링 재시작 명령
restartPolicy: OnFailure # 작업 실패 시 재시작 정책
✅ 시나리오 2: 리소스 한계 도달
문제: CPU 제한에 반복적으로 도달하여 스로틀링 발생
탐지 쿼리:
# CPU 스로틀링 탐지
# container_cpu_cfs_throttled_seconds_total: CPU 스로틀링 시간 총계 메트릭
# rate(): 지정된 기간 동안 초당 변화율 계산
# [5m]: 5분 간격으로 계산
# container_cpu_usage_seconds_total: 총 CPU 사용 시간
# 비율: (스로틀링 시간)/(총 CPU 사용 시간) - 스로틀링 비율
# > 0.1: 10% 이상 스로틀링 발생 시 (CPU 시간의 10% 이상이 제한됨)
# 값이 클수록 심각한 스로틀링 발생 (예: 0.5 = 50% 스로틀링)
# 지속적인 스로틀링은 애플리케이션 성능 저하 의미
rate(container_cpu_cfs_throttled_seconds_total{container!="POD",container!=""}[5m]) /
rate(container_cpu_usage_seconds_total{container!="POD",container!=""}[5m]) > 0.1
해결 단계:
- 부하 테스트로 실제 필요 CPU 측정
- 리소스 요청과 제한 조정
- 워크로드 분산 또는 수평적 확장 고려
# HorizontalPodAutoscaler 설정 예시
# apiVersion: autoscaling/v2: HPA API 버전
# kind: HorizontalPodAutoscaler: 수평적 파드 자동 확장 설정
# spec.scaleTargetRef: 스케일링 대상 (어떤 리소스를 스케일링할지)
# spec.minReplicas: 최소 레플리카 수 (항상 유지할 최소 파드 수)
# spec.maxReplicas: 최대 레플리카 수 (최대로 확장 가능한 파드 수)
# spec.metrics: 스케일링 기준 지표 (어떤 조건에서 스케일링할지)
# resource.name: 대상 리소스 (cpu, memory 등)
# target.type: 타겟 유형 (Utilization = 사용률 기준)
# target.averageUtilization: 목표 평균 사용률 (%)
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: cpu-intensive-app
namespace: app-namespace
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment # 대상 리소스 종류 (Deployment)
name: cpu-intensive-app # 대상 디플로이먼트 이름
minReplicas: 2 # 최소 2개 파드 유지
maxReplicas: 10 # 최대 10개까지 확장 가능
metrics:
- type: Resource
resource:
name: cpu # CPU 리소스 기준 스케일링
target:
type: Utilization
averageUtilization: 70 # CPU 사용률 70% 초과 시 스케일 아웃
✅ 시나리오 3: 네임스페이스 쿼터 제한 도달
문제: 네임스페이스 리소스 쿼터 제한에 도달하여 새 파드 생성 실패
탐지 쿼리:
# 네임스페이스 쿼터 사용률
# kube_resourcequota: 리소스 쿼터 정보 메트릭
# type="used": 현재 사용 중인 쿼터 값
# type="hard": 설정된 하드 쿼터 제한 값
# 쿼터 사용률 = (사용량/제한) * 100 (백분율)
# > 95: 쿼터의 95% 이상 사용 시 탐지
# resource: 각 리소스 유형 (requests.cpu, limits.memory 등)
# quota: 쿼터 이름
# 결과는 임계값(95%)을 초과하는 쿼터 목록 표시
sum by (namespace, resource, quota) (
kube_resourcequota{type="used"}
) /
sum by (namespace, resource, quota) (
kube_resourcequota{type="hard"}
) * 100 > 95
해결 단계:
- 네임스페이스 리소스 쿼터 증가 검토
- 사용되지 않는 리소스 식별 및 정리
- 더 효율적인 리소스 사용을 위한 애플리케이션 최적화
# 네임스페이스의 리소스 사용량 확인
# kubectl describe quota -n <namespace>
# 이 명령어는 해당 네임스페이스의 모든 쿼터 정보 표시
# Used: 현재 사용량
# Hard: 제한값
# 각 리소스 유형별 사용량/제한 비교 가능
# requests.cpu, limits.cpu, requests.memory, limits.memory 등 확인
kubectl describe quota -n app-namespace
# 네임스페이스의 비활성 리소스 확인
# 사용되지 않는 파드, 디플로이먼트 등 확인
# 완료된 작업이나 사용되지 않는 리소스 정리 필요
# 7일 이상 완료된 작업 정리
# 이 명령어는 완료 시간이 7일 이상 경과한 Job 리소스 조회 및 삭제
# jq를 사용하여 JSON 처리: 완료 시간 필터링
# .status.completionTime != null: 완료된 작업만 선택
# .status.completionTime | fromdate: 완료 시간을 타임스탬프로 변환
# now - 604800: 현재 시간에서 7일(604800초) 이전
# xargs: 각 작업 이름을 kubectl delete job 명령에 전달하여 삭제
kubectl get jobs -n app-namespace -o json | jq '.items[] | select(.status.completionTime != null) | select((.status.completionTime | fromdate) < (now - 604800)) | .metadata.name' | xargs kubectl delete job -n app-namespace
📌 Summary
이번 포스트에서는 쿠버네티스 클러스터의 파드와 네임스페이스 리소스 모니터링에 대해 자세히 알아보았습니다. 다음과 같은 내용을 다루었습니다:
- 파드와 네임스페이스 모니터링의 중요성: 쿠버네티스에서 워크로드 단위인 파드와 논리적 격리 단위인 네임스페이스의 모니터링이 클러스터 안정성과 성능 최적화에 미치는 영향을 이해했습니다. 실시간 리소스 사용 추적을 통해 비용 최적화와 성능 문제 조기 발견이 가능해집니다.
- 쿠버네티스 메트릭 시스템: cAdvisor, Metrics Server, kube-state-metrics가 각각 어떤 역할을 하는지, 그리고 이들이 어떻게 상호 보완적으로 모니터링 데이터를 제공하는지 살펴보았습니다. 특히 실시간 메트릭과 상태 메트릭의 차이점을 이해하는 것이 효과적인 모니터링의 기초가 됩니다.
- 파드 리소스 모니터링: 개별 파드와 컨테이너의 CPU, 메모리 사용량을 추적하고, 리소스 요청 및 제한 대비 사용량을 분석하는 방법을 배웠습니다. 특히 요청 대비 실제 사용률과 제한 근접도를 모니터링하는 것이 중요합니다.
- 네임스페이스 리소스 모니터링: 네임스페이스 수준에서 리소스 사용량과 쿼터 관리를 위한 모니터링 전략을 살펴보았습니다. 네임스페이스별 리소스 추세 파악과 쿼터 사용률 모니터링은 클러스터 관리자가 리소스 분배를 최적화하는 데 필수적입니다.
- 효과적인 대시보드 구성: Grafana 변수를 활용하여 상호작용 가능한 대시보드를 구성하고, 파드와 네임스페이스 메트릭을 효과적으로 시각화하는 방법을 배웠습니다. 잘 설계된 대시보드는 복잡한 클러스터 상황을 한눈에 파악하게 해줍니다.
- 알림 및 이상 탐지: 파드 재시작, 준비 상태 이상, 리소스 사용량 초과, 쿼터 한계 접근 등 중요한 문제 상황을 감지하는 알림 규칙을 설정하는 방법을 살펴보았습니다. 효과적인 임계값 설정 전략과 알림 피로 방지 방법도 함께 고려했습니다.
- 모범 사례: 리소스 요청/제한 설정, 네임스페이스 쿼터 관리, 일관된 레이블 전략, 모니터링 비용 최적화 등 실용적인 모범 사례를 정리했습니다. 이러한 방법은 모니터링 시스템 자체의 성능과 효율성을 높이는 데 중요합니다.
- 실제 트러블슈팅 시나리오: 메모리 누수, CPU 스로틀링, 쿼터 제한 도달과 같은 실제 문제 상황을 탐지하고 해결하는 방법을 구체적인 예시로 살펴보았습니다. 이러한 실전 접근법은 실제 운영 환경에서 직면할 수 있는 문제에 대응하는 데 유용합니다.
'Observability > Prometheus' 카테고리의 다른 글
| EP10 [Part 4: Grafana 대시보드 마스터하기] Grafana 설치 및 기본 설정 (0) | 2025.03.24 |
|---|---|
| EP09 [Part 3: 클러스터 모니터링 깊게 들여다보기] 네트워크 및 시스템 메트릭 분석 (0) | 2025.03.24 |
| EP07 [Part 3: 클러스터 모니터링 깊게 들여다보기] 노드 리소스 모니터링 (2) | 2025.03.23 |
| EP06 [Part 2: Prometheus Operator 설치와 구성 #3] 기본 설정 및 커스터마이징 (0) | 2025.03.23 |
| EP05 [Part 2: Prometheus Operator 설치와 구성 #2] Helm을 사용한 kube-prometheus-stack 배포 (0) | 2025.03.19 |