이번 글에서는 쿠버네티스 클러스터에서 노드 리소스를 효과적으로 모니터링하는 방법에 대해 심층적으로 알아보겠습니다. 노드는 쿠버네티스 인프라의 기본 단위로, 이들의 상태와 리소스 사용을 정확히 모니터링하는 것이 클러스터 안정성과 성능 최적화의 핵심입니다. 특히 CPU, 메모리, 디스크, 네트워크와 같은 주요 리소스 메트릭을 수집하고 분석하는 방법과 Prometheus Node Exporter의 구성 및 활용법을 살펴볼 것입니다. 또한 PromQL을 사용한 노드 상태 분석 쿼리,
효과적인 대시보드 구성, 적절한 알림 규칙 설정까지 다루어 노드 수준에서 발생할 수 있는 성능 문제를 사전에 탐지하고 해결하는 전략을 알아보겠습니다. 마지막으로 노드 모니터링의 모범 사례와 실제 트러블슈팅 방법론까지 포함하여 바로 적용할 수 있는 종합적인 가이드를 제공할 예정입니다.
📌 노드 모니터링이 중요한 이유
쿠버네티스 클러스터에서 노드는 워크로드가 실행되는 물리적 또는 가상 머신입니다. 노드 리소스를 효과적으로The assistant can create and reference artifacts during conversations. 모니터링하지 않으면 다음과 같은 문제가 발생할 수 있습니다:
✅ 리소스 병목 현상
- CPU나 메모리 부족으로 인한 애플리케이션 성능 저하
- 디스크 I/O 병목으로 인한 지연 시간 증가
✅ 예기치 않은 다운타임
- 노드 장애 감지 지연으로 인한 서비스 중단
- 리소스 고갈로 인한 노드 불안정성
✅ 비효율적인 리소스 사용
- 과도하게 프로비저닝된 리소스로 인한 비용 낭비
- 불균형한 워크로드 분배
▶️ 실제 사례: 한 프로덕션 환경에서 모니터링 부재로 인해 특정 노드의 디스크 공간이 서서히 소진되어 결국 중요 서비스가 다운되는 사고가 발생했습니다. 적절한 노드 모니터링이 구축되어 있었다면 사전에 감지하고 조치할 수 있었을 것입니다.
📌 노드 모니터링을 위한 핵심 메트릭
쿠버네티스 노드에서 모니터링해야 할 핵심 메트릭들을 살펴보겠습니다:
✅ CPU 관련 메트릭
CPU 메트릭은 노드의 처리 능력과 부하를 이해하는 데 필수적입니다:
# CPU 사용률(%) 조회
# node_cpu_seconds_total: 각 CPU 모드별 누적 시간(초)
# rate(): 지정된 시간 범위에서 평균 증가율 계산
# irate(): 순간 증가율 계산(더 짧은 시간대 반영)
# by (instance): 인스턴스별로 결과 그룹화
# 1 - (idle 모드 시간 비율) = CPU 사용률
100 - (avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)
▶️ 참고: node_cpu_seconds_total는 다양한 CPU 모드(idle, user, system 등)에서 소비된 시간을 초 단위로 측정합니다. idle 모드가 아닌 시간 비율이 CPU 사용률을 나타냅니다.
✅ 메모리 관련 메트릭
메모리 메트릭은 노드의 메모리 상태와 잠재적인 병목 현상을 파악하는 데 중요합니다:
# 메모리 사용률(%) 조회
# node_memory_MemTotal_bytes: 전체 메모리 양
# node_memory_MemFree_bytes: 사용 가능한 메모리 양
# node_memory_Buffers_bytes: 버퍼에 사용되는 메모리
# node_memory_Cached_bytes: 캐시에 사용되는 메모리
# 모든 값은 바이트 단위이며, 계산식은 Linux 시스템의 메모리 계산 방식과 동일
100 * (1 - ((node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes) / node_memory_MemTotal_bytes))
▶️ 심화 정보: 리눅스에서 free -m 명령어로 확인하는 메모리 사용량과 유사한 방식으로 계산됩니다. 버퍼와 캐시는 필요시 해제될 수 있는 메모리이므로 실제 사용 가능한 메모리에 포함됩니다.
✅ 디스크 관련 메트릭
디스크 메트릭은 스토리지 용량 및 I/O 성능을 모니터링하는 데 사용됩니다:
# 디스크 사용률(%) 조회
# node_filesystem_size_bytes: 파일시스템 전체 크기
# node_filesystem_free_bytes: 사용 가능한 파일시스템 공간
# mountpoint="/": 루트 파일시스템만 필터링
# fstype!="tmpfs": 임시 파일시스템 제외
100 * (1 - node_filesystem_free_bytes{mountpoint="/",fstype!="tmpfs"} / node_filesystem_size_bytes{mountpoint="/",fstype!="tmpfs"})
# 디스크 I/O 확인 (초당 읽기/쓰기 작업 수)
# node_disk_reads_completed_total: 완료된 디스크 읽기 작업 총 수
# node_disk_writes_completed_total: 완료된 디스크 쓰기 작업 총 수
# rate(): 지정된 기간 동안의 초당 증가율
# [5m]: 5분 간격으로 계산 (필요에 따라 조정 가능)
# 디스크 읽기 작업 (IOPS)
rate(node_disk_reads_completed_total{device="sda"}[5m])
# 디스크 쓰기 작업 (IOPS)
rate(node_disk_writes_completed_total{device="sda"}[5m])
✅ 네트워크 관련 메트릭
네트워크 메트릭은 노드 간 통신과 외부 연결의 성능을 모니터링합니다:
# 네트워크 트래픽 (초당 수신/송신 바이트)
# node_network_receive_bytes_total: 수신된 총 바이트 수
# node_network_transmit_bytes_total: 송신된 총 바이트 수
# device!~"lo|veth.*|docker.*|flannel.*|cali.*|cbr.*": 시스템 및 가상 인터페이스 제외
# 실제 물리적 네트워크 인터페이스만 표시
# 수신 트래픽 (초당 바이트)
rate(node_network_receive_bytes_total{device!~"lo|veth.*|docker.*|flannel.*|cali.*|cbr.*"}[5m])
# 송신 트래픽 (초당 바이트)
rate(node_network_transmit_bytes_total{device!~"lo|veth.*|docker.*|flannel.*|cali.*|cbr.*"}[5m])
▶️ 주의사항: 필터링 패턴(device!~"lo|veth.*|...)은 환경에 따라 다를 수 있으므로 자신의 클러스터 네트워크 구성에 맞게 조정해야 합니다.
📌 Node Exporter 이해하기
지금까지 살펴본 노드 메트릭은 대부분 Prometheus Node Exporter에서 수집됩니다. Node Exporter는 리눅스/유닉스 시스템의 하드웨어 및 OS 메트릭을 노출시키는 Prometheus 익스포터입니다.
✅ Node Exporter가 수집하는 데이터
Node Exporter는 다음과 같은 다양한 시스템 정보를 수집합니다:
- CPU 통계 (사용률, 로드 등)
- 메모리 정보 (사용량, 스왑 등)
- 디스크 메트릭 (사용량, I/O 등)
- 네트워크 통계 (인터페이스별 트래픽 등)
- 파일시스템 정보
- 온도 및 전력 정보 (하드웨어 지원 시)
✅ Node Exporter의 작동 방식

Node Exporter는 일반적으로 다음과 같이 작동합니다:
- 쿠버네티스 클러스터의 각 노드에서 데몬셋(DaemonSet)으로 실행됨
- 노드의 운영체제와 하드웨어 메트릭 수집
- HTTP 엔드포인트(기본 포트: 9100)를 통해 메트릭 노출
- Prometheus 서버가 이 엔드포인트를 스크래핑하여 데이터 수집
✅ Node Exporter 상태 확인
실행 중인 Node Exporter의 상태를 확인하려면:
# Node Exporter 파드 확인
# -n monitoring: 모니터링 네임스페이스에서 검색
# -l app=node-exporter: app=node-exporter 레이블을 가진 파드만 필터링
# 명령어 실행 결과 확인 포인트:
# - 모든 노드에 파드가 Running 상태인지 확인
# - READY 상태가 모두 1/1인지 확인
# - RESTARTS 값이 적정한지 확인 (높은 값은 불안정성 의미)
kubectl get pods -n monitoring -l app=node-exporter
다음은 Node Exporter 설정을 확인하는 방법입니다:
# Node Exporter DaemonSet 설정 확인
# 명령어: kubectl get ds -n monitoring prometheus-node-exporter -o yaml
# 주요 확인 사항:
# - 리소스 할당량(requests/limits)
# - 마운트된 볼륨(특히 hostPath)
# - 노드 선택자 및 허용 설정
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: prometheus-node-exporter
namespace: monitoring
spec:
selector:
matchLabels:
app: node-exporter
template:
metadata:
labels:
app: node-exporter
spec:
hostNetwork: true # 호스트 네트워크 사용 - 노드의 네트워크 스택에 직접 접근 가능
hostPID: true # 호스트 PID 네임스페이스 사용 - 노드의 모든 프로세스 정보 접근 가능
containers:
- name: node-exporter
image: prom/node-exporter:v1.5.0
args:
- --path.procfs=/host/proc # 호스트의 proc 파일시스템에 접근하기 위한 경로 설정
- --path.sysfs=/host/sys # 호스트의 sys 파일시스템에 접근하기 위한 경로 설정
- --collector.filesystem.ignored-mount-points=^/(dev|proc|sys|var/lib/docker/.+)($|/) # 특정 마운트 포인트 무시
ports:
- containerPort: 9100 # Node Exporter 기본 포트
protocol: TCP
resources:
limits:
cpu: 250m # CPU 리소스 제한 - 과도한 CPU 사용 방지
memory: 180Mi # 메모리 리소스 제한 - OOM 킬 방지
requests:
cpu: 102m # 최소 CPU 리소스 요청
memory: 180Mi # 최소 메모리 리소스 요청
volumeMounts:
- mountPath: /host/proc # 호스트의 proc 파일시스템 마운트
name: proc
readOnly: true
- mountPath: /host/sys # 호스트의 sys 파일시스템 마운트
name: sys
readOnly: true
- mountPath: /rootfs # 호스트의 루트 파일시스템 마운트
name: root
readOnly: true
volumes:
- hostPath: # 호스트 경로 볼륨 타입 - 노드의 파일시스템에 접근
path: /proc
name: proc
- hostPath:
path: /sys
name: sys
- hostPath:
path: /
name: root
tolerations: # 모든 노드에서 실행될 수 있도록 허용 설정
- operator: Exists # 모든 테인트에 대해 허용
위 설정에서 주목할 점들:
- hostNetwork: true - Node Exporter가 호스트 네트워크를 직접 사용합니다.
- hostPID: true - 호스트의 모든 프로세스 정보에 접근할 수 있습니다.
- 볼륨 마운트 - /proc, /sys, / (루트) 파일시스템을 마운트하여 시스템 정보에 접근합니다.
- 리소스 제한 - CPU와 메모리 사용량을 제한하여 노드 안정성을 보장합니다.
- 허용(Tolerations) - 모든 노드에서 실행될 수 있도록 테인트를 허용합니다.
📌 PromQL을 활용한 노드 상태 분석
Prometheus Query Language(PromQL)를 사용하여 노드 상태를 분석하는 고급 쿼리를 살펴보겠습니다:
✅ 노드 가용성 모니터링
# 노드 가용성 모니터링
# up{job="node-exporter"}: Node Exporter의 가용성 상태 (1: 가동 중, 0: 다운)
# up{job="kubelet"}: Kubelet의 가용성 상태
# 이 쿼리는 어떤 노드가 다운되었는지 빠르게 파악하는 데 유용
# Node Exporter가 다운된 노드 찾기
up{job="node-exporter"} == 0
# Kubelet이 다운된 노드 찾기
up{job="kubelet"} == 0
✅ 노드 리소스 사용량 순위 쿼리
# CPU 사용량 기준 상위 5개 노드
# topk(): 지정된 기준에 따라 상위 N개 항목 반환
# 5: 상위 5개 노드 반환
# by (instance): 인스턴스(노드)별 그룹화
# 결과는 CPU 사용률이 높은 순서대로 노드 목록 제공
topk(5, 100 - (avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100))
# 메모리 사용량 기준 상위 5개 노드
# 메모리 사용률이 높은 노드를 신속하게 파악할 수 있음
# 메모리 병목 현상이 발생할 가능성이 있는 노드 식별에 유용
topk(5, 100 * (1 - ((node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes) / node_memory_MemTotal_bytes)))
✅ 디스크 공간 부족 노드 식별
# 디스크 공간이 10% 미만으로 남은 노드 찾기
# < 10: 디스크 여유 공간이 10% 미만인 노드 필터링
# fstype!~"tmpfs|...": 임시/특수 파일시스템 제외
# mountpoint!~"/boot": 부트 파티션 제외 (일반적으로 관리가 다름)
# 이 쿼리는 디스크 공간 부족으로 인한 장애 예방에 중요
100 * (node_filesystem_free_bytes{fstype!~"tmpfs|fuse.lxcfs|squashfs|vfat",mountpoint!~"/boot"} / node_filesystem_size_bytes{fstype!~"tmpfs|fuse.lxcfs|squashfs|vfat",mountpoint!~"/boot"}) < 10
✅ 노드 로드 평균 모니터링
# 노드 로드 평균 대비 CPU 코어 수 비율
# node_load1: 1분 평균 로드
# scalar(count(node_cpu_seconds_total{mode="idle",instance=~"$instance"})/count(node_cpu_seconds_total{mode="idle",instance=~"$instance"})): CPU 코어 수 계산
# > 1.5: 로드가 코어 수의 1.5배를 초과하는 경우 (필요에 따라 조정)
# 높은 값은 CPU 병목 현상을 나타냄
# 1분 평균 로드
node_load1{instance=~"$instance"} / scalar(count(node_cpu_seconds_total{mode="idle",instance=~"$instance"})/count(node_cpu_seconds_total{mode="idle",instance=~"$instance"})) > 1.5
# 5분 평균 로드 (더 안정적인 추세)
node_load5{instance=~"$instance"} / scalar(count(node_cpu_seconds_total{mode="idle",instance=~"$instance"})/count(node_cpu_seconds_total{mode="idle",instance=~"$instance"})) > 1.5
# 15분 평균 로드 (장기적 추세)
node_load15{instance=~"$instance"} / scalar(count(node_cpu_seconds_total{mode="idle",instance=~"$instance"})/count(node_cpu_seconds_total{mode="idle",instance=~"$instance"})) > 1.5
📌 노드 모니터링 대시보드 구성하기
효과적인 노드 모니터링을 위한 Grafana 대시보드 구성 방법을 알아보겠습니다.
✅ 추천 대시보드: Node Exporter Full
Node Exporter Full(ID: 1860)은 Grafana 커뮤니티에서 가장 인기 있는 노드 모니터링 대시보드 중 하나입니다:
대시보드 가져오기:
# Grafana 대시보드 가져오기
# 방법 1: Grafana UI에서 직접 가져오기
# - Grafana UI > Dashboards > Import > 1860 입력
# 방법 2: kubectl로 ConfigMap 생성 후 적용
# 다음 명령어는 대시보드 JSON을 ConfigMap으로 적용하는 예시
# 주의: 실제 파일 경로와 네임스페이스는 환경에 맞게 조정 필요
kubectl create configmap node-exporter-full-dashboard \
--from-file=node-exporter-full.json \
-n monitoring
✅ 커스텀 노드 대시보드 만들기
특정 요구사항에 맞는 커스텀 대시보드를 만들 수 있습니다. 다음은 핵심 패널의 예시입니다:
1. 노드 상태 개요 패널
# 노드 상태 요약을 위한 PromQL (STAT 패널)
# up{job="node-exporter"} => 1 또는 0 반환
# count(up{job="node-exporter"}) => 전체 노드 수
# count(up{job="node-exporter"} == 1) => 정상 노드 수
# 패널 설정:
# - 패널 유형: Stat
# - 시각화: 테이블
# - 단위: 숫자
# - 임계값: 노드 수에 따라 조정
# 전체 노드 수
count(up{job="node-exporter"})
# 정상 노드 비율 (%)
count(up{job="node-exporter"} == 1) / count(up{job="node-exporter"}) * 100
2. 노드 CPU 사용량 패널
# 노드별 CPU 사용률 시계열 차트
# 패널 설정:
# - 패널 유형: Time series
# - X축: 시간
# - Y축: 비율 (%)
# - 범례: 노드 이름
# - 단위: 백분율
# - 임계값: 70%, 85% (경고, 위험)
100 - (avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)
3. 노드 메모리 사용량 패널
# 노드별 메모리 사용률 히트맵
# 패널 설정:
# - 패널 유형: Heatmap
# - X축: 시간
# - Y축: 메모리 사용률 (%)
# - 색상: 파란색(낮음) → 빨간색(높음)
# - 셀 크기: 예: 10% 단위
# - 임계값: 70%, 90% (경고, 위험)
100 * (1 - ((node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes) / node_memory_MemTotal_bytes))
4. 디스크 공간 패널
# 노드별 디스크 사용률 게이지
# 패널 설정:
# - 패널 유형: Gauge
# - 범위: 0-100%
# - 임계값: 70%, 85% (경고, 위험)
# - 정렬: 사용률 내림차순
# - 최대 표시 항목: 10개 (상위 10개 디스크)
100 * (1 - node_filesystem_free_bytes{mountpoint="/",fstype!="tmpfs"} / node_filesystem_size_bytes{mountpoint="/",fstype!="tmpfs"})
📌 알림 규칙 설정하기
노드 리소스 모니터링을 위한 중요 Prometheus 알림 규칙을 설정해 보겠습니다:
✅ PrometheusRule 리소스 생성하기
다음과 같이 PrometheusRule 리소스를 생성하여 노드 관련 알림을 설정할 수 있습니다:
# 노드 모니터링을 위한 알림 규칙
# 파일명: node-alerts.yaml
# 적용 방법: kubectl apply -f node-alerts.yaml
# 주요 알림:
# 1. 노드 다운 감지
# 2. 높은 CPU 사용률
# 3. 높은 메모리 사용률
# 4. 디스크 공간 부족
# 5. 높은 시스템 로드
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: node-monitoring-rules
namespace: monitoring
labels:
app: kube-prometheus-stack # kube-prometheus-stack에서 인식하기 위한 레이블
release: prometheus # Helm 릴리스 이름에 맞게 조정 필요
spec:
groups:
- name: node.rules # 규칙 그룹 이름
rules:
# 노드 다운 알림
- alert: NodeDown # 알림 이름
expr: up{job="node-exporter"} == 0 # 표현식 - Node Exporter가 다운된 경우
for: 5m # 지속 시간 - 5분 이상 지속될 경우 알림 발생
labels:
severity: critical # 알림 심각도 - critical은 즉시 조치 필요
annotations:
summary: "Node down (instance {{ $labels.instance }})" # 알림 요약
description: "Node {{ $labels.instance }} has been down for more than 5 minutes." # 상세 설명
# 높은 CPU 사용률 알림
- alert: HighCPUUsage
expr: 100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 85 # 85% 이상일 경우
for: 10m # 10분 이상 지속될 경우 알림 발생
labels:
severity: warning # 알림 심각도 - warning은 주의 필요
annotations:
summary: "High CPU usage (instance {{ $labels.instance }})"
description: "CPU usage is above 85% for more than 10 minutes.\nCurrent usage: {{ $value }}%"
# 높은 메모리 사용률 알림
- alert: HighMemoryUsage
expr: 100 * (1 - ((node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes) / node_memory_MemTotal_bytes)) > 90 # 90% 이상일 경우
for: 5m # 5분 이상 지속될 경우 알림 발생
labels:
severity: warning
annotations:
summary: "High memory usage (instance {{ $labels.instance }})"
description: "Memory usage is above 90% for more than 5 minutes.\nCurrent usage: {{ $value }}%"
# 디스크 공간 부족 알림
- alert: LowDiskSpace
expr: 100 * (node_filesystem_free_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"}) < 10 # 10% 미만일 경우
for: 15m # 15분 이상 지속될 경우 알림 발생
labels:
severity: warning
annotations:
summary: "Low disk space (instance {{ $labels.instance }})"
description: "Disk space is below 10% for more than 15 minutes.\nCurrent free space: {{ $value }}%"
# 높은 시스템 로드 알림 (계속)
- alert: HighSystemLoad
expr: node_load1 / on(instance) group_left() count without(cpu, mode) (node_cpu_seconds_total{mode="idle"}) by (instance) > 2 # 코어당 로드가 2 이상일 경우
for: 10m # 10분 이상 지속될 경우 알림 발생
labels:
severity: warning
annotations:
summary: "High system load (instance {{ $labels.instance }})"
description: "System load is high for more than 10 minutes.\nCurrent load per CPU: {{ $value }}"
# 노드 디스크 I/O 과부하 알림
- alert: HighDiskIOUsage
expr: rate(node_disk_io_time_seconds_total{device!~"^(dm-|md|loop)[0-9]+"}[5m]) > 0.9 # 디스크 I/O 사용률이 90% 이상
for: 15m # 15분 이상 지속될 경우
labels:
severity: warning
annotations:
summary: "High disk I/O usage (instance {{ $labels.instance }})"
description: "Disk I/O utilization is over 90% for device {{ $labels.device }} for more than 15 minutes.\nCurrent utilization: {{ $value | humanizePercentage }}"
# 네트워크 인터페이스 과부하 알림
- alert: NetworkInterfaceHighTraffic
expr: rate(node_network_transmit_bytes_total{device!~"lo|veth.*|docker.*|flannel.*|cali.*|cbr.*"}[5m]) > 75000000 or rate(node_network_receive_bytes_total{device!~"lo|veth.*|docker.*|flannel.*|cali.*|cbr.*"}[5m]) > 75000000 # 75MB/s 이상 트래픽
for: 15m
labels:
severity: warning
annotations:
summary: "High network traffic (instance {{ $labels.instance }})"
description: "Network interface {{ $labels.device }} is experiencing high traffic for more than 15 minutes.\nCurrent rate: {{ $value | humanize }}B/s"
✅ 알림 임계값 결정 방법
적절한 알림 임계값을 결정하는 것은 매우 중요합니다. 다음은 임계값을 결정하는 접근 방식입니다:
- 베이스라인 분석:
- 2-3주 동안 정상 상태의 시스템 데이터 수집
- 일별, 주별 패턴 파악
- 최대값, 최소값, 평균값, 백분위수 계산
- 임계값 유형:
- 정적 임계값: 고정된 값 (예: CPU 사용률 > 90%)
- 동적 임계값: 베이스라인 대비 변화량 (예: 평균보다 3 표준편차 이상)
- 조정 전략:
- 처음에는 보수적으로 설정 (과알림 방지)
- 실제 알림 패턴에 따라 점진적으로 조정
- 과거 장애 데이터 분석을 통한 검증
▶️ 실제 사례: 한 기업에서는 처음에 CPU 알림 임계값을 80%로 설정했으나, 많은 오탐으로 인해 95%로 올리고 지속 시간을 5분에서 15분으로 늘렸습니다. 그 결과 중요 알림만 받을 수 있게 되었습니다.
📌 노드 성능 문제 트러블슈팅
실제 환경에서 발생할 수 있는 노드 성능 문제와 트러블슈팅 방법을 살펴보겠습니다:
✅ 일반적인 노드 문제 및 원인
문제 유형 가능한 원인 관련 메트릭
| 높은 CPU 사용률 | 과도한 워크로드, 리소스 제한 미설정, 시스템 프로세스 | node_cpu_seconds_total, node_load1 |
| 메모리 부족 | 메모리 누수, 캐시 증가, 과도한 컨테이너 할당 | node_memory_MemAvailable_bytes, node_memory_MemFree_bytes |
| 디스크 공간 부족 | 로그 누적, 임시 파일, 오래된 컨테이너 이미지 | node_filesystem_free_bytes |
| 네트워크 병목 | 과도한 트래픽, 네트워크 구성 문제 | node_network_receive_bytes_total, node_network_transmit_bytes_total |
✅ 노드 문제 진단을 위한 추가 명령어
노드 성능 문제를 진단하기 위한 유용한 쿠버네티스 및 리눅스 명령어:
# 노드 상세 정보 확인
# kubectl describe node [node-name]
# 주요 확인 사항:
# - 노드 상태 (Conditions)
# - 할당된 리소스 (Allocated resources)
# - 이벤트 로그 (Events)
# - 테인트 및 레이블 (Taints, Labels)
kubectl describe node worker-1
# 노드의 파드 목록 확인
# 리소스 사용량이 많은 파드를 찾는 데 유용
# -o wide 옵션으로 상세 정보 확인 가능
kubectl get pods --all-namespaces -o wide --field-selector spec.nodeName=worker-1
# 특정 파드의 리소스 사용량 확인
# top 명령어로 실시간 리소스 사용량 모니터링
# CPU 및 메모리 사용량 정렬 가능
kubectl top pod -n [namespace] --sort-by=cpu
kubectl top pod -n [namespace] --sort-by=memory
노드에 직접 접속하여 사용할 수 있는 리눅스 명령어:
# 시스템 리소스 사용량 실시간 모니터링
# 프로세스별 CPU, 메모리 사용량 확인 가능
# 정렬 옵션: P(CPU), M(메모리), T(시간)
top
# 메모리 세부 정보 확인
# 전체 메모리, 사용 중인 메모리, 버퍼/캐시 확인
# -h 옵션으로 읽기 쉬운 형식으로 표시
free -h
# 디스크 사용량 확인
# -h: 읽기 쉬운 형식
# --max-depth=1: 최상위 디렉토리만 표시
df -h
du -h --max-depth=1 /var/log
# 디스크 I/O 모니터링
# -d: 초 단위 업데이트 간격
# -x: 특정 장치 제외
iostat -d 5
# 네트워크 연결 및 소켓 상태 확인
# -t: TCP 연결 표시
# -u: UDP 연결 표시
# -n: 호스트/포트를 숫자로 표시
netstat -tunapl
✅ 성능 문제 해결 단계
노드 성능 문제를 해결하기 위한 체계적인 접근 방법:
- 문제 식별:
- Prometheus 알림 또는 Grafana 대시보드 모니터링
- kubectl describe node 및 kubectl top 명령어 사용
- 노드 상태 및 이벤트 로그 확인
- 원인 분석:
- 과도한 리소스를 사용하는 파드/프로세스 식별
- 시스템 로그 확인 (/var/log/syslog, journalctl)
- 리소스 제한 및 요청 설정 검토
- 조치 적용:
- 문제가 되는 워크로드 제한 또는 재배치
- 리소스 요청 및 제한 조정
- 불필요한 파일/로그 정리
- 노드 재부팅 또는 교체 (최후의 수단)
- 모니터링 및 검증:
- 조치 후 성능 메트릭 지속적 모니터링
- 알림 임계값 재평가
- 재발 방지 전략 수립
▶️ 사례 연구: 어느 클러스터에서는 특정 노드의 디스크 I/O가 급증하는 문제가 발생했습니다. Prometheus 데이터 분석 결과, 로깅 에이전트가 과도하게 로그를 수집하고 있었습니다. 로깅 구성을 최적화하고 로그 로테이션 정책을 조정함으로써 문제를 해결했습니다.
📌 노드 모니터링 모범 사례
효과적인 노드 모니터링을 위한 모범 사례를 알아보겠습니다:
✅ 계층적 모니터링 접근법
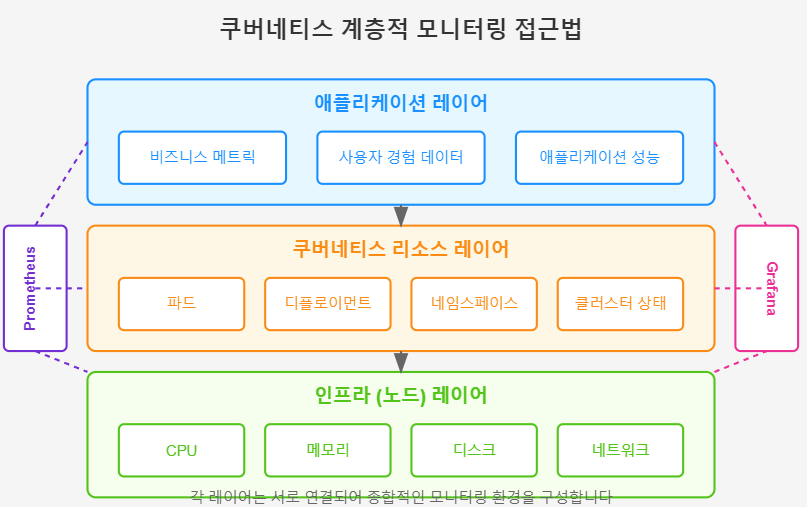
- 인프라 레이어 (노드):
- 하드웨어 및 OS 메트릭 모니터링
- Node Exporter 메트릭 활용
- 호스트 수준의 알림 설정
- 쿠버네티스 레이어:
- kubelet, kube-proxy 메트릭
- 컨테이너 런타임 메트릭
- 클러스터 구성요소 상태
- 애플리케이션 레이어:
- 워크로드별 성능 메트릭
- 비즈니스 KPI와 연계된 메트릭
- 사용자 경험 지표
✅ 골든 시그널 모니터링 접근법
구글의 SRE 모델에서 제시하는 '4대 골든 시그널'을 노드 모니터링에 적용:
- 지연시간 (Latency):
- 디스크 I/O 응답 시간
- 네트워크 지연 시간
- 시스템 처리 시간
- 트래픽 (Traffic):
- 네트워크 인/아웃바운드 트래픽
- 디스크 읽기/쓰기 작업 수
- 시스템 호출 빈도
- 오류 (Errors):
- 시스템 오류 로그
- 커널 이벤트
- 디스크/메모리 오류
- 포화도 (Saturation):
- CPU 사용률
- 메모리 사용률
- 디스크 공간 사용률
- 네트워크 대역폭 사용률
✅ 효과적인 알림 전략
알림 피로(Alert Fatigue)를 방지하고 효과적인 알림 시스템을 구축하기 위한 전략:
- 알림 우선순위 지정:
- Critical: 즉시 대응 필요 (예: 노드 다운)
- Warning: 계획된 대응 필요 (예: 디스크 70% 사용)
- Info: 참고용 정보 (예: 정기 유지보수 필요)
- 알림 그룹화 및 중복 제거:
- 관련 알림 통합
- 반복 알림 억제
- 시간 기반 그룹화
- 컨텍스트 정보 제공:
- 알림 설명에 진단 정보 포함
- 즉시 확인할 수 있는 대시보드 링크 제공
- 해결 가이드라인 또는 런북 참조
- 알림 검토 및 개선:
- 정기적인 알림 효과성 검토
- 오탐(False Positive) 분석
- 놓친 문제(False Negative) 식별 및 개선
📌 Summary
이번 포스트에서는 쿠버네티스 클러스터의 노드 리소스 모니터링에 대해 자세히 알아보았습니다:
- ✅ 노드 모니터링의 중요성과 주요 메트릭
- ✅ Node Exporter의 이해와 구성 방법
- ✅ PromQL을 활용한 노드 상태 분석
- ✅ 효과적인 대시보드 구성 방법
- ✅ 알림 규칙 설정 및 임계값 결정 전략
- ✅ 노드 성능 문제 트러블슈팅
- ✅ 노드 모니터링 모범 사례
쿠버네티스 클러스터의 안정적인 운영을 위해서는 노드 레벨 모니터링이 필수적입니다. 효과적인 노드 모니터링을 통해 문제를 사전에 감지하고, 리소스 사용을 최적화하며, 클러스터의 전반적인 건강 상태를 유지할 수 있습니다.
#Kubernetes #Prometheus #Grafana #모니터링 #DevOps