시리즈 1에서 Observability의 개념과 핵심 요소들에 대해 살펴보았습니다. 이제 시리즈 2에서는 Observability를 기반으로 한 실제 기술 구현과 운영 전략에 초점을 맞추겠습니다. 첫 번째 주제로 효과적인 트래픽 관리와 단일 장애점(SPOF, Single Point of Failure) 해결 전략에 대해 알아보겠습니다.
📌 트래픽 관리의 중요성과 도전 과제
현대적인 시스템에서 효과적인 트래픽 관리는 서비스 안정성과 사용자 경험에 직접적인 영향을 미칩니다. 트래픽 관리는 단순히 부하 분산 이상의 의미를 갖고 있으며, 시스템 복원력의 핵심 요소입니다.
✅ 트래픽 관리의 주요 목표
효과적인 트래픽 관리 시스템이 달성해야 할 주요 목표는 다음과 같습니다:
▶️ 고가용성 확보
- 시스템 장애 발생 시에도 서비스 지속 보장
- 계획된 유지보수 작업 중 서비스 중단 최소화
- 재해 상황에서의 신속한 복구 지원
▶️ 부하 분산 최적화
- 서버 및 서비스 간의 균등한 부하 분배
- 리소스 사용률 극대화
- 특정 구성 요소의 과부하 방지
▶️ 트래픽 라우팅 제어
- 트래픽의 동적 라우팅 및 제어
- 서비스 품질(QoS) 관리
- A/B 테스트, 카나리 배포 등의 고급 배포 전략 지원
▶️ 성능 최적화
- 지리적으로 분산된 사용자에게 최적의 경로 제공
- 지연 시간 최소화
- 대역폭 효율성 향상
✅ 트래픽 관리의 도전 과제
효과적인 트래픽 관리 구현 시 다음과 같은 도전 과제가 있습니다:
▶️ 복잡성 증가
- 분산 시스템의 복잡한 아키텍처
- 다양한 서비스 간의 상호 의존성
- 멀티 클라우드 및 하이브리드 환경
▶️ 가변적인 트래픽 패턴
- 예측 불가능한 트래픽 스파이크
- 계절적/이벤트성 트래픽 변동
- 날짜/시간에 따른 사용 패턴 변화
▶️ 보안 위협
- DDoS 공격
- 악의적인 트래픽
- API 남용
▶️ 리소스 제약
- 네트워크 대역폭 한계
- 서버 용량 제한
- 비용 효율성 요구사항

📌 단일 장애점(SPOF)의 이해와 식별
단일 장애점은 해당 구성 요소가 실패할 경우 전체 시스템이 중단되는 아키텍처의 요소를 의미합니다. 효과적인 Observability는 이러한 SPOF를 식별하고 모니터링하는 데 핵심적인 역할을 합니다.
✅ 일반적인 단일 장애점 유형
시스템에서 흔히 발견되는 단일 장애점 유형은 다음과 같습니다:
▶️ 인프라 관련 SPOF
- 단일 로드 밸런서
- 단일 네트워크 링크/라우터
- 단일 전원 공급 장치
- 단일 데이터 센터/가용 영역
▶️ 애플리케이션 관련 SPOF
- 단일 데이터베이스 인스턴스
- 단일 캐시 서버
- 단일 API 게이트웨이
- 단일 인증 서비스
▶️ 운영 관련 SPOF
- 특정 인력에 대한 과도한 의존성
- 단일 배포 파이프라인
- 단일 모니터링 시스템
- 제한된 운영 문서
✅ Observability를 통한 SPOF 식별
Observability 도구를 활용하여 SPOF를 식별하는 방법:
▶️ 의존성 매핑
- 서비스 간 호출 패턴 분석
- 분산 트레이싱을 통한 서비스 그래프 생성
- 중앙 집중식 서비스 식별
# OpenTelemetry를 활용한 서비스 의존성 분석 예시 코드
def analyze_service_dependencies(traces_data, time_window):
"""
분산 트레이싱 데이터를 분석하여 서비스 의존성 맵을 생성하고 SPOF 후보를 식별
Args:
traces_data: 수집된 트레이스 데이터 - OpenTelemetry 또는 Jaeger 등에서 수집된 트레이스 정보
time_window: 분석 시간 범위 - 예: '24h', '7d' 등 분석할 기간
Returns:
dictionary: {
'dependency_map': 서비스 간 의존성 맵,
'potential_spofs': 잠재적 SPOF 목록
}
"""
# defaultdict를 사용하여 서비스 간 호출 빈도를 계산하기 위한 카운터 초기화
service_calls = defaultdict(int)
# 모든 트레이스를 반복하여 서비스 간 호출 패턴 추출
for trace in traces_data:
# 각 트레이스의 모든 스팬(span)을 분석
for span in trace.spans:
# 부모-자식 관계가 있는 스팬에서 서비스 간 호출 관계 추출
if span.parent_service and span.service:
# (호출자, 피호출자) 튜플을 키로 사용하여 호출 횟수 증가
service_calls[(span.parent_service, span.service)] += 1
# NetworkX 라이브러리를 사용하여 방향성 그래프(DiGraph) 구성
# 이 그래프는 서비스 간 호출 관계를 나타냄
G = nx.DiGraph()
# 추출된 서비스 호출 관계를 그래프에 추가
# weight 속성은 호출 빈도를 나타냄
for (source, target), weight in service_calls.items():
G.add_edge(source, target, weight=weight)
# 중심성(centrality) 계산
# in-degree centrality는 해당 노드로 들어오는 간선의 수를 기준으로 중요도 계산
# 많은 서비스가 의존하는 서비스일수록 높은 중심성 값을 가짐
centrality = nx.in_degree_centrality(G)
# 잠재적 SPOF 찾기 - 상위 10% 중앙 서비스 식별
# 중심성 값의 90번째 백분위수를 임계값으로 사용
threshold = np.percentile(list(centrality.values()), 90)
# 임계값 이상의 중심성을 가진 서비스를 잠재적 SPOF로 식별
potential_spofs = {
service: centrality[service] # 서비스 이름과 해당 중심성 값을 함께 저장
for service in centrality
if centrality[service] >= threshold
}
# 결과 반환 - 의존성 맵과 잠재적 SPOF 목록
return {
'dependency_map': dict(service_calls), # 서비스 간 호출 관계와 빈도
'potential_spofs': potential_spofs # 잠재적 SPOF 목록과 중심성 값
}
▶️ 장애 영향 분석
- 과거 장애 데이터 검토
- 장애 상관관계 분석
- 병목 현상 식별
▶️ 부하 테스트 및 카오스 공학
- 시뮬레이션된 부하 조건에서 시스템 동작 관찰
- 의도적인 장애 주입을 통한 복원력 테스트
- 서비스 성능 저하의 영향 분석
# Chaos Mesh를 활용한 네트워크 지연 주입 예시 (쿠버네티스)
apiVersion: chaos-mesh.org/v1alpha1 # Chaos Mesh API 버전
kind: NetworkChaos # 네트워크 카오스 실험 타입 정의
metadata:
name: network-delay-demo # 실험 이름
namespace: chaos-testing # 실험이 실행될 네임스페이스
spec:
action: delay # 액션 타입: 네트워크 지연 주입
mode: one # 모드: 선택된 파드 중 하나에만 적용
selector: # 실험 대상 선택 기준
namespaces:
- default # default 네임스페이스에서 선택
labelSelectors:
"app": "api-gateway" # 'app=api-gateway' 레이블을 가진 파드 대상
delay:
latency: "200ms" # 주입할 지연 시간: 200 밀리초
correlation: "25" # 상관관계: 25%의 패킷에 지연 적용
jitter: "50ms" # 지연 변동폭: 지연 시간이 ±50ms 내에서 변동
duration: "30m" # 실험 지속 시간: 30분
scheduler:
cron: "@every 60m" # 스케줄링: 1시간마다 반복 실행
# 이 설정으로 1시간마다 30분 동안 API 게이트웨이에 네트워크 지연을 주입
# 이를 통해 네트워크 지연 상황에서 시스템의 복원력을 테스트

📌 효과적인 트래픽 관리 전략
트래픽을 효과적으로 관리하고 단일 장애점 문제를 해결하기 위한 주요 전략들을 살펴보겠습니다.
✅ 다중화 및 중복성 구현
시스템의 중요 구성 요소에 다중화 전략을 적용하여 SPOF를 제거합니다:
▶️ 로드 밸런서 다중화
- 액티브-패시브 또는 액티브-액티브 로드 밸런서 구성
- DNS 라운드 로빈을 통한 여러 로드 밸런서 활용
- 글로벌/지역별 로드 밸런싱 계층 구현
# NGINX를 활용한 다중 업스트림 서버 구성 예시
http {
# 업스트림 서버 그룹 정의 - 백엔드 서버 풀 구성
upstream backend_servers {
# 부하 분산 알고리즘: least_conn (최소 연결 우선)
# 현재 활성 연결이 가장 적은 서버로 새 요청을 라우팅
least_conn;
# 주 서버들 정의 및 장애 감지 설정
# max_fails: 서버가 응답하지 않는 최대 횟수 (3회 실패 시 비정상으로 간주)
# fail_timeout: 비정상 상태로 간주되는 기간 (30초 동안 서비스에서 제외)
server backend1.example.com:8080 max_fails=3 fail_timeout=30s;
server backend2.example.com:8080 max_fails=3 fail_timeout=30s;
server backend3.example.com:8080 max_fails=3 fail_timeout=30s;
# 백업 서버들 - 주 서버가 모두 실패할 경우에만 사용
# backup 파라미터: 이 서버는 기본 서버가 모두 사용 불가능할 때만 사용됨
server backup1.example.com:8080 backup;
server backup2.example.com:8080 backup;
# 서버 헬스 체크 및 연결 관리 최적화
# keepalive: 서버당 유지할 최대 유휴 keepalive 연결 수
# 연결 재사용으로 성능 향상 및 리소스 절약
keepalive 32;
}
# 서버 블록 - 가상 호스트 설정
server {
listen 80; # 80 포트로 HTTP 요청 수신
server_name api.example.com; # 도메인 이름
# 기본 위치 설정
location / {
# 모든 요청을 백엔드 서버 그룹으로 프록시
proxy_pass http://backend_servers;
# 요청 헤더 설정 (원본 요청 정보 전달)
proxy_set_header Host $host; # 원본 호스트 헤더 전달
proxy_set_header X-Real-IP $remote_addr; # 클라이언트 IP 전달
# 다양한 타임아웃 설정으로 안정성 확보
proxy_connect_timeout 5s; # 백엔드 연결 타임아웃
proxy_send_timeout 10s; # 요청 전송 타임아웃
proxy_read_timeout 10s; # 응답 수신 타임아웃
# 오류 처리 - 특정 오류 발생 시 다음 서버로 요청 재전송
# error: 연결 오류, timeout: 타임아웃, http_500: 500 오류 등
# 이를 통해 백엔드 서버 장애 시 자동으로 다른 서버로 요청 전환
proxy_next_upstream error timeout http_500 http_502 http_503 http_504;
}
}
}
▶️ 데이터 스토리지 복제
- 데이터베이스 복제 및 클러스터링
- 지리적으로 분산된 복제본
- 다중 스토리지 계층(캐시, 핫/웜/콜드 스토리지)
# MongoDB 레플리카 셋 구성 예시
replication:
# 레플리카 셋 이름 - 이 이름으로 그룹화된 서버들이 하나의 복제 그룹을 형성
replSetName: "rs0"
# 작업 로그(oplog) 크기 설정 - 2GB
# oplog는 프라이머리 노드의 모든 쓰기 작업을 기록하는 로그로,
# 세컨더리 노드가 프라이머리 노드와 동기화하는 데 사용됨
oplogSizeMB: 2048
# 노드별 구성 파일 설정
# 아래는 프라이머리 노드 설정 예시
# 네트워크 설정
net:
port: 27017 # MongoDB가 수신할 포트
bindIp: 0.0.0.0 # 모든 인터페이스에서 연결 수락 (실제 배포 시에는 보안을 위해 제한적으로 설정)
# 보안 설정
security:
# keyFile을 통한 내부 인증 - 레플리카 셋 멤버 간 인증에 사용
keyFile: /etc/mongodb/keyfile
# 인증 활성화 - 모든 연결에 인증 필요
authorization: enabled
# 복제 관련 추가 설정
replication:
# 과반수 읽기 관심사 활성화 - 데이터 일관성 강화를 위한 설정
# true로 설정 시 대부분의 복제본에 데이터가 기록된 후에만 읽기 작업 수행
enableMajorityReadConcern: true
# Secondary 노드들은 동일한 구성으로 다른 서버에 배포
# 실제 레플리카 셋 초기화 명령어 (MongoDB 셸에서 실행)
# rs.initiate() - 레플리카 셋 초기화
# rs.add("secondary1:27017") - 세컨더리 노드 추가
# rs.add("secondary2:27017") - 추가 세컨더리 노드 추가
▶️ 애플리케이션 서비스 다중화
- 스테이트리스(Stateless) 서비스 설계
- 자동 확장 및 축소
- 지역적으로 분산된 배포
# 쿠버네티스 애플리케이션 다중화 배포 예시
apiVersion: apps/v1 # Kubernetes API 버전
kind: Deployment # 리소스 타입: Deployment (레플리카 관리)
metadata:
name: api-service # 배포 이름
namespace: production # 네임스페이스: 프로덕션 환경
spec:
# 복제본 수: 5개의 동일한 파드(Pod) 실행
# 이를 통해 부하 분산 및 고가용성 확보
replicas: 5
# 롤링 업데이트 전략 - 무중단 배포를 위한 설정
strategy:
type: RollingUpdate # 전략 유형: 롤링 업데이트 (점진적 교체)
rollingUpdate:
maxSurge: 1 # 목표 복제본 수 이상으로 생성 가능한 최대 파드 수
maxUnavailable: 1 # 업데이트 중 사용 불가능한 상태가 될 수 있는 최대 파드 수
# 파드 선택기 - 이 배포가 관리할 파드 지정
selector:
matchLabels:
app: api-service # 'app=api-service' 레이블을 가진 파드 관리
# 파드 템플릿 - 생성될 파드의 명세
template:
metadata:
labels:
app: api-service # 파드에 적용할 레이블
spec:
# 파드 안티-어피니티 설정 - 다른 노드에 파드 분산 배치
# 이를 통해 단일 노드 장애 시 전체 서비스 영향 최소화
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100 # 우선순위 가중치
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- api-service # 같은 앱의 파드는 서로 다른 노드에 배치 선호
topologyKey: "kubernetes.io/hostname" # 노드 호스트 이름 기준으로 분산
# 컨테이너 명세
containers:
- name: api-service
image: example/api-service:v1.2.3 # 사용할 이미지
ports:
- containerPort: 8080 # 컨테이너가 노출할 포트
# 리소스 요청 및 제한 설정
# 요청(requests): 파드 스케줄링을 위한 최소 필요 리소스
# 제한(limits): 파드가 사용할 수 있는 최대 리소스
resources:
requests:
cpu: "100m" # 0.1 코어 요청
memory: "256Mi" # 256MB 메모리 요청
limits:
cpu: "500m" # 최대 0.5 코어 사용 가능
memory: "512Mi" # 최대 512MB 메모리 사용 가능
# 활성 프로브(Liveness Probe) - 컨테이너 정상 작동 확인
# 실패 시 컨테이너를 재시작하여 자가 복구
livenessProbe:
httpGet:
path: /health # 헬스 체크 엔드포인트
port: 8080 # 체크할 포트
initialDelaySeconds: 30 # 첫 체크까지 대기 시간
periodSeconds: 10 # 체크 간격
# 준비 프로브(Readiness Probe) - 트래픽 수신 준비 확인
# 실패 시 해당 파드로 트래픽 전달 중단
readinessProbe:
httpGet:
path: /ready # 준비 상태 체크 엔드포인트
port: 8080 # 체크할 포트
initialDelaySeconds: 5 # 첫 체크까지 대기 시간
periodSeconds: 5 # 체크 간격
✅ 인텔리전트 로드 밸런싱
로드 밸런싱은 트래픽 관리의 핵심 구성 요소로, 다양한 전략과 구현이 있습니다:
▶️ 로드 밸런싱 알고리즘
- 라운드 로빈(Round Robin): 순차적으로 요청 분배
- 최소 연결(Least Connection): 활성 연결이 가장 적은 서버로 라우팅
- 가중치 기반(Weighted): 서버 용량에 따른 비율 배분
- 응답 시간 기반: 가장 빠르게 응답하는 서버 우선
- IP 해시(IP Hash): 클라이언트 IP 기반 일관된 라우팅
▶️ 고급 로드 밸런싱 기법
- 콘텐츠 기반 라우팅: 요청 내용에 따른 라우팅
- 지역 기반 라우팅: 사용자 위치에 가까운 서버로 라우팅
- 세션 어피니티(Sticky Sessions): 사용자 세션을 같은 서버로 유지
- 서비스 상태 기반 라우팅: 헬스 체크 결과에 따른 트래픽 조절
# AWS Application Load Balancer 구성 예시 (Terraform)
resource "aws_lb" "api_gateway" {
name = "api-gateway-lb" # 로드 밸런서 이름
internal = false # 외부 로드 밸런서 (인터넷 연결)
load_balancer_type = "application" # 로드 밸런서 유형: 애플리케이션 (L7)
security_groups = [aws_security_group.lb_sg.id] # 적용할 보안 그룹
# 로드 밸런서를 배치할 서브넷 (여러 가용 영역에 분산)
subnets = [aws_subnet.public_a.id, aws_subnet.public_b.id, aws_subnet.public_c.id]
# 교차 영역 로드 밸런싱 활성화 - 모든 가용 영역에 균등하게 트래픽 분배
# 이를 통해 특정 가용 영역에 트래픽이 집중되는 것을 방지
enable_cross_zone_load_balancing = true
# 아이들 타임아웃 설정 - 연결 유지 시간 (초)
# 60초 동안 요청이 없으면 연결 종료
idle_timeout = 60
# 액세스 로그 설정 - 디버깅 및 분석용
access_logs {
bucket = aws_s3_bucket.lb_logs.bucket # 로그를 저장할 S3 버킷
prefix = "api-gateway" # 로그 파일 접두사
enabled = true # 로깅 활성화
}
# 태그 설정 - 리소스 관리 및 비용 추적용
tags = {
Environment = "production"
}
}
# 대상 그룹 설정 - 요청을 라우팅할 백엔드 서버 그룹
resource "aws_lb_target_group" "api_gateway" {
name = "api-gateway-tg" # 대상 그룹 이름
port = 80 # 대상 포트
protocol = "HTTP" # 대상 프로토콜
vpc_id = aws_vpc.main.id # VPC ID
# 대상 유형 - 인스턴스, IP, Lambda 등
# instance: EC2 인스턴스를 대상으로 지정
target_type = "instance"
# 헬스 체크 설정 - 대상 서버 상태 확인
health_check {
enabled = true # 헬스 체크 활성화
interval = 30 # 체크 간격 (초)
path = "/health" # 체크 경로
port = "traffic-port" # 체크 포트 (트래픽 포트와 동일)
protocol = "HTTP" # 체크 프로토콜
timeout = 5 # 응답 타임아웃 (초)
healthy_threshold = 3 # 정상으로 간주할 연속 성공 횟수
unhealthy_threshold = 3 # 비정상으로 간주할 연속 실패 횟수
matcher = "200" # 정상 응답 코드
}
# 스티키 세션 설정 - 세션 고정성 제공
# 같은 사용자의 요청을 항상 같은 대상으로 라우팅
stickiness {
type = "lb_cookie" # 쿠키 기반 스티키 세션
cookie_duration = 86400 # 쿠키 유효 기간 (초, 24시간)
enabled = true # 스티키 세션 활성화
}
}
# 리스너 규칙 - 경로 기반 라우팅 설정
resource "aws_lb_listener_rule" "api_gateway" {
listener_arn = aws_lb_listener.api_gateway.arn # 적용할 리스너 ARN
priority = 100 # 규칙 우선순위 (낮은 숫자가 높은 우선순위)
# 액션 정의 - 요청 처리 방식
action {
type = "forward" # 전달 타입
target_group_arn = aws_lb_target_group.api_gateway.arn # 대상 그룹 ARN
}
# 조건 정의 - 이 규칙이 적용될 요청 조건
condition {
path_pattern {
values = ["/api/*"] # 경로 패턴: /api/로 시작하는 모든 요청에 적용
}
}
}
▶️ 다계층 로드 밸런싱
- 글로벌 DNS 기반 로드 밸런싱
- 지역별 로드 밸런서
- 서비스별 로드 밸런서

✅ 서킷 브레이커 패턴
서킷 브레이커 패턴은 장애 전파를 방지하고 시스템 안정성을 유지하는데 중요한 역할을 합니다:
▶️ 서킷 브레이커의 원리
- 닫힘(Closed): 정상 상태, 요청이 대상 서비스로 통과
- 열림(Open): 장애 상태, 요청이 즉시 실패하고 대상 서비스로 전달되지 않음
- 반열림(Half-Open): 회복 테스트 상태, 제한된 요청만 대상 서비스로 전달
// Java Spring Cloud Circuit Breaker 구현 예시
@Service
public class PaymentService {
private final RestTemplate restTemplate;
private final CircuitBreakerFactory circuitBreakerFactory;
// 생성자 주입을 통한 의존성 주입
public PaymentService(RestTemplate restTemplate, CircuitBreakerFactory circuitBreakerFactory) {
this.restTemplate = restTemplate; // HTTP 요청을 위한 RestTemplate
this.circuitBreakerFactory = circuitBreakerFactory; // 서킷 브레이커 팩토리
}
public PaymentResponse processPayment(PaymentRequest request) {
// 서킷 브레이커 생성 및 구성
// "payment-service"라는 이름으로 서킷 브레이커 인스턴스 생성
// 이름별로 다른 구성을 적용할 수 있음
CircuitBreaker circuitBreaker = circuitBreakerFactory.create("payment-service");
// 서킷 브레이커로 보호된 메서드 호출
return circuitBreaker.run(
// 주요 로직 - 결제 처리 API 호출
// 이 부분이 실패하면 서킷 브레이커가 개입
() -> restTemplate.postForObject("https://payment-provider/api/payments",
request,
PaymentResponse.class),
// 폴백 로직 (서킷이 열렸거나 호출이 실패한 경우 실행)
// 오류 발생 시 대체 응답 또는 대체 동작 제공
throwable -> handlePaymentFailure(request, throwable)
);
}
// 결제 실패 처리 메서드 - 폴백 로직 구현
private PaymentResponse handlePaymentFailure(PaymentRequest request, Throwable throwable) {
// 로깅 - 장애 상황 기록
log.error("Payment service unavailable. Error: {}", throwable.getMessage());
// 메트릭 기록 - 모니터링 및 알림용
meterRegistry.counter("payment.failures",
"reason", throwable.getClass().getSimpleName())
.increment();
// 요청 중요도에 따른 차별화된 폴백 전략
if (request.isNonCritical()) {
// 비중요 지불은 나중에 재시도하도록 대기열에 추가
paymentRetryQueue.enqueue(request);
return new PaymentResponse(PaymentStatus.PENDING, "Payment queued for retry");
} else {
// 중요 지불은 대체 제공자 시도 (이중화 전략)
try {
// 백업 결제 서비스로 시도
return backupPaymentProvider.processPayment(request);
} catch (Exception e) {
// 모든 시도 실패 시 최종 폴백 응답
return new PaymentResponse(PaymentStatus.FAILED, "All payment attempts failed");
}
}
}
}
// 서킷 브레이커 구성 클래스
@Configuration
public class CircuitBreakerConfig {
@Bean
public Customizer<Resilience4JCircuitBreakerFactory> defaultCircuitBreakerCustomizer() {
return factory -> factory.configureDefault(id -> new Resilience4JConfigBuilder(id)
.circuitBreakerConfig(CircuitBreakerConfig.custom()
// 실패율 임계값 - 50% 이상 실패 시 서킷 열림
.failureRateThreshold(50)
// 슬라이딩 윈도우 크기 - 최근 20개 요청을 기준으로 실패율 계산
.slidingWindowSize(20)
// 최소 호출 수 - 최소 5개 이상의 요청이 있어야 실패율 계산
.minimumNumberOfCalls(5)
// 대기 시간 - 서킷이 열린 후 30초 대기
.waitDurationInOpenState(Duration.ofSeconds(30))
// 반열림 상태에서 허용할 호출 수 - 회복 테스트용
.permittedNumberOfCallsInHalfOpenState(3)
// 슬라이딩 윈도우 유형 - 요청 수 기반 또는 시간 기반
.slidingWindowType(CircuitBreakerConfig.SlidingWindowType.COUNT_BASED)
.build())
.timeLimiterConfig(TimeLimiterConfig.custom()
// 타임아웃 - 2초 내에 응답이 없으면 실패로 처리
.timeoutDuration(Duration.ofSeconds(2))
.build())
.build());
}
}
▶️ 서킷 브레이커 구현 전략
- 세분화된 서킷: 각 종속성에 대해 별도의 서킷 브레이커 구성
- 맥락 인식 서킷: 요청 유형이나 중요도에 따라 다른 정책 적용
- 적응형 임계값: 트래픽 패턴에 따라 동적으로 임계값 조정
▶️ 서킷 브레이커 모니터링
- 실패율 및 성공률 추적
- 서킷 상태 변경 모니터링
- 폴백 호출 빈도 분석
✅ 레이트 리미팅 및 트래픽 쉐이핑
트래픽 제어 메커니즘은 과부하를 방지하고 시스템 안정성을 유지하는 데 중요합니다:
▶️ 레이트 리미팅 전략
- 고정 윈도우: 일정 시간 간격당 요청 수 제한
- 슬라이딩 윈도우: 연속적인 시간 간격에 걸쳐 요청 수 제한
- 토큰 버킷: 일정 속도로 토큰을 생성하고 각 요청에 토큰 소비
- 리키 버킷(Leaky Bucket): 일정 속도로 요청 처리
// Go 언어를 사용한 토큰 버킷 레이트 리미터 구현 예시
package main
import (
"fmt"
"time"
"sync"
"net/http"
"golang.org/x/time/rate"
)
// 사용자별 레이트 리미터 관리 구조체
type UserRateLimiter struct {
limiters map[string]*rate.Limiter // 사용자 ID를 키로 한 리미터 맵
mu sync.Mutex // 동시성 제어를 위한 뮤텍스
rate rate.Limit // 기본 레이트 제한 (초당 허용 토큰 수)
burst int // 버스트 크기 (한 번에 처리 가능한 최대 요청 수)
}
// 새 UserRateLimiter 생성 함수
func NewUserRateLimiter(r rate.Limit, b int) *UserRateLimiter {
return &UserRateLimiter{
limiters: make(map[string]*rate.Limiter), // 빈 맵 초기화
rate: r, // 초당 허용 요청 수 설정 (예: 10 = 초당 10개 요청)
burst: b, // 버스트 허용량 설정 (예: 30 = 최대 30개 요청 일시 처리 가능)
}
}
// 사용자에 대한 레이트 리미터 가져오기 (없으면 생성)
func (u *UserRateLimiter) getLimiter(userID string) *rate.Limiter {
u.mu.Lock() // 맵 접근 동기화를 위한 잠금
defer u.mu.Unlock() // 함수 종료 시 잠금 해제
limiter, exists := u.limiters[userID]
if !exists {
// 새 리미터 생성 (사용자 ID별로 별도의 리미터 할당)
// rate: 분당 요청 수 제한, burst: 일시적으로 허용할 초과 요청 수
limiter = rate.NewLimiter(u.rate, u.burst)
u.limiters[userID] = limiter
}
return limiter
}
// 레이트 리미팅 미들웨어 - HTTP 요청에 레이트 제한 적용
func RateLimitMiddleware(limiter *UserRateLimiter) func(http.Handler) http.Handler {
return func(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
// 사용자 ID 추출 (예: API 키 또는 인증 토큰)
userID := extractUserID(r)
// 사용자별 리미터 가져오기
userLimiter := limiter.getLimiter(userID)
// 요청을 허용할지 확인 (토큰 소비 시도)
if !userLimiter.Allow() {
// 레이트 제한 초과 시 429 상태 코드(Too Many Requests) 반환
http.Error(w, "Rate limit exceeded", http.StatusTooManyRequests)
// 메트릭 기록 - 모니터링 및 분석용
recordRateLimitMetric(userID)
return
}
// 레이트 제한 내에서는 다음 핸들러로 요청 전달
next.ServeHTTP(w, r)
})
}
}
func main() {
// 초당 10개 요청, 최대 버스트 30개 요청 허용 리미터 생성
limiter := NewUserRateLimiter(10, 30)
// API 핸들러 설정
apiHandler := http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "API response")
})
// 미들웨어 적용 - 모든 API 요청에 레이트 리미팅 적용
http.Handle("/api/", RateLimitMiddleware(limiter)(apiHandler))
// 서버 시작
http.ListenAndServe(":8080", nil)
}
// 사용자 ID 추출 함수 - 요청에서 사용자 식별 정보 추출
func extractUserID(r *http.Request) string {
// API 키 또는 토큰에서 사용자 ID 추출
// 여기서는 간단히 API 키 헤더 값 사용
return r.Header.Get("X-API-Key")
}
// 메트릭 기록 함수 - 레이트 제한 이벤트 기록
func recordRateLimitMetric(userID string) {
// Prometheus 또는 다른 모니터링 시스템에 메트릭 기록
// 실제 구현은 사용 중인 모니터링 시스템에 따라 달라짐
fmt.Printf("Rate limit exceeded for user: %s\n", userID)
}
▶️ 트래픽 쉐이핑 기법
- 우선순위 큐: 중요한 요청 우선 처리
- 처리량 조절: 서비스 부하에 따른 처리 속도 조절
- 대기열 관리: 요청 버퍼링 및 평탄화
▶️ 고급 트래픽 제어
- 트래픽 분류 및 우선순위 지정
- 조건부 접근 제어
- 점진적 롤아웃 및 A/B 테스트 지원
# API 게이트웨이에서의 트래픽 쉐이핑 및 제어 예시 (Python FastAPI)
from fastapi import FastAPI, Request, Response, Depends, HTTPException
from fastapi.middleware.cors import CORSMiddleware
import time
import asyncio
from dataclasses import dataclass
import redis
import logging
from typing import Optional, Dict, List
# 애플리케이션 초기화
app = FastAPI(title="API Gateway with Traffic Shaping")
# 로깅 설정
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# Redis 클라이언트 초기화 (레이트 리미팅 상태 저장)
redis_client = redis.Redis(host='localhost', port=6379, db=0)
# 서비스 정의 클래스
@dataclass
class ServiceConfig:
name: str # 서비스 이름
base_url: str # 서비스 기본 URL
timeout: float # 요청 타임아웃(초)
rate_limit: int # 분당 최대 요청 수
circuit_threshold: float # 서킷 브레이커 실패율 임계값(%)
priority: int # 서비스 우선순위(낮을수록 높은 우선순위)
max_concurrency: int # 최대 동시 요청 수
# 서비스 구성 (실제로는 구성 파일이나 DB에서 로드)
services = {
"payment": ServiceConfig(
name="payment",
base_url="http://payment-service:8080",
timeout=2.0, # 결제는 빠른 응답이 필요하므로 짧은 타임아웃
rate_limit=100, # 분당 100개 요청 제한
circuit_threshold=10.0, # 10% 실패율에서 서킷 열림
priority=1, # 최고 우선순위
max_concurrency=50 # 동시에 최대 50개 요청 처리
),
"inventory": ServiceConfig(
name="inventory",
base_url="http://inventory-service:8080",
timeout=3.0, # 재고 확인은 약간 더 긴 타임아웃 허용
rate_limit=200, # 분당 200개 요청 제한
circuit_threshold=20.0, # 20% 실패율에서 서킷 열림
priority=2, # 중간 우선순위
max_concurrency=100 # 동시에 최대 100개 요청 처리
),
"user": ServiceConfig(
name="user",
base_url="http://user-service:8080",
timeout=5.0, # 사용자 서비스는 더 긴 타임아웃 허용
rate_limit=300, # 분당 300개 요청 제한
circuit_threshold=30.0, # 30% 실패율에서 서킷 열림
priority=3, # 낮은 우선순위
max_concurrency=150 # 동시에 최대 150개 요청 처리
)
}
# 서비스별 현재 상태 (런타임에 업데이트)
service_states = {
name: {
"circuit_state": "closed", # 초기 서킷 상태는 닫힘(정상)
"failure_count": 0, # 실패 수
"success_count": 0, # 성공 수
"last_failure_time": 0, # 마지막 실패 시간
"current_concurrency": 0 # 현재 동시 처리 중인 요청 수
} for name in services.keys()
}
# 우선순위 기반 요청 대기열
class PriorityRequestQueue:
def __init__(self):
# 우선순위별 대기열 (낮은 숫자가 높은 우선순위)
self.queues: Dict[int, List] = {}
self.lock = asyncio.Lock()
async def put(self, priority: int, task):
"""우선순위 큐에 태스크 추가"""
async with self.lock:
if priority not in self.queues:
self.queues[priority] = []
self.queues[priority].append(task)
async def get(self):
"""가장 높은 우선순위의 태스크 가져오기"""
async with self.lock:
# 우선순위 정렬 (낮은 숫자가 높은 우선순위)
priorities = sorted(self.queues.keys())
for priority in priorities:
if self.queues[priority]:
return self.queues[priority].pop(0)
return None
# 우선순위 큐 인스턴스 생성
request_queue = PriorityRequestQueue()
# 레이트 리미터 미들웨어
@app.middleware("http")
async def rate_limiter_middleware(request: Request, call_next):
"""
사용자/서비스별 레이트 리미팅 처리
- 사용자 식별을 위해 API 키 사용
- Redis를 사용하여 카운터 유지
- 제한 초과 시 429 상태 코드 반환
"""
# 사용자 식별 (API 키 또는 IP 주소)
api_key = request.headers.get("X-API-Key", "anonymous")
client_ip = request.client.host
# 서비스 경로에서 서비스 이름 추출
path = request.url.path
service_name = path.split("/")[1] if len(path.split("/")) > 1 else "default"
# 사용자-서비스 조합에 대한 레이트 리미팅 키
rate_key = f"ratelimit:{api_key}:{service_name}"
# 현재 시간 (분 단위로 반올림)
current_minute = int(time.time() / 60)
# Redis에서 현재 요청 수 가져오기
current_count = redis_client.get(rate_key)
current_count = int(current_count) if current_count else 0
# 서비스 구성에서 한도 가져오기
rate_limit = services.get(service_name, services.get("default", ServiceConfig(
name="default", base_url="", timeout=1.0, rate_limit=50,
circuit_threshold=50.0, priority=10, max_concurrency=20
))).rate_limit
# 레이트 제한 검사
if current_count >= rate_limit:
# 제한 초과 로깅
logger.warning(f"Rate limit exceeded for {api_key} on {service_name}")
# 메트릭 증가
# increment_metric("rate_limit_exceeded", {"service": service_name, "api_key": api_key})
# 429 Too Many Requests 응답
return Response(
content={"error": "Rate limit exceeded. Try again later."},
status_code=429,
media_type="application/json"
)
# Redis에서 카운터 증가
pipeline = redis_client.pipeline()
pipeline.incr(rate_key)
# 키가 없으면 만료 시간 설정 (현재 분이 끝날 때까지)
pipeline.expire(rate_key, 60)
pipeline.execute()
# 다음 미들웨어 또는 라우트 핸들러 호출
response = await call_next(request)
return response
# 서킷 브레이커 미들웨어
@app.middleware("http")
async def circuit_breaker_middleware(request: Request, call_next):
"""
서비스별 서킷 브레이커 패턴 구현
- 서비스 실패율 모니터링
- 임계값 초과 시 서킷 오픈
- 반-열림 상태에서 제한된 요청만 허용
"""
# 요청 경로에서 서비스 이름 추출
path = request.url.path
service_name = path.split("/")[1] if len(path.split("/")) > 1 else "default"
# 서비스 상태 확인
service_state = service_states.get(service_name, {"circuit_state": "closed"})
# 서킷이 열려 있는 경우
if service_state["circuit_state"] == "open":
# 마지막 실패 후 대기 시간 확인 (30초 대기)
if time.time() - service_state["last_failure_time"] > 30:
# 반-열림 상태로 전환
service_state["circuit_state"] = "half-open"
logger.info(f"Circuit for {service_name} changed to half-open")
else:
# 서킷이 열려 있고 대기 시간이 지나지 않은 경우 즉시 실패
logger.warning(f"Circuit open for {service_name}, rejecting request")
return Response(
content={"error": "Service temporarily unavailable"},
status_code=503,
media_type="application/json"
)
# 반-열림 상태에서는 제한된 요청만 허용
if service_state["circuit_state"] == "half-open":
# 10% 확률로만 요청 허용 (테스트용)
if time.time() % 10 != 0:
logger.info(f"Circuit half-open for {service_name}, limiting traffic")
return Response(
content={"error": "Service under recovery, try again later"},
status_code=503,
media_type="application/json"
)
try:
# 다음 미들웨어 또는 라우트 핸들러 호출
response = await call_next(request)
# 성공적인 응답 처리
if response.status_code < 500:
# 성공 카운터 증가
service_state["success_count"] += 1
# 반-열림 상태에서 충분한 성공이 있으면 서킷 닫기
if service_state["circuit_state"] == "half-open" and service_state["success_count"] >= 5:
service_state["circuit_state"] = "closed"
service_state["failure_count"] = 0
logger.info(f"Circuit for {service_name} closed after successful recovery")
else:
# 5xx 응답은 실패로 처리
service_state["failure_count"] += 1
service_state["last_failure_time"] = time.time()
return response
except Exception as e:
# 예외 발생 시 실패 처리
service_state["failure_count"] += 1
service_state["last_failure_time"] = time.time()
# 현재 실패율 계산
total = service_state["success_count"] + service_state["failure_count"]
failure_rate = (service_state["failure_count"] / total * 100) if total > 0 else 0
# 실패율이 임계값을 초과하면 서킷 열기
service_config = services.get(service_name)
if service_config and failure_rate > service_config.circuit_threshold and total >= 10:
service_state["circuit_state"] = "open"
logger.error(f"Circuit for {service_name} opened due to high failure rate: {failure_rate:.1f}%")
# 오류 응답 반환
return Response(
content={"error": f"Service error: {str(e)}"},
status_code=500,
media_type="application/json"
)

📌 지리적 분산 및 다중 리전 아키텍처
지리적으로 분산된 아키텍처는 글로벌 서비스 제공과 재해 복구에 중요합니다.
✅ 지리적 분산 전략
효과적인 지리적 분산을 위한 주요 전략:
▶️ 다중 리전 배포
- 주요 지역별 독립적인 인프라 구축
- 리전 간 데이터 복제 및 동기화
- 리전별 자원 할당 및 확장성 계획
# Terraform을 사용한 다중 리전 인프라 구성 예시
# 주 리전 (us-east-1)과 보조 리전 (eu-west-1) 설정
# 변수 정의
variable "regions" {
description = "AWS regions for deployment"
type = list(string)
default = ["us-east-1", "eu-west-1"] # 주 리전과 보조 리전
}
variable "app_name" {
description = "Application name"
type = string
default = "example-app"
}
# 리전별 프로바이더 설정
provider "aws" {
alias = "us_east_1"
region = "us-east-1"
}
provider "aws" {
alias = "eu_west_1"
region = "eu-west-1"
}
# 리전별 VPC 생성
resource "aws_vpc" "vpc_us_east" {
provider = aws.us_east_1
cidr_block = "10.0.0.0/16" # US East 리전의 IP 주소 범위
tags = {
Name = "${var.app_name}-vpc-us-east"
}
}
resource "aws_vpc" "vpc_eu_west" {
provider = aws.eu_west_1
cidr_block = "10.1.0.0/16" # EU West 리전의 IP 주소 범위 (겹치지 않게 설정)
tags = {
Name = "${var.app_name}-vpc-eu-west"
}
}
# 서브넷 설정 (각 리전에 퍼블릭/프라이빗 서브넷)
# 미국 동부 리전 서브넷
resource "aws_subnet" "us_east_public_a" {
provider = aws.us_east_1
vpc_id = aws_vpc.vpc_us_east.id
cidr_block = "10.0.1.0/24" # 퍼블릭 서브넷 CIDR
availability_zone = "us-east-1a" # us-east-1a 가용 영역
tags = {
Name = "${var.app_name}-us-east-public-a"
}
}
resource "aws_subnet" "us_east_private_a" {
provider = aws.us_east_1
vpc_id = aws_vpc.vpc_us_east.id
cidr_block = "10.0.10.0/24" # 프라이빗 서브넷 CIDR
availability_zone = "us-east-1a" # 동일한 가용 영역에 프라이빗 서브넷
tags = {
Name = "${var.app_name}-us-east-private-a"
}
}
# 유럽 서부 리전 서브넷 (동일한 패턴 반복)
resource "aws_subnet" "eu_west_public_a" {
provider = aws.eu_west_1
vpc_id = aws_vpc.vpc_eu_west.id
cidr_block = "10.1.1.0/24"
availability_zone = "eu-west-1a"
tags = {
Name = "${var.app_name}-eu-west-public-a"
}
}
resource "aws_subnet" "eu_west_private_a" {
provider = aws.eu_west_1
vpc_id = aws_vpc.vpc_eu_west.id
cidr_block = "10.1.10.0/24"
availability_zone = "eu-west-1a"
tags = {
Name = "${var.app_name}-eu-west-private-a"
}
}
# 리전별 로드 밸런서 설정
resource "aws_lb" "lb_us_east" {
provider = aws.us_east_1
name = "${var.app_name}-lb-us-east"
internal = false # 외부 로드 밸런서 (인터넷 연결)
load_balancer_type = "application" # 애플리케이션 로드 밸런서 (L7)
security_groups = [aws_security_group.lb_sg_us_east.id]
subnets = [aws_subnet.us_east_public_a.id, aws_subnet.us_east_public_b.id]
enable_deletion_protection = false # 테스트용으로는 삭제 보호 비활성화
tags = {
Name = "${var.app_name}-lb-us-east"
}
}
resource "aws_lb" "lb_eu_west" {
provider = aws.eu_west_1
name = "${var.app_name}-lb-eu-west"
internal = false
load_balancer_type = "application"
security_groups = [aws_security_group.lb_sg_eu_west.id]
subnets = [aws_subnet.eu_west_public_a.id, aws_subnet.eu_west_public_b.id]
enable_deletion_protection = false
tags = {
Name = "${var.app_name}-lb-eu-west"
}
}
# Route 53 글로벌 로드 밸런싱 설정
resource "aws_route53_zone" "primary" {
name = "example.com" # 도메인 이름
}
# 리전별 로드 밸런서 헬스 체크 설정
resource "aws_route53_health_check" "us_east" {
fqdn = aws_lb.lb_us_east.dns_name # US East 로드 밸런서 도메인
port = 443 # HTTPS 포트
type = "HTTPS" # 체크 타입
resource_path = "/health" # 헬스 체크 경로
failure_threshold = 3 # 실패 임계값
request_interval = 30 # 체크 간격 (초)
tags = {
Name = "${var.app_name}-health-check-us-east"
}
}
resource "aws_route53_health_check" "eu_west" {
fqdn = aws_lb.lb_eu_west.dns_name # EU West 로드 밸런서 도메인
port = 443
type = "HTTPS"
resource_path = "/health"
failure_threshold = 3
request_interval = 30
tags = {
Name = "${var.app_name}-health-check-eu-west"
}
}
# 지연시간 기반 라우팅 정책 - 사용자에게 가장 가까운 리전으로 라우팅
resource "aws_route53_record" "www" {
zone_id = aws_route53_zone.primary.zone_id
name = "www.example.com" # 서비스 도메인
type = "A" # A 레코드 (IPv4 주소로 확인)
latency_routing_policy {
region = "us-east-1" # US East 리전에 대한 정책
}
set_identifier = "us-east-1" # 이 레코드 셋의 식별자
alias {
name = aws_lb.lb_us_east.dns_name # 로드 밸런서 DNS 이름
zone_id = aws_lb.lb_us_east.zone_id # 로드 밸런서 호스팅 영역 ID
evaluate_target_health = true # 대상 상태 평가 활성화
}
health_check_id = aws_route53_health_check.us_east.id # 연결된 헬스 체크
}
resource "aws_route53_record" "www_eu" {
zone_id = aws_route53_zone.primary.zone_id
name = "www.example.com"
type = "A"
latency_routing_policy {
region = "eu-west-1" # EU West 리전에 대한 정책
}
set_identifier = "eu-west-1"
alias {
name = aws_lb.lb_eu_west.dns_name
zone_id = aws_lb.lb_eu_west.zone_id
evaluate_target_health = true
}
health_check_id = aws_route53_health_check.eu_west.id
}
# DynamoDB 글로벌 테이블 구성 - 리전 간 데이터 자동 복제
resource "aws_dynamodb_table" "global_table" {
provider = aws.us_east_1
name = "${var.app_name}-data" # 테이블 이름
billing_mode = "PAY_PER_REQUEST" # 온디맨드 과금 모드
hash_key = "id" # 기본 키
attribute {
name = "id" # 속성 정의
type = "S" # 문자열 타입
}
# 글로벌 테이블 활성화 (v2) - EU West 리전에 자동 복제
replica {
region_name = "eu-west-1" # 복제할 리전
}
tags = {
Name = "${var.app_name}-global-table"
}
}
▶️ 글로벌 로드 밸런싱
- 지연 시간 기반 라우팅
- 지리적 위치 기반 라우팅
- 상태 체크 기반 장애 조치
- 가중치 기반 트래픽 분배
▶️ 콘텐츠 전송 네트워크(CDN) 활용
- 정적 콘텐츠 캐싱 및 전송 최적화
- 엣지 로케이션을 통한 사용자 근접성 향상
- DDoS 보호 및 WAF 통합
✅ 지역 간 데이터 동기화
분산 환경에서 데이터 일관성과 동기화는 중요한 과제입니다:
▶️ 데이터 복제 전략
- 동기식 vs 비동기식 복제
- 다중 마스터 vs 마스터-슬레이브 복제
- 글로벌 테이블 및 멀티 리전 데이터베이스
-- PostgreSQL 논리적 복제 설정 예시 (마스터-슬레이브)
-- 마스터 데이터베이스 설정 (us-east)
-- 1. postgresql.conf 설정
-- wal_level = logical -- 논리적 복제 활성화 (필수)
-- max_wal_senders = 10 -- 최대 WAL 센더 프로세스 수
-- max_replication_slots = 10 -- 최대 복제 슬롯 수
-- 2. pg_hba.conf 설정
-- 복제 연결 허용 (슬레이브 IP가 10.0.2.5라고 가정)
-- host replication replicator 10.0.2.5/32 md5
-- 3. 복제 사용자 생성 - 복제 권한이 있는 특별 사용자
CREATE ROLE replicator WITH REPLICATION LOGIN PASSWORD 'secure_password';
-- 4. 복제할 테이블이 있는 데이터베이스 생성
CREATE DATABASE app_db;
\c app_db
-- 5. 테이블 생성 - 복제할 데이터 테이블 정의
CREATE TABLE users (
id SERIAL PRIMARY KEY, -- 사용자 고유 식별자 (자동 증가)
username VARCHAR(50) NOT NULL, -- 사용자 이름 (필수 입력)
email VARCHAR(100) UNIQUE, -- 이메일 (고유해야 함)
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, -- 생성 시간 (자동 기록)
region VARCHAR(20) -- 사용자의 리전 정보
);
-- 6. 퍼블리케이션 생성 (복제할 테이블 지정)
-- 이 퍼블리케이션은 users 테이블의 변경사항을 발행
CREATE PUBLICATION user_pub FOR TABLE users;
-- 슬레이브 데이터베이스 설정 (eu-west)
-- 1. 데이터베이스 생성 및 스키마 복제
CREATE DATABASE app_db;
\c app_db
-- 2. 동일한 테이블 구조 생성 (스키마만 복제)
CREATE TABLE users (
id SERIAL PRIMARY KEY,
username VARCHAR(50) NOT NULL,
email VARCHAR(100) UNIQUE,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
region VARCHAR(20)
);
-- 3. 구독 생성 (마스터 DB 연결 정보 지정)
-- 이 구독은 마스터의 user_pub 퍼블리케이션을 구독하여 변경사항 수신
CREATE SUBSCRIPTION user_sub
CONNECTION 'host=master-db.us-east.example.com port=5432 dbname=app_db user=replicator password=secure_password'
PUBLICATION user_pub;
-- 4. 복제 상태 확인
-- 복제가 정상적으로 작동하는지 확인하는 쿼리
SELECT * FROM pg_stat_subscription;
-- 참고: 이중 쓰기 설정을 위한 애플리케이션 로직 예시 (Python)
def insert_user(username, email, region):
"""
사용자를 지역별 데이터베이스에 이중 삽입하는 함수
Args:
username: 사용자 이름
email: 이메일
region: 사용자 리전
Returns:
생성된 사용자 ID
"""
# 사용자의 지리적 위치에 가장 가까운 DB 결정
local_db = get_nearest_db(region)
# 로컬 DB에 먼저 삽입 (주 작업)
user_id = local_db.execute("""
INSERT INTO users (username, email, region)
VALUES (%s, %s, %s)
RETURNING id
""", (username, email, region))
# 다른 리전에도 삽입 (비동기적으로 수행하여 성능 영향 최소화)
for db in get_all_region_dbs():
if db != local_db:
# 오류 처리 및 나중에 재시도할 큐에 넣기
try:
db.execute_async("""
INSERT INTO users (id, username, email, region)
VALUES (%s, %s, %s, %s)
ON CONFLICT (id) DO UPDATE
SET username = EXCLUDED.username,
email = EXCLUDED.email,
region = EXCLUDED.region
""", (user_id, username, email, region))
except DatabaseError as e:
# 실패한 작업을 재시도 큐에 추가
retry_queue.put({
"operation": "insert_user",
"params": {
"id": user_id,
"username": username,
"email": email,
"region": region
}
})
log_error(f"Failed to replicate user {user_id} to region {db.region}: {e}")
return user_id
▶️ 충돌 해결 전략
- 타임스탬프 기반 충돌 해결
- 벡터 시계(Vector Clock) 구현
- 마지막 쓰기 우선(Last-Write-Wins)
- 사용자 중재 충돌 해결
▶️ 지연 시간 및 네트워크 최적화
- 데이터 압축 및 배치 처리
- 변경 데이터 캡처(CDC)
- 증분식 데이터 동기화
- 메시지 큐 및 이벤트 버스 활용
✅ 재해 복구 전략
시스템의 재해 복구 능력은 효과적인 Observability와 긴밀하게 연결되어 있습니다:
▶️ 복구 목표 설정
- 복구 시점 목표(RPO): 허용 가능한 데이터 손실 기간
- 복구 시간 목표(RTO): 서비스 복구에 필요한 시간
- 서비스 수준 목표(SLO): 재해 상황에서의 성능 기대치
▶️ 재해 복구 패턴
- 백업 및 복원: 정기적인 백업과 복원 절차
- 파일럿 라이트: 최소한의 인프라만 실행하는 대기 환경
- 웜 스탠바이: 축소된 용량으로 실행 중인 대기 환경
- 핫 스탠바이: 완전한 용량으로 실행 중인 대기 환경
# Kubernetes Operator를 사용한 재해 복구 구성 예시 (Velero)
apiVersion: velero.io/v1
kind: Schedule
metadata:
name: daily-backup
namespace: velero
spec:
# 매일 자정에 백업 수행
schedule: "0 0 * * *" # 크론 표현식 - 매일 00:00에 실행
template:
# 백업할 리소스 지정
includedNamespaces:
- default # default 네임스페이스 백업
- production # production 네임스페이스 백업
# 특정 리소스 제외
excludedResources:
- Job # 임시 작업은 백업에서 제외
- ConfigMap # 환경 구성은 별도 관리
# 볼륨 스냅샷 포함 - 영구 스토리지 데이터 백업
includeClusterResources: true
# 백업 유지 기간 (30일)
ttl: 720h0m0s # 720시간 = 30일
# 스냅샷 설정
snapshotVolumes: true # 볼륨 스냅샷 활성화
# 태그 추가 - 백업 식별 및 분류
labels:
type: scheduled
environment: production
---
# 재해 복구 계획
apiVersion: velero.io/v1
kind: RestoreConfig
metadata:
name: disaster-recovery-plan
namespace: velero
spec:
# 백업 선택 조건 (가장 최근 프로덕션 백업)
backupSelector:
matchLabels:
type: scheduled
environment: production
# 특정 리소스만 복원
includedNamespaces:
- production # 프로덕션 네임스페이스만 복원
# 우선순위 설정 (중요 서비스 먼저 복원)
restoreOrder:
- databases # 1순위: 데이터베이스
- backend-services # 2순위: 백엔드 서비스
- frontend-services # 3순위: 프론트엔드 서비스
# 복원 작업 지침
restoreStrategy:
# 기존 리소스 충돌 시 동작
conflictMode: overwrite # 충돌 시 백업 데이터로 덮어쓰기
# 복원 후크 (복원 후 검증 스크립트 실행)
postHooks:
- name: "verify-services" # 서비스 검증 후크
exec:
container: "validator"
command:
- "/scripts/verify-restore.sh" # 복원 검증 스크립트
onError: Fail # 오류 시 작업 실패로 처리
- name: "notify-team" # 팀 알림 후크
exec:
container: "notifier"
command:
- "python"
- "/scripts/notify-restore-complete.py" # 알림 스크립트
onError: Continue # 오류 시에도 작업 계속 진행
▶️ 자동화된 장애 조치
- 자동 감지 및 알림
- 무중단 장애 조치 프로세스
- 롤백 및 복구 자동화
- 사후 분석 및 개선

📌 Observability를 통한 트래픽 관리 최적화
Observability 도구를 활용하여 트래픽 관리 전략을 최적화하고 단일 장애점을 효과적으로 모니터링할 수 있습니다.
✅ 메트릭 기반 트래픽 모니터링
효과적인 트래픽 관리를 위한 핵심 메트릭:
▶️ 트래픽 볼륨 메트릭
- 초당 요청 수(RPS)
- 대역폭 사용량
- 연결 수
- 패킷 손실률
▶️ 성능 메트릭
- 응답 시간(지연 시간)
- 처리량
- 오류율
- 서비스 포화도
# Prometheus 규칙 - 트래픽 모니터링 알림 예시
groups:
- name: traffic_alerts # 알림 그룹 이름
rules:
# 높은 오류율 알림 규칙
- alert: HighErrorRate # 알림 이름
# 표현식: 서비스별 5xx 오류율이 5% 이상인 경우 알림
expr: sum(rate(http_requests_total{status=~"5.."}[5m])) by (service) / sum(rate(http_requests_total[5m])) by (service) > 0.05
for: 2m # 2분 동안 지속될 경우에만 알림 발생
labels:
severity: critical # 심각도: 중대
category: traffic # 카테고리: 트래픽
annotations: # 알림 내용 및 설명
summary: "높은 오류율 감지: {{ $labels.service }}"
description: "서비스 {{ $labels.service }}에서 5%를 초과하는 오류율이 발생하고 있습니다. (현재 값: {{ $value | humanizePercentage }})"
# 지연 시간 알림 규칙
- alert: HighLatency
# 표현식: 95번째 백분위수 지연 시간이 0.5초 초과
expr: histogram_quantile(0.95, sum(rate(http_request_duration_seconds_bucket[5m])) by (le, service)) > 0.5
for: 5m # 5분 동안 지속될 경우 알림
labels:
severity: warning # 심각도: 경고
category: traffic
annotations:
summary: "지연 시간 증가: {{ $labels.service }}"
description: "{{ $labels.service }}의 95번째 백분위수 지연 시간이 0.5초를 초과했습니다. (현재 값: {{ $value }}s)"
# 트래픽 급증 알림 규칙
- alert: TrafficSpike
# 표현식: 1시간 전 대비 트래픽이 2배(100%) 이상 증가
expr: sum(rate(http_requests_total[5m])) by (service) > sum(rate(http_requests_total[1h] offset 1h)) by (service) * 2
for: 5m
labels:
severity: warning
category: traffic
annotations:
summary: "트래픽 급증: {{ $labels.service }}"
description: "{{ $labels.service }}에서 1시간 전 대비 트래픽이 100% 이상 증가했습니다."
# 연결 포화 알림 규칙
- alert: ConnectionSaturation
# 표현식: 활성 연결이 최대 연결 수의 80% 초과
expr: sum(nginx_connections_active) by (instance) / sum(nginx_connections_max) by (instance) > 0.8
for: 5m
labels:
severity: warning
category: traffic
annotations:
summary: "연결 포화 상태: {{ $labels.instance }}"
description: "{{ $labels.instance }}의 활성 연결이 최대 용량의 80%를 초과했습니다. (현재 값: {{ $value | humanizePercentage }})"
▶️ 트래픽 패턴 분석
- 일간/주간/월간 패턴
- 지역별 트래픽 분포
- 클라이언트 유형 및 디바이스
- 요청 경로 및 엔드포인트 사용률
✅ 이상 탐지 및 자동 대응
Observability 데이터를 활용한 이상 탐지 및 자동화된 대응:
▶️ 이상 탐지 방법
- 정적 임계값 기반 탐지
- 동적 기준선 및 계절성 분석
- 기계 학습 기반 이상 탐지
- 다변량 이상 탐지
✅ 시각화 및 대시보드
효과적인 트래픽 관리를 위한 대시보드 설계:
▶️ 핵심 대시보드 구성 요소
- 시스템 상태 개요
- 트래픽 흐름 시각화
- 서비스 의존성 맵
- 알림 및 이벤트 타임라인
▶️ 알림 및 보고
- 실시간 알림 구성
- 정기적인 보고서 자동화
- 상관관계 있는 이벤트 통합
- 에스컬레이션 워크플로우
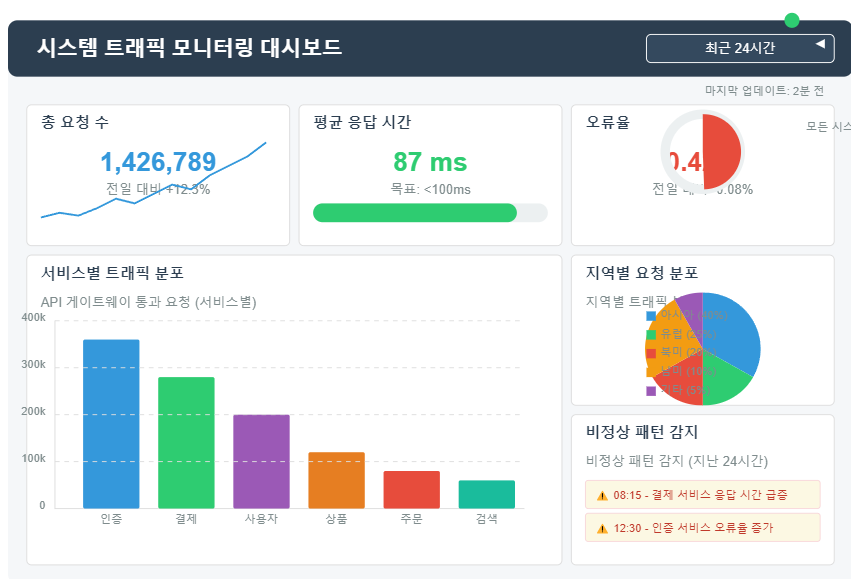
📌 주요 구현 사례 및 모범 사례
실제 환경에서 트래픽 관리와 SPOF 해결을 위한 모범 사례와 구현 패턴입니다.
✅ 대규모 서비스 구현 사례
다양한 산업 분야에서의 효과적인 트래픽 관리 구현 사례:
▶️ 전자상거래 플랫폼
- 중요 시기(예: 블랙 프라이데이)를 위한 트래픽 관리
- 동적 카탈로그 및 장바구니 시스템 복원력
- 결제 시스템 신뢰성 보장
▶️ 금융 서비스
- 24/7 가용성 보장을 위한 다중화
- 데이터 정합성 우선 아키텍처
- 실시간 사기 탐지 및 방지
▶️ 미디어 스트리밍
- 콘텐츠 전송 네트워크(CDN) 최적화
- 지역별 트래픽 라우팅
- 인기 이벤트 처리를 위한 버스트 용량
✅ 트래픽 관리 모범 사례
효과적인 트래픽 관리와 SPOF 해결을 위한 모범 사례:
▶️ 아키텍처 설계 원칙
- "N+1" 및 "2N" 이중화 원칙 적용
- 점진적 성능 저하 설계
- 경계 제한 및 격리
- 비동기 통신 패턴
▶️ 운영 모범 사례
- 주기적인 재해 복구 훈련
- 카오스 공학 실험
- 사전 예방적 용량 계획
- 증분식 변경 및 롤백 계획
▶️ 모니터링 및 알림 최적화
- 의미 있는 알림 설계
- 알림 피로 감소 전략
- SLO 기반 알림
- 자동화된 근본 원인 분석
✅ 흔한 함정 및 해결 방법
트래픽 관리와 SPOF 제거 과정에서 흔히 발생하는 문제와 해결책:
▶️ 과도한 복잡성
- 문제: 너무 복잡한 시스템은 새로운 SPOF를 만들 수 있음
- 해결책: 간결한 설계 원칙 적용 및 복잡성 관리
▶️ 잘못된 테스트 가정
- 문제: 비현실적인 환경에서의 테스트는 실제 문제를 발견하지 못함
- 해결책: 프로덕션과 유사한 환경에서의 테스트 및 점진적 출시
▶️ 미확인 의존성
- 문제: 숨겨진 의존성이 SPOF로 작용할 수 있음
- 해결책: 철저한 의존성 맵핑 및 지속적인 검증
▶️ 공통 모드 실패
- 문제: 물리적으로 분리되었지만 동일한 원인으로 실패하는 시스템
- 해결책: 다양한 기술 스택, 공급 업체, 리전 활용
📌 결론
효과적인 트래픽 관리와 단일 장애점 해결은 현대적인 시스템의 복원력과 가용성을 보장하는 데 필수적입니다. Observability를 기반으로 한 접근 방식은 이러한 노력을 크게 향상시킬 수 있습니다.
이 글에서 다룬 주요 내용을 요약하면 다음과 같습니다:
- 트래픽 관리는 단순한 부하 분산 이상의 의미를 가지며, 시스템 복원력을 위한 핵심 요소입니다.
- **단일 장애점(SPOF)**을 식별하고 제거하는 것은 고가용성 시스템 구축의 기본입니다.
- 다중화 및 이중화 전략은 핵심 구성 요소의 장애에 대비하는 데 중요합니다.
- 인텔리전트 로드 밸런싱을 통해 효율적인 자원 활용과 성능 최적화가 가능합니다.
- 서킷 브레이커 패턴은 장애 전파를 방지하고 부분적 실패를 관리하는 데 효과적입니다.
- 레이트 리미팅 및 트래픽 쉐이핑은 시스템 안정성을 유지하는 데 필수적입니다.
- 지리적 분산 및 다중 리전 아키텍처는 대규모 재해에 대한 보호를 제공합니다.
- Observability 도구를 활용한 모니터링은 트래픽 관리 전략을 최적화하는 데 중요합니다.
효과적인 트래픽 관리와 SPOF 해결 전략을 통해 시스템은 예측 불가능한 부하 패턴, 구성 요소 장애, 그리고 심지어 전체 리전 장애에도 복원력을 유지할 수 있습니다.