이번 글에서는 이전에 설치한 Grafana 환경을 활용하여 효과적인 대시보드를 생성하고 커스터마이징하는 방법을 자세히 살펴보겠습니다. Grafana의 강력한 시각화 기능과 다양한 패널 유형을 이해하고, Prometheus 데이터를 효과적으로 시각화하는 방법을 배워볼 것입니다. 또한 변수와 템플릿을 활용한 동적 대시보드 구성, 알림 설정, 효과적인 레이아웃 구성 등 대시보드를 마스터하기 위한 핵심 기법들을 다룹니다. 이 지식을 바탕으로 쿠버네티스 환경을 위한 직관적이고 정보가 풍부한 맞춤형 모니터링 대시보드를 구축할 수 있게 될 것입니다.
📌 Grafana 대시보드 기본 개념
Grafana 대시보드를 생성하기 전에 기본 개념과 구조를 이해하는 것이 중요합니다.
✅ 대시보드 구조의 이해
Grafana 대시보드는 다음과 같은 주요 구성 요소로 이루어져 있습니다:
- 패널(Panel): 데이터를 시각화하는 기본 단위
- 행(Row): 패널을 그룹화하는 단위
- 변수(Variable): 대시보드를 동적으로 구성할 수 있게 하는 요소
- 주석(Annotation): 타임라인에 이벤트 정보를 표시하는 마커
- 시간 범위 컨트롤: 데이터 조회 기간을 지정
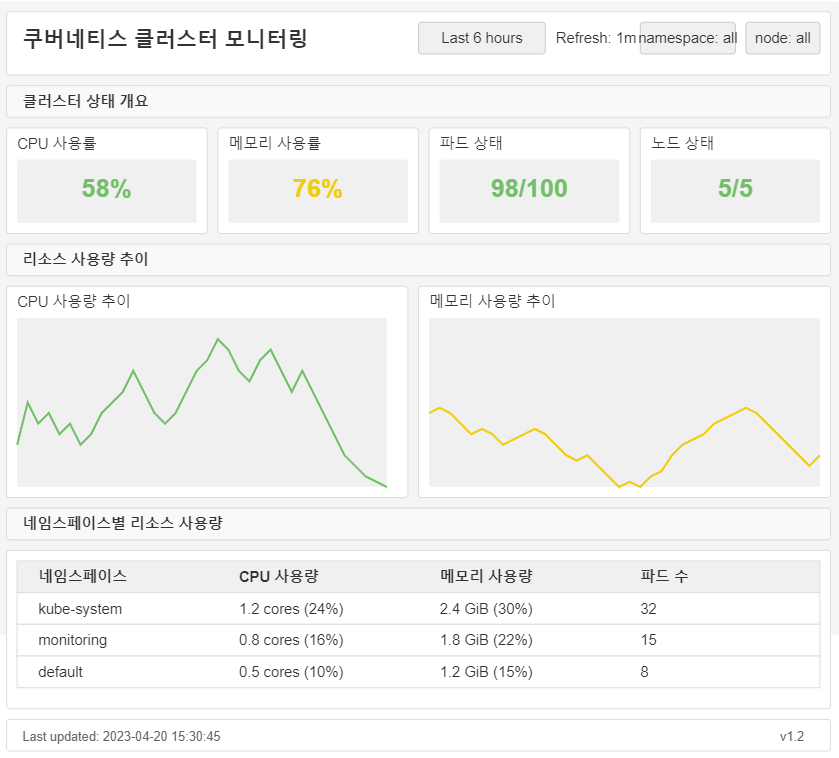
✅ 첫 번째 대시보드 생성하기
Grafana UI를 통해 첫 번째 대시보드를 만드는 기본 단계:
- Grafana에 로그인합니다
- 좌측 메뉴에서 "Create" > "Dashboard"를 클릭합니다
- "Add new panel" 버튼을 클릭합니다
- 데이터 소스와 쿼리를 구성합니다
- 시각화 유형을 선택하고 설정합니다
- "Apply" 버튼을 클릭하여 패널을 저장합니다
- 우측 상단의 디스크 아이콘을 클릭하여 대시보드를 저장합니다
✅ 대시보드 JSON 구조
모든 Grafana 대시보드는 JSON 형식으로 정의됩니다. 기본적인 구조를 이해하면 대시보드를 프로그래밍 방식으로 관리하는 데 도움이 됩니다:
```json
{
"id": null,
# 대시보드 ID - 새 대시보드의 경우 null (저장 시 자동 생성됨)
# 이미 저장된 대시보드를 업데이트할 때는 해당 대시보드의 숫자 ID 사용
"uid": "abc123",
# 대시보드 고유 식별자 - URL에 사용되는 문자열 ID
# 일반적으로 8-12자 길이의 알파벳과 숫자로 구성
# 대시보드 이동/복원 시에도 유지되는 영구적 식별자
"title": "My Kubernetes Dashboard",
# 대시보드 제목 - UI에 표시되는 이름
# 사용자가 대시보드 목록에서 식별하는 데 사용됨
"tags": ["kubernetes", "monitoring"],
# 대시보드 태그 목록 - 검색 및 필터링에 사용
# 관련 대시보드를 그룹화하는 데 유용
"timezone": "browser",
# 시간대 설정 - 시간 표시 방식 결정
# "browser": 사용자 브라우저 시간대 사용
# 다른 옵션: "utc" 또는 특정 지역 시간대 (예: "America/New_York")
"editable": true,
# 대시보드 편집 가능 여부
# true: 권한이 있는 사용자가 대시보드 수정 가능
# false: 대시보드 잠금(읽기 전용)
"graphTooltip": 0,
# 그래프 툴팁 모드 설정
# 0: 기본값 - 개별 시리즈 툴팁
# 1: 공유 툴팁 - 같은 시간의 모든 시리즈 표시
# 2: 공유 툴팁 + 크로스헤어(세로선)
"panels": [
# 대시보드를 구성하는 모든 패널의 배열
{
"id": 1,
# 패널 ID - 대시보드 내에서 패널의 고유 식별자
# 대시보드 내에서 자동 증가하는 숫자
"gridPos": {"h": 8, "w": 12, "x": 0, "y": 0},
# 그리드 위치 및 크기 정보
# h: 패널 높이 (그리드 단위)
# w: 패널 너비 (최대 24 단위)
# x: 왼쪽에서부터의 위치 (0부터 시작)
# y: 위에서부터의 위치 (0부터 시작)
"type": "graph",
# 패널 유형 - 시각화 방식 결정
# "graph": 기본 시계열 그래프
# 다른 옵션: "gauge", "stat", "table", "heatmap" 등
"title": "CPU Usage",
# 패널 제목 - 패널 상단에 표시되는 이름
"datasource": {"type": "prometheus", "uid": "P1234567890"},
# 데이터 소스 정보
# type: 데이터 소스 유형 (여기서는 "prometheus")
# uid: 데이터 소스의 고유 식별자
"targets": [
# 패널에 표시할 데이터를 가져오는 쿼리 목록
{
"expr": "sum(rate(container_cpu_usage_seconds_total{namespace=\"$namespace\"}[5m])) by (pod)",
# Prometheus 쿼리 표현식
# $namespace: 대시보드 변수 참조
# sum by (pod): 파드별로 데이터 합산
# rate(...[5m]): 5분 간격 변화율 계산
"legendFormat": "{{pod}}",
# 범례 형식 - 그래프에 표시될 범례 텍스트 형식
# {{pod}}: 레이블 값으로 대체됨 (각 파드 이름 표시)
"refId": "A"
# 쿼리 참조 ID - 동일 패널 내 여러 쿼리 구분
# 알림 규칙이나 다른 설정에서 특정 쿼리 참조 시 사용
}
],
"options": {...},
# 패널 옵션 - 패널 유형에 따라 다양한 시각화 옵션 포함
# 축 설정, 범례 위치, 그리드 표시 여부 등
"fieldConfig": {...}
# 필드 구성 - 데이터 필드의 서식 및 표시 방법 정의
# 단위, 색상, 임계값, 소수점 자릿수 등
}
],
"templating": {
"list": [
# 대시보드 변수 목록
{
"name": "namespace",
# 변수 이름 - 쿼리에서 $namespace로 참조
"type": "query",
# 변수 유형 - "query"는 데이터 소스에서 값 조회
# 다른 옵션: "custom", "constant", "datasource", "interval" 등
"datasource": {"type": "prometheus", "uid": "P1234567890"},
# 변수 값을 조회할 데이터 소스
"query": "label_values(kube_pod_info, namespace)",
# 변수 값을 가져오는 쿼리
# label_values(): 특정 메트릭의 레이블 값 목록 반환
# 이 쿼리는 모든 네임스페이스 목록을 반환
"current": {"selected": true, "text": "default", "value": "default"}
# 현재 선택된 변수 값 정보
# selected: 선택 여부
# text: UI에 표시되는 텍스트
# value: 실제 변수 값
}
]
},
"time": {
"from": "now-6h",
# 시작 시간 - 현재 시점에서 6시간 전
# 다른 예: "now-1d"(1일 전), "now-7d"(7일 전)
"to": "now"
# 종료 시간 - 현재 시점
# 상대 시간 또는 절대 시간(ISO 8601 형식) 사용 가능
}
}
```📌 다양한 패널 유형과 활용법
Grafana는 데이터를 시각화하기 위한 다양한 패널 유형을 제공합니다. 상황에 맞는 패널을 선택하는 것이 효과적인 대시보드 구성의 핵심입니다.
✅ 시계열 그래프 (Time Series)
가장 기본적이고 널리 사용되는 패널로, 시간에 따른 데이터 변화를 보여줍니다:
# 노드별 CPU 사용률 시계열 그래프
# node_cpu_seconds_total: CPU 사용 시간(초) 메트릭
# rate(): 지정된 간격 동안의 초당 변화율
# mode="idle": 유휴 CPU 시간만 선택
# by (instance): 노드(인스턴스)별로 결과 그룹화
# 1 - rate(...): 유휴 시간을 제외한 CPU 사용률 계산
# instance 레이블이 노드 이름으로 표시됨
# 결과는 0-1 사이의 값으로 나타나며, 곱하기 100하면 백분율로 표시
1 - avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[5m]))
시계열 그래프 패널 설정:
- Display: Lines, Bars, Points 중 선택
- Stacking: Normal, Percent, None
- Legend: 표시 여부, 위치, 형식 설정
- Axes: 단위, 최소/최대값, 로그 스케일 등
- Thresholds: 임계값 설정 (예: 경고/위험 레벨)
✅ 게이지 (Gauge)
단일 값을 시각적으로 표현하는 데 이상적인 패널입니다:
# 전체 메모리 사용률 게이지
# node_memory_MemTotal_bytes: 전체 메모리 크기
# node_memory_MemAvailable_bytes: 사용 가능한 메모리
# 1 - (available / total): 사용 중인 메모리 비율
# avg_over_time(): 지정된 기간 동안의 평균값
# [5m]: 5분 간격
# 클러스터 전체의 평균 메모리 사용률을 단일 값으로 표시
# 0-1 사이의 값으로 반환되므로 게이지 패널에 적합
1 - avg(node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes)
게이지 패널 설정:
- Min/Max: 값의 범위 설정 (보통 0-1 또는 0-100)
- Thresholds: 색상 변화 임계값 (예: <50% 녹색, 50-80% 노란색, >80% 빨간색)
- Show Threshold Labels: 임계값 라벨 표시 여부
- Show Threshold Markers: 임계값 마커 표시 여부
✅ 통계 패널 (Stat)
단일 값을 큰 숫자로 표시하는 간단한 패널입니다:
# 실행 중인 파드 수 통계
# kube_pod_status_phase: 파드 상태 메트릭
# phase="Running": 실행 중인 파드만 선택
# count(): 총 개수 계산
# 클러스터 내 실행 중인 모든 파드의 수를 단일 값으로 표시
# 정수 값으로 반환되며 통계 패널에 적합
count(kube_pod_status_phase{phase="Running"})
통계 패널 설정:
- Value Mappings: 특정 값을 텍스트로 매핑
- Standard Options: 단위, 소수점 자릿수, 레이블 등
- Text Mode: 값, 값+이름, 이름 등 표시 모드
- Color Mode: 값에 따른 색상 변화 방식
✅ 테이블 (Table)
여러 관련 데이터를 행과 열로 표시하는 데 유용합니다:
# 네임스페이스별 리소스 사용량 테이블
# sum by (namespace): 네임스페이스별로 합계 계산
# container_cpu_usage_seconds_total: CPU 사용량 메트릭
# container_memory_working_set_bytes: 메모리 사용량 메트릭
# 네임스페이스, CPU 사용량, 메모리 사용량 3개 열로 구성된 테이블
# CPU는 프로세서 코어 단위, 메모리는 바이트 단위로 표시
# CPU 사용량
sum by (namespace) (rate(container_cpu_usage_seconds_total{container!="POD", container!=""}[5m]))
# 메모리 사용량
sum by (namespace) (container_memory_working_set_bytes{container!="POD", container!=""})
테이블 패널 설정:
- Columns: 표시할 열과 순서 설정
- Column Width: 열 너비 조정
- Cell Display Mode: 색상 표시 방식 (Color text, Color background 등)
- Thresholds: 값에 따른 셀 색상 변화
✅ 히트맵 (Heatmap)
데이터 분포를 색상 강도로 표현합니다:
# HTTP 응답 시간 분포 히트맵
# histogram_quantile(): 히스토그램 데이터의 분위수 계산
# http_request_duration_seconds_bucket: HTTP 요청 처리 시간 히스토그램
# 각 버킷에 포함된 요청 수를 시간에 따라 색상 강도로 표시
# le: 버킷 상한 (less than or equal)
# 응답 시간 분포의 변화를 시간별로 추적 가능
# 히트맵용 raw 히스토그램 데이터 - le 레이블 필요
sum(increase(http_request_duration_seconds_bucket[1m])) by (le)
히트맵 패널 설정:
- Color Mode: 색상 스키마 선택 (Spectrum, Opacity 등)
- Cell Size: 셀 크기 조정 (자동 또는 수동)
- Y-Axis: 버킷 설정 방식 (linear, logarithmic)
- Tooltip: 표시할 정보 설정
✅ 로그 패널 (Logs)
로그 데이터를 표시하고 필터링합니다:
# 로그 패널은 주로 Loki 데이터 소스와 함께 사용됩니다
# Prometheus는 메트릭 데이터 소스로 로그 패널에 적합하지 않습니다
# Loki 쿼리 예시 (참고용)
{app="nginx"} |= "error" | logfmt
로그 패널 설정:
- Deduplication: 중복 로그 제거 여부
- Time Column: 타임스탬프 표시 방식
- Order: 표시 순서 (Newest first, Oldest first)
- Prettify JSON: JSON 로그 구조화 여부
✅ 노드 그래프 (Node Graph)
노드 간 관계를 시각화합니다:
# 노드 그래프는 주로 분산 트레이싱 데이터(Jaeger, Zipkin) 시각화에 사용됩니다
# Prometheus는 메트릭 데이터 소스로 노드 그래프에 직접 적합하지 않습니다
📌 효과적인 Prometheus 쿼리 작성
Grafana에서 Prometheus 데이터를 효과적으로 활용하려면 PromQL(Prometheus Query Language)을 잘 이해하는 것이 중요합니다.
✅ 기본 쿼리 구조
PromQL의 기본 구조와 자주 사용되는 함수를 알아보겠습니다:
# 기본 구조: 메트릭 이름{레이블 선택자}[시간 범위] 필터 연산자...
# 레이블 선택자 유형
# =: 정확히 일치
# !=: 불일치
# =~: 정규식 일치
# !~: 정규식 불일치
# 예시: production 네임스페이스의 모든 HTTP 서버 메트릭
http_requests_total{namespace="production"}
# 시간 범위 지정 (rate 함수 등에 필요)
rate(http_requests_total{namespace="production"}[5m])
✅ 집계 및 조인 함수
데이터를 요약하고 조합하는 방법:
# 집계 함수: sum, avg, min, max, count
# by 절: 특정 레이블로 그룹화
# 네임스페이스별 총 요청 수
sum by(namespace) (http_requests_total)
# instance 레이블별 평균 CPU 사용률
avg by(instance) (1 - rate(node_cpu_seconds_total{mode="idle"}[5m]))
# 상위 5개 메모리 사용 파드
topk(5, sum by(pod, namespace) (container_memory_working_set_bytes{container!="POD"}))
✅ 시계열 함수
시간에 따른 데이터 변화를 분석하는 함수:
# rate(): 시간당 변화율 (카운터 유형에 사용)
# 5분 동안의 초당 HTTP 요청 수
rate(http_requests_total[5m])
# increase(): 지정된 기간 동안의 총 증가량
# 1시간 동안의 총 오류 수
increase(http_request_errors_total[1h])
# irate(): 순간 변화율 (마지막 두 샘플 기준)
# 빠르게 변하는 카운터의 순간 값 계산
irate(http_requests_total[5m])
# changes(): 값이 변경된 횟수
# 1시간 동안 상태가 변경된 횟수
changes(up[1h])
✅ 히스토그램 및 요약 함수
분포 데이터 분석 함수:
# histogram_quantile(): 히스토그램에서 분위수 계산
# HTTP 요청 지연 시간의 95번째 백분위수
histogram_quantile(0.95, sum by(le) (rate(http_request_duration_seconds_bucket[5m])))
# 여러 분위수 동시 계산 (50%, 90%, 95%)
# A, B, C는 Grafana 쿼리 참조 ID
# 대시보드에서 동일 그래프에 여러 분위수 표시 가능
histogram_quantile(0.5, sum by(le) (rate(http_request_duration_seconds_bucket[5m]))) # A
histogram_quantile(0.9, sum by(le) (rate(http_request_duration_seconds_bucket[5m]))) # B
histogram_quantile(0.95, sum by(le) (rate(http_request_duration_seconds_bucket[5m]))) # C
✅ 경보 및 예측 함수
문제 감지 및 예측을 위한 함수:
# predict_linear(): 선형 예측 수행
# 4시간 후 디스크 공간이 소진될지 예측
predict_linear(node_filesystem_free_bytes{mountpoint="/"}[1h], 4 * 3600) < 0
# deriv(): 시계열의 기울기 계산
# 메모리 사용량의 증가율 확인
deriv(container_memory_usage_bytes{namespace="default"}[1h])
# absent(): 시계열이 없을 때 1 반환
# 메트릭이 사라졌는지 감지 (예: 서비스 다운 감지)
absent(up{job="api-server"})
✅ 레이블 조작 함수
레이블을 변환하거나 처리하는 함수:
# label_replace(): 레이블 값 바꾸기
# instance 레이블에서 도메인 제거
label_replace(up, "instance", "$1", "instance", "(.*):.*")
# label_join(): 여러 레이블 결합
# pod와 container 레이블을 결합하여 새 레이블 생성
label_join(container_cpu_usage_seconds_total, "pod_container", "_", "pod", "container")
📌 변수와 템플릿을 활용한 동적 대시보드
대시보드 변수를 사용하면 사용자가 동적으로 데이터를 필터링하고 다양한 뷰를 제공할 수 있습니다.
✅ 변수 유형과 설정
Grafana에서 사용할 수 있는 다양한 변수 유형을 살펴보겠습니다:
- 쿼리 변수: 데이터 소스에서 동적으로 값을 가져옵니다
- 네임스페이스, 노드, 파드 등의 목록을 동적으로 로드할 때 유용
- 사용자 정의 변수: 미리 정의된 값 목록
- 고정된 옵션을 제공할 때 유용 (예: 환경 선택)
- 텍스트 상자 변수: 사용자 입력 값
- 임의의 필터링 값을 입력할 때 유용
- 상수 변수: 고정된 값
- 전체 대시보드에서 재사용할 값
- 데이터 소스 변수: 사용 가능한 데이터 소스
- 여러 Prometheus 인스턴스 간 전환 시 유용
- 간격 변수: 시간 간격
- 집계 함수의 시간 범위를 동적으로 조정
- 종속 변수: 다른 변수에 따라 값이 변하는 변수
- 계층적 필터링에 유용 (예: 네임스페이스 선택 후 해당 네임스페이스의 파드 표시)
✅ 쿼리 기반 변수 설정 예시
쿠버네티스 모니터링에 유용한 쿼리 변수 설정 방법:
- 네임스페이스 변수 설정
- 대시보드 설정 > Variables > Add variable
- Name: namespace
- Type: Query
- Data source: Prometheus
- Query: label_values(kube_pod_info, namespace)
- Sort: Alphabetical (asc)
- Multi-value 및 Include All option 활성화
- 파드 변수 설정 (네임스페이스에 종속)
- Name: pod
- Type: Query
- Data source: Prometheus
- Query: label_values(kube_pod_info{namespace="$namespace"}, pod)
- Sort: Alphabetical (asc)
- Multi-value 및 Include All option 활성화
- 노드 변수 설정
- Name: node
- Type: Query
- Data source: Prometheus
- Query: label_values(kube_node_info, node)
- Sort: Alphabetical (asc)
- Multi-value 및 Include All option 활성화
- 시간 간격 변수 설정
- Name: interval
- Type: Interval
- Values: 1m,5m,10m,30m,1h,6h,12h,1d
- Default: 5m
✅ 변수를 활용한 쿼리 작성
설정한 변수를 쿼리에서 활용하는 방법:
# 선택한 네임스페이스의 CPU 사용량
# $namespace: 네임스페이스 변수
# $interval: 시간 간격 변수
# namespace="$namespace": 변수값으로 필터링
# [$interval]: 변수로 시간 범위 조정
# 사용자가 UI에서 선택한 네임스페이스와 시간 간격에 따라 쿼리 결과가 변경됨
sum by (pod) (rate(container_cpu_usage_seconds_total{namespace="$namespace", container!="POD", container!=""}[$interval]))
# 선택한 파드의 메모리 사용량
# $namespace: 네임스페이스 변수
# $pod: 파드 변수
# pod=~"$pod": 정규식 일치 (멀티 선택 지원)
# 여러 파드 선택 시 pod=~"pod1|pod2|pod3" 형태로 변환됨
sum by (pod) (container_memory_working_set_bytes{namespace="$namespace", pod=~"$pod", container!="POD", container!=""})
# 선택한 노드의 디스크 사용량
# $node: 노드 변수
# instance=~"($node).*": 노드 이름으로 시작하는 인스턴스
# 여러 노드 선택 시 instance=~"(node1|node2).*" 형태로 변환됨
(1 - node_filesystem_avail_bytes{instance=~"($node).*", mountpoint="/"} / node_filesystem_size_bytes{instance=~"($node).*", mountpoint="/"}) * 100
✅ 반복 패널 (Repeating Panels)
동일한 패널을 여러 변수 값에 대해 자동으로 반복하여 표시:
- 패널 반복 설정
- 패널 편집 > General > Repeat options
- Direction: Horizontal 또는 Vertical
- Variable: 반복할 변수 선택 (예: node)
- 행 반복 설정
- 행 편집 > Repeat for 필드에 변수 선택 (예: namespace)
[반복 패널 예시:
- 각 노드별 CPU, 메모리, 디스크 사용량을 보여주는 패널 행 반복
- 각 네임스페이스별 파드 상태를 보여주는 패널 행 반복
- 각 서비스별 요청 수, 오류율, 지연 시간을 보여주는 패널 그룹 반복]
📌 고급 대시보드 테크닉
더 효과적인 대시보드를 구성하기 위한 고급 기법들을 살펴보겠습니다.
✅ 대시보드 주석 (Annotations)
시계열 데이터에 중요 이벤트를 표시하는 방법:
- Grafana 주석 설정
- 대시보드 설정 > Annotations > Add Annotation Query
- Name: 주석 이름 (예: "Deployments")
- Data source: Prometheus
- Query: changes(kube_deployment_status_replicas_updated{namespace="$namespace"}[1m]) > 0
- Tags: deployment, update
- 쿠버네티스 이벤트를 주석으로 표시
- Kubernetes Events 데이터 소스 연결 필요
- 주요 클러스터 이벤트를 타임라인에 표시
[주석 표시 예시:
- 디플로이먼트 업데이트 시점
- 노드 추가/제거 시점
- 파드 재시작 이벤트
- 알림 발생 시점]
✅ 임계값 및 알림 설정
패널에 임계값을 표시하고 알림을 설정하는 방법:
- 패널 임계값 설정
- 패널 편집 > Thresholds
- Add threshold > 값 및 색상 설정
- 예: 70 (warning), 90 (critical)
- Grafana 알림 설정
- 패널 편집 > Alert
- Create Alert > 조건 설정
- 예: WHEN avg() OF query(A, 5m, now) IS ABOVE 90
- Notifications > 알림 채널 선택
```json
# 알림 규칙 JSON 예시
{
"alertRuleTags": {},
# 알림 규칙에 태그를 추가할 수 있는 속성
# 빈 객체는 태그가 설정되지 않았음을 의미
# 태그는 알림 분류 및 라우팅에 사용 가능 (예: "환경": "프로덕션")
"conditions": [
# 알림 조건 정의 배열 - 알림이 발생하는 조건을 지정
{
"evaluator": {
"params": [90],
# 임계값 매개변수 - 여기서는 90이 임계값
"type": "gt"
# 비교 유형 - gt는 Greater Than (초과)
# 다른 옵션: lt(미만), within_range(범위 내), outside_range(범위 외) 등
},
"operator": {
"type": "and"
# 조건 결합 연산자 - 여러 조건이 있을 때 사용
# "and": 모든 조건이 충족되어야 함, "or": 하나 이상의 조건 충족 시
},
"query": {
"params": ["A", "5m", "now"]
# A: 패널에서 참조하는 쿼리 ID
# 5m: 평가 기간 (과거 5분)
# now: 현재 시점까지 평가
},
"reducer": {
"params": [],
# 리듀서 매개변수 - 결과를 단일 값으로 집계하는 방법
"type": "avg"
# 집계 유형 - avg는 평균값 계산
# 다른 옵션: min, max, sum, count, last, median 등
},
"type": "query"
# 조건 유형 - query는 데이터 소스 쿼리 기반 조건
}
],
"executionErrorState": "alerting",
# 실행 오류 발생 시 알림 상태 설정
# "alerting": 오류 시 알림 발생
# 다른 옵션: "keep_state"(상태 유지), "ok"(정상 상태로 간주)
"for": "5m",
# 조건이 연속으로 충족되어야 하는 시간
# 5m: 5분 동안 조건이 계속 충족되어야 알림 발생
# 일시적인 스파이크가 알림을 트리거하지 않도록 함
"frequency": "1m",
# 조건 평가 빈도 - 1분 간격으로 조건 검사
# 더 짧으면 반응 속도가 빨라지지만 시스템 부하 증가
"handler": 1,
# 알림 처리 방식 - 1은 기본 처리기 사용
"name": "High CPU Usage Alert",
# 알림 규칙 이름 - UI에 표시되고 알림 메시지에 포함됨
"noDataState": "no_data",
# 데이터가 없을 때의 알림 상태
# "no_data": 데이터 없음 상태로 표시
# 다른 옵션: "alerting"(알림 발생), "ok"(정상 상태로 간주)
"notifications": [
# 알림을 전송할 채널 목록
{
"id": 1
# 알림 채널 ID - Grafana의 알림 채널 관리에서 설정한 채널
# 각 채널은 이메일, Slack, PagerDuty 등 다양한 통합을 나타냄
}
]
}
```✅ 값 매핑 및 단위 설정
데이터 표시 방식을 개선하는 방법:
- 값 매핑 설정
- 패널 편집 > Field > Value mappings
- 예: 0 → "Offline", 1 → "Online"
- 범위 매핑: 0-50 → "Good", 51-80 → "Warning", 81-100 → "Critical"
- 단위 설정
- 패널 편집 > Field > Unit
- 시간: seconds, minutes, hours
- 메모리: bytes, kibibytes, mebibytes
- 퍼센트: percent (0-100)
- 처리량: ops/sec, req/sec
- 소수점 및 표시 형식
- 패널 편집 > Field > Decimals
- 패널 편집 > Field > Display name
✅ 레이아웃 최적화 기법
대시보드 레이아웃을 최적화하는 방법:
- 그리드 시스템 이해
- 24열 그리드 시스템 활용
- 대시보드 패널 크기 조정 (패널 크기 드래그)
- 행 높이 조정 (행 헤더 드래그)
- 데이터 밀도 최적화
- 관련 정보 그룹화
- 과도한 정보 표시 지양
- 가장 중요한 메트릭은 상단에 배치
- 시각적 계층 구조 활용
- 테마와 색상을 일관되게 사용
- 관련 패널에 동일한 색상 스키마 적용
- 중요도에 따라 패널 크기 차별화
[레이아웃 예시:
- 상단: 주요 상태 지표 (작은 Stat 패널 여러 개)
- 중간: 상세 시계열 그래프 (넓은 Graph 패널)
- 하단: 세부 데이터 테이블 (Table 패널)
패널은 중요도와 관련성에 따라 논리적으로 배치]
✅ 대시보드 내보내기와 공유
대시보드를 공유하고 내보내는 방법:
- 대시보드 내보내기
- 대시보드 설정 > JSON Model 복사
- JSON 파일로 저장
- 버전 관리 시스템에 저장 (Git 등)
- 대시보드 가져오기
- Create > Import > Upload JSON file
- Grafana.com ID로 가져오기
- 데이터 소스 매핑 확인
- 대시보드 공유
- 대시보드 설정 > Links > Add link
- 공유 링크 생성 (시간 범위 포함)
- 스냅샷 생성 (데이터 포함)
- 이미지/PDF로 내보내기
- 패널 메뉴 > Share > Direct link rendered image
- 전체 대시보드 PDF 내보내기 (Enterprise 기능)
✅ 대시보드 버전 관리
대시보드 변경 사항 추적 및 관리:
- 기본 버전 관리
- Grafana 내장 버전 관리 기능
- 대시보드 설정 > Versions
- 이전 버전으로 복원 가능
- 코드로서의 대시보드
- JSON 형식으로 대시보드 정의
- Git을 통한 버전 관리
- CI/CD 파이프라인을 통한 자동 배포
# Grafana API를 통한 대시보드 내보내기 (자동화 예시)
curl -H "Authorization: Bearer $API_KEY" \
-H "Content-Type: application/json" \
http://grafana.example.com/api/dashboards/uid/abc123 > dashboard.json
# 대시보드 가져오기
curl -X POST \
-H "Authorization: Bearer $API_KEY" \
-H "Content-Type: application/json" \
-d @dashboard.json \
http://grafana.example.com/api/dashboards/import
📌 쿠버네티스 모니터링을 위한 주요 대시보드 패턴
쿠버네티스 환경에서 효과적인 모니터링을 위한 대시보드 패턴을 살펴보겠습니다.
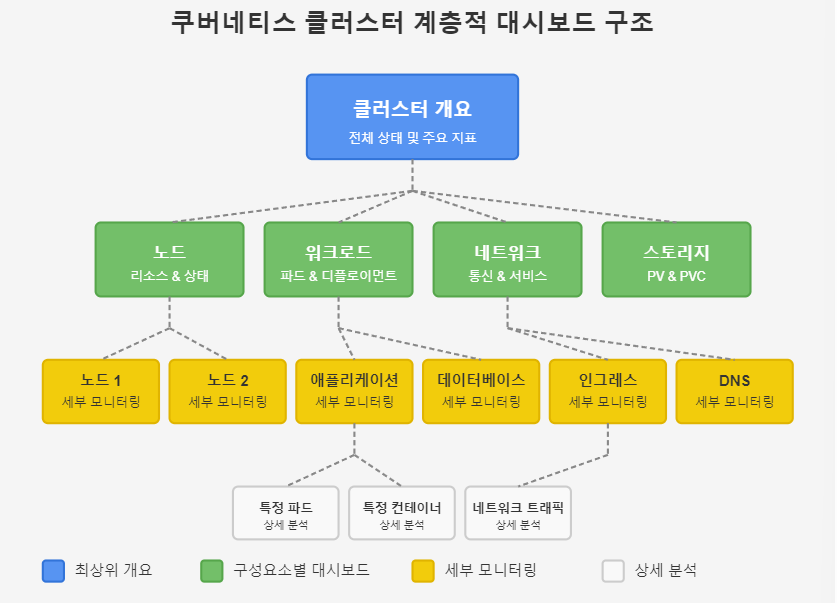
✅ 계층적 대시보드 구조
계층별로 구성된 대시보드 시스템 구축:
- 개요 대시보드 (Top Level)
- 클러스터 전반 상태 표시
- 주요 경고 및 문제 하이라이트
- 각 영역별 상세 대시보드 링크
- 컴포넌트별 대시보드 (Mid Level)
- 노드 모니터링 대시보드
- 네임스페이스 모니터링 대시보드
- 워크로드 모니터링 대시보드
- 세부 분석 대시보드 (Detail Level)
- 개별 노드 상세 분석
- 특정 파드/컨테이너 상세 분석
- 네트워크 트래픽 상세 분석
✅ 클러스터 개요 대시보드 패턴
클러스터 상태를 한눈에 파악할 수 있는 대시보드:
- 핵심 지표 (상단)
- 노드 수 및 상태
- 파드 수 및 상태
- 클러스터 리소스 사용률 (CPU, 메모리, 디스크)
- 리소스 추세 (중앙)
- 클러스터 CPU 사용량 추이
- 클러스터 메모리 사용량 추이
- 클러스터 네트워크 트래픽 추이
- 알림 및 문제 (하단)
- 활성 알림 목록
- 노드 상태 이상
- 리소스 제약 워크로드
# 클러스터 CPU 사용률 계산
# sum(rate(container_cpu_usage_seconds_total{container!="POD", container!=""}[5m])): 모든 컨테이너의 총 CPU 사용량
# sum(machine_cpu_cores): 클러스터 내 모든 노드의 총 CPU 코어 수
# 클러스터 전체의 CPU 사용률을 백분율로 표시
# 리소스 계획 및 용량 관리에 유용한 지표
sum(rate(container_cpu_usage_seconds_total{container!="POD", container!=""}[5m])) / sum(machine_cpu_cores) * 100
# 클러스터 메모리 사용률 계산
# sum(container_memory_working_set_bytes{container!="POD", container!=""}): 모든 컨테이너의 총 메모리 사용량
# sum(machine_memory_bytes): 클러스터 내 모든 노드의 총 메모리 용량
# 클러스터 전체의 메모리 사용률을 백분율로 표시
# 메모리 부족 상황 예측 및 대응에 유용
sum(container_memory_working_set_bytes{container!="POD", container!=""}) / sum(machine_memory_bytes) * 100
✅ 노드 대시보드 패턴
노드 수준의 리소스와 상태를 모니터링하는 대시보드:
- 노드 상태 개요
- 노드 상태 (Ready, NotReady)
- 노드별 파드 수
- 노드 리소스 사용률 비교
- 노드별 리소스 사용량
- CPU 사용량 및 로드
- 메모리 사용량 및 압력
- 디스크 I/O 및 사용량
- 노드 네트워크 및 시스템
- 네트워크 트래픽 및 오류
- 시스템 로드 및 프로세스 수
- 파일 디스크립터 및 소켓 상태
# 노드별 파드 수
# kube_pod_info: 파드 정보 메트릭
# count by (node): 노드별로 파드 수 계산
# 각 노드의 워크로드 분포 상태 파악 가능
# 노드 간 불균형 감지에 유용
count by (node) (kube_pod_info)
# 노드별 CPU 사용률 히트맵
# avg by (instance) (1 - rate(node_cpu_seconds_total{mode="idle"}[5m])): 노드별 평균 CPU 사용률
# 히트맵을 통해 시간에 따른 노드별 CPU 사용률 패턴 시각화
# 갑작스러운 사용량 증가나 특정 노드의 지속적 부하 감지 가능
avg by (instance) (1 - rate(node_cpu_seconds_total{mode="idle"}[5m]))
✅ 워크로드 대시보드 패턴
네임스페이스, 디플로이먼트, 파드 등의 워크로드를 모니터링하는 대시보드:
- 네임스페이스 개요
- 네임스페이스별 리소스 사용량
- 네임스페이스별 파드 상태
- 쿼터 사용률
- 디플로이먼트 및 스테이트풀셋
- 레플리카 상태 및 가용성
- 롤아웃 상태 및 이력
- 스케일링 이벤트
- 파드 성능 및 건강성
- 상위 CPU/메모리 사용 파드
- 재시작 횟수가 많은 파드
- OOM 킬 이벤트
# 네임스페이스별 리소스 요청 vs 사용량
# sum by (namespace) (kube_pod_container_resource_requests_cpu_cores): 각 네임스페이스의 총 CPU 요청량
# sum by (namespace) (rate(container_cpu_usage_seconds_total{container!="POD", container!=""}[5m])): 각 네임스페이스의 실제 CPU 사용량
# 리소스 요청과 실제 사용량 간의 차이 확인
# 리소스 할당 최적화에 유용
# CPU 요청량
sum by (namespace) (kube_pod_container_resource_requests_cpu_cores)
# CPU 사용량
sum by (namespace) (rate(container_cpu_usage_seconds_total{container!="POD", container!=""}[5m]))
# OOM 킬 이벤트 감지
# kube_pod_container_status_last_terminated_reason{reason="OOMKilled"}: OOM으로 종료된 컨테이너
# 최근 OOM 킬 이벤트 발생 파드/컨테이너 식별
# 메모리 제한 조정 및 메모리 누수 문제 해결에 필요한 정보 제공
kube_pod_container_status_last_terminated_reason{reason="OOMKilled"} == 1
📌 Grafana 대시보드 모범 사례
효과적인 Grafana 대시보드를 구축하기 위한 모범 사례와 팁을 알아보겠습니다.
✅ 디자인 원칙
사용자 경험을 고려한 대시보드 디자인 원칙:
- 일관성
- 일관된 색상 코딩 (빨간색 = 문제, 녹색 = 정상)
- 동일한 지표에 동일한 단위 및 스케일 사용
- 대시보드 간 일관된 레이아웃 유지
- 명확성
- 패널 제목과 설명 명확하게 작성
- 축 레이블과 단위 표시
- 범례 위치와 형식 최적화
- 중요도 기반 계층화
- 중요한 정보는 상단 또는 중앙에 배치
- 자주 사용하는 필터 및 변수는 눈에 잘 띄게 배치
- 세부 정보는 드릴다운 방식으로 제공
- 시각적 효율성
- 한 화면에 너무 많은 패널 피하기
- 관련 정보 그룹화
- 정보 과부하 방지 (필요한 정보만 포함)
✅ 성능 최적화
대시보드 로딩 및 렌더링 성능 최적화:
- 쿼리 최적화
- 너무 넓은 시간 범위 피하기
- 집계 함수 사용 (sum, avg, max 등)
- 불필요한 고해상도 데이터 피하기 (rate 대신 increase 고려)
- 패널 수 최적화
- 단일 대시보드에 20개 이하의 패널 권장
- 반복 패널 사용 시 변수 선택 제한
- 필요한 경우 대시보드 분리
- 시간 범위 설정
- 기본 시간 범위 적절히 설정 (일반적으로 3-6시간)
- 자동 리프레시 간격 조정 (30초 이상 권장)
- 상대 시간 사용 (now-3h to now)
- 브라우저 리소스 사용 고려
- 복잡한 그래프보다 단순한 시각화 선호
- 많은 데이터 포인트를 표시하는 히트맵 사용 주의
- 대시보드 로딩 시간 모니터링
✅ 대시보드 유지 관리
지속적인 대시보드 개선 및 유지 관리:
- 문서화
- 대시보드 설명 추가
- 패널 설명 및 도움말 추가
- 사용된 쿼리와 계산 방식 주석 처리
- 정기적인 검토
- 주기적으로 대시보드 정확성 검증
- 더 이상 사용되지 않는 패널/변수 제거
- 새로운 메트릭 및 요구사항 반영
- 버전 관리
- 중요한 변경 전 스냅샷 또는 JSON 백업
- 대시보드 변경 로그 유지
- 공유 대시보드 변경 시 팀 공지
- 자동화
- 코드로서의 대시보드 관리
- 대시보드 프로비저닝 활용
- CI/CD 파이프라인과 통합
📌 Summary
이번 포스트에서는 Grafana 대시보드 생성 및 커스터마이징에 대해 자세히 알아보았습니다. 다음과 같은 내용을 다루었습니다:
- Grafana 대시보드 기본 개념: 대시보드의 구조와 기본 구성 요소에 대한 이해를 통해 효과적인 대시보드 설계의 기반을 마련했습니다. 패널, 행, 변수, 주석 등의 주요 요소와 대시보드 JSON 구조에 대해 배웠습니다.
- 다양한 패널 유형과 활용법: 시계열 그래프, 게이지, 통계 패널, 테이블, 히트맵 등 다양한 패널 유형의 특징과 적절한 사용 사례를 이해했습니다. 각 패널 유형별 설정 방법과 최적화 기법을 익혔습니다.
- 효과적인 Prometheus 쿼리 작성: PromQL의 기본 구조와 집계 함수, 시계열 함수, 히스토그램 함수 등을 활용하여 효과적인 쿼리를 작성하는 방법을 배웠습니다. 복잡한 분석과 시각화를 위한 고급 쿼리 기법도 함께 살펴보았습니다.
- 변수와 템플릿을 활용한 동적 대시보드: 쿼리 변수, 사용자 정의 변수, 종속 변수 등 다양한 변수 유형과 설정 방법을 알아보았습니다. 이를 통해 사용자가 동적으로 데이터를 필터링하고 다양한 뷰를 제공할 수 있는 대시보드를 구성하는 방법을 배웠습니다.
- 고급 대시보드 테크닉: 주석, 임계값, 알림 설정, 값 매핑, 단위 설정 등의 고급 기능을 활용하여 대시보드의 정보 전달력을 높이는 방법을 배웠습니다. 또한 레이아웃 최적화, 대시보드 공유 및 내보내기, 버전 관리 등의 실용적인 기법도 살펴보았습니다.
- 쿠버네티스 모니터링을 위한 대시보드 패턴: 계층적 대시보드 구조와 클러스터 개요, 노드, 워크로드 대시보드 패턴을 통해 쿠버네티스 환경에 최적화된 모니터링 시스템을 구축하는 방법을 배웠습니다.
- Grafana 대시보드 모범 사례: 일관성, 명확성, 중요도 기반 계층화, 시각적 효율성 등의 디자인 원칙과 쿼리 최적화, 패널 수 최적화, 시간 범위 설정 등의 성능 최적화 기법을 통해 효과적인 대시보드를 구성하는 방법을 알아보았습니다.
'Observability > Prometheus' 카테고리의 다른 글
| EP13 [Part 5: 애플리케이션 레벨 모니터링] 다양한 애플리케이션 익스포터 소개 (0) | 2025.03.24 |
|---|---|
| EP12 [Part 4: Grafana 대시보드 마스터하기] 대시보드 베스트 프랙티스 (0) | 2025.03.24 |
| EP10 [Part 4: Grafana 대시보드 마스터하기] Grafana 설치 및 기본 설정 (0) | 2025.03.24 |
| EP09 [Part 3: 클러스터 모니터링 깊게 들여다보기] 네트워크 및 시스템 메트릭 분석 (0) | 2025.03.24 |
| EP08 [Part 3: 클러스터 모니터링 깊게 들여다보기] 파드와 네임스페이스 리소스 추적 (0) | 2025.03.23 |