이번 글에서는 Grafana 대시보드 시리즈의 마지막 파트로, 효과적인 대시보드 설계와 관리를 위한 베스트 프랙티스를 심도 있게 다루겠습니다. 이전 글에서 배운 Grafana 설치와 대시보드 생성 지식을 바탕으로, 이제는 실제 프로덕션 환경에서 활용할 수 있는 고급 테크닉과 조직 차원의 대시보드 관리 방법론을 알아보겠습니다.
📌 효과적인 대시보드 설계 원칙
성공적인 대시보드는 단순히 데이터를 표시하는 것 이상의 가치를 제공합니다. 효과적인 대시보드를 설계하기 위한 핵심 원칙을 알아보겠습니다.
✅ 목적 기반 설계
모든 대시보드는 명확한 목적을 가져야 합니다:
- 사용자 중심 접근법
- 대시보드의 주 사용자는 누구인가? (운영팀, 개발자, 관리자 등)
- 사용자가 이 대시보드를 통해 얻고자 하는 인사이트는 무엇인가?
- 어떤 결정을 내리는 데 도움이 되어야 하는가?
- 문제 해결 지향
- 특정 질문에 답할 수 있는 대시보드 구성
- "이 서비스의 현재 상태는 어떤가?"
- "어디서 병목 현상이 발생하는가?"
- "언제 리소스를 확장해야 하는가?"
- 컨텍스트 제공
- 데이터 그 자체보다 그 의미를 전달
- 임계값과 목표치를 시각적으로 표시
- 과거 추세와 함께 현재 상태 비교
▶️ 실제 사례: 한 기업은 수십 개의 범용 대시보드 대신, "서비스 상태", "용량 계획", "성능 분석", "비용 최적화"와 같이 특정 목적에 맞춘 4개의 핵심 대시보드로 재구성했습니다. 그 결과 대시보드 사용률이 250% 증가했고, 문제 해결 시간이 40% 단축되었습니다.
✅ 정보 계층화
정보를 효과적으로 계층화하여 인지 부하를 줄이고 중요한 인사이트를 강조합니다:
- 최상위 레벨
- 핵심 상태 지표 (서비스 상태, 주요 KPI)
- 이상 징후 및 경고 요약
- 전체 시스템 건강 상태
- 중간 레벨
- 구성요소별 세부 메트릭
- 추세 및 패턴 분석
- 리소스 사용량 및 성능 지표
- 세부 레벨
- 상세 진단 정보
- 로그 및 이벤트 연관 관계
- 원인 분석을 위한 세부 데이터
✅ 일관된 시각적 언어
대시보드 전반에 걸쳐 일관된 시각적 언어를 사용하면 정보 이해와 해석이 용이해집니다:
- 색상 표준화
- 상태 표시: 녹색(정상), 노란색(주의), 빨간색(경고)
- 데이터 유형별 일관된 색상 스키마
- 접근성을 고려한 색상 선택 (색맹 친화적)
- 레이아웃 패턴
- 유사한 정보는 동일한 위치에 배치
- 그리드 시스템을 활용한 질서 있는 배열
- 관련 패널 그룹화 및 논리적 배치
- 일관된 단위 및 스케일
- 동일한 메트릭에는 동일한 단위 사용
- 데이터 비교가 용이하도록 스케일 표준화
- 시간 범위 일관성 유지
▶️ 시각적 표준화 예시: 리소스 사용량은 항상 게이지 차트로, 시간에 따른 변화는 선 그래프로, 분포는 히트맵으로 표현하는 등 데이터 유형에 따라 일관된 시각화 방식을 적용합니다.
📌 대시보드 조직화 및 관리
여러 대시보드를 효과적으로 조직화하고 관리하는 것은 확장 가능한 모니터링 시스템을 구축하는 데 중요합니다.
✅ 대시보드 네이밍 및 폴더 구조
체계적인 명명 규칙과 폴더 구조를 통해 대시보드를 효율적으로 관리합니다:
- 명명 규칙
- [팀]-[애플리케이션]-[목적] 형식 사용
- 예: platform-kubernetes-node-health
- 검색 및 필터링이 용이한 일관된 접두사 사용
- 폴더 구조
- 팀 또는 서비스 단위 최상위 폴더
- 목적 또는 사용 사례별 하위 폴더
- 접근 권한 관리와 연계된 구조
# 대시보드 폴더 구조 예시
# - 최상위 폴더: 조직 또는 시스템의 주요 영역 구분
# - 중간 폴더: 특정 구성 요소 또는 서브시스템
# - 하위 폴더: 목적이나 관점별 대시보드 그룹
# 이러한 계층적 구조는 대시보드 탐색과 관리를 용이하게 함
# 권한 관리도 폴더 단위로 적용 가능하여 관리 효율성 향상
- Platform
|- Kubernetes Cluster
|- Overview # 클러스터 전반적인 상태 대시보드
|- Nodes # 노드 수준 모니터링 대시보드
|- Workloads # 워크로드 관련 대시보드
|- Networking
|- Ingress # 인그레스 컨트롤러 모니터링
|- Service Mesh # 서비스 메시 성능 및 상태
|- Storage
|- Persistent Volumes # 스토리지 용량 및 성능
- Applications
|- Microservices
|- Service A # 서비스 A 전용 대시보드
|- Service B # 서비스 B 전용 대시보드
|- Databases
|- MySQL # MySQL 데이터베이스 모니터링
|- PostgreSQL # PostgreSQL 성능 및 상태
- Business KPIs
|- User Engagement # 사용자 활동 지표
|- Performance # 비즈니스 성능 지표
- 태그 시스템
- 대시보드에 관련 태그 적용
- 예: kubernetes, production, node, monitoring
- 교차 검색 및 필터링 기능 강화
✅ 대시보드 템플릿 및 재사용
비슷한 구조의 대시보드를 반복적으로 만들지 않고 템플릿을 활용하여 일관성과 효율성을 높입니다:
- 대시보드 라이브러리 구축
- 기본 레이아웃과 패널 세트 정의
- 공통 변수 및 쿼리 템플릿 설정
- 조직 표준에 맞는 디자인 요소 포함
- 변수 활용 극대화
- 최대한 하드코딩 피하기
- 환경, 클러스터, 서비스 등을 변수로 설정
- 템플릿 변수와 반복 패널 조합
# 대시보드 템플릿 변수 설정 예시 (JSON 형식)
"templating": {
"list": [
{
"name": "cluster", // 변수 이름 - $cluster로 참조 가능
"type": "query", // 쿼리 기반 변수 타입
"datasource": "Prometheus", // 데이터 소스 지정
"query": "label_values(kube_node_info, cluster)", // 클러스터 목록 가져오는 쿼리
"current": {
"selected": true, // 현재 선택 상태
"text": "production", // UI에 표시되는 텍스트
"value": "production" // 실제 변수 값
},
"refresh": 1 // 변수 새로고침 정책 (1: 대시보드 로드 시)
},
{
"name": "namespace", // 네임스페이스 변수
"type": "query", // 쿼리 타입
"datasource": "Prometheus", // 데이터 소스
"query": "label_values(kube_namespace_status_phase{cluster=\"$cluster\"}, namespace)", // 선택된 클러스터의 네임스페이스 목록
"current": {
"selected": true, // 선택 상태
"text": "All", // "All" 옵션 표시
"value": "$__all" // 모든 값 선택 ($__all은 Grafana 내장 변수)
},
"includeAll": true, // "All" 옵션 포함
"refresh": 1 // 대시보드 로드 시 새로고침
}
]
}
- 라이브러리 패널 활용
- 자주 사용하는 패널을 라이브러리 패널로 저장
- 여러 대시보드에서 동일 패널 재사용
- 중앙 업데이트로 일관성 유지
# Grafana API를 사용한 라이브러리 패널 생성
# curl: 명령줄 HTTP 클라이언트 도구
# -X POST: HTTP POST 요청 지정
# -H "Authorization: Bearer $GRAFANA_API_KEY": API 키를 사용한 인증
# -H "Content-Type: application/json": JSON 형식 콘텐츠 지정
# -d '...': JSON 형식의 요청 본문
# 라이브러리 패널 정보:
# - name: 패널 이름 (라이브러리에서 표시됨)
# - model: 패널 구성 (시각화 타입, 데이터 소스, 쿼리 등)
# 이렇게 생성된 라이브러리 패널은 여러 대시보드에서 재사용 가능
curl -X POST \
-H "Authorization: Bearer $GRAFANA_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"name": "Node Resource Usage", # 라이브러리 패널 이름
"model": {
"datasource": "Prometheus", # 데이터 소스 지정
"description": "Shows CPU, Memory and Disk usage for nodes", # 패널 설명
"fieldConfig": {...}, # 필드 구성 (단위, 색상 등)
"options": {...}, # 패널 옵션 (범례, 축 등)
"targets": [...] # 쿼리 타겟 (Prometheus 쿼리)
}
}' \
https://grafana.example.com/api/library-elements
✅ 버전 관리 및 CI/CD 통합
대시보드를 코드로 관리하여 변경 추적, 검토 및 자동화된 배포를 구현합니다:
- 대시보드 as Code
- JSON 형식으로 대시보드 정의
- Git 저장소에서 버전 관리
- 코드 리뷰 프로세스 적용
- 자동화된 배포 파이프라인
- CI/CD 파이프라인과 연동
- 대시보드 변경사항 자동 검증 및 배포
- 다중 환경 지원 (개발, 스테이징, 프로덕션)
# GitLab CI/CD 파이프라인 예시 (.gitlab-ci.yml)
# 대시보드 JSON 파일을 검증하고 Grafana에 자동 배포하는 파이프라인
# stages: 파이프라인 단계 정의
# validate_dashboards: JSON 유효성 검증 작업
# deploy_dashboards: Grafana API를 통한 배포 작업
stages:
- validate # 검증 단계
- deploy # 배포 단계
validate_dashboards:
stage: validate # 검증 단계에서 실행
image: alpine:latest # Alpine Linux 이미지 사용
script:
- apk add --no-cache jq curl # jq(JSON 처리 도구)와 curl 설치
- for file in dashboards/*.json; do # 모든 대시보드 JSON 파일 순회
- jq empty "$file" || (echo "Invalid JSON in $file" && exit 1) # JSON 유효성 검사
- done
- echo "All dashboard JSON files are valid" # 모든 파일 검증 성공 메시지
deploy_dashboards:
stage: deploy # 배포 단계에서 실행
image: curlimages/curl:latest # curl 이미지 사용
script:
- for file in dashboards/*.json; do # 모든 대시보드 JSON 파일 순회
- dashboard=$(cat "$file") # 파일 내용 읽기
- curl -X POST -H "Authorization: Bearer $GRAFANA_API_KEY" # Grafana API 호출
-H "Content-Type: application/json"
-d "{\"dashboard\": $dashboard, \"overwrite\": true}" # 대시보드 데이터와 덮어쓰기 옵션
"$GRAFANA_URL/api/dashboards/db" # Grafana API 엔드포인트
- done
only:
- master # master 브랜치에만 적용
environment:
name: production # 프로덕션 환경으로 지정
- 변경 관리 및 롤백
- 대시보드 변경 내역 기록
- 문제 발생 시 이전 버전으로 롤백 메커니즘
- 대시보드 변경사항 문서화
▶️ 프랙티스 사례: 한 기업은 대시보드를 코드로 관리하는 GitOps 접근 방식을 도입하여, 주간 릴리스 프로세스의 일부로 대시보드 업데이트를 자동화했습니다. 이로 인해 대시보드 관리 시간이 75% 감소하고, 모든 환경에서 일관된 모니터링 경험을 제공할 수 있게 되었습니다.
📌 고급 시각화 테크닉
표준 패널을 넘어서 고급 시각화 기법을 활용하여 더 효과적으로 데이터를 전달합니다.
✅ 데이터 시각화 모범 사례
올바른 시각화 유형 선택과 디자인으로 데이터의 의미를 명확하게 전달합니다:
- 목적에 맞는 시각화 선택
- 추세 분석: 선 그래프
- 비교: 막대 그래프
- 구성: 파이/도넛 차트
- 분포: 히트맵/히스토그램
- 관계: 산점도
- 데이터-잉크 비율 최적화
- 불필요한 시각적 요소 제거
- 데이터에 초점을 맞춘 간결한 디자인
- 과도한 장식 지양
- 인지 부하 감소
- 한 패널에 표시하는 시계열 수 제한 (5-7개 이하)
- 명확한 레이블과 범례
- 적절한 간격과 여백 사용

✅ 복잡한 데이터 표현 전략
복잡하고 다차원적인 데이터를 효과적으로 시각화하는 전략:
- 다중 Y축 활용
- 다른 단위의 관련 메트릭 함께 표시
- 예: CPU 사용률(%)과 로드(절대값) 비교
- 색상 코딩으로 축 구분
# 다중 Y축 패널 설정 예시
# 서로 다른 단위나 스케일을 가진 지표를 하나의 그래프에 표시
# 왼쪽 Y축(첫 번째): CPU 사용률(%)
# 오른쪽 Y축(두 번째): 시스템 로드(절대값)
# 각 축에 대한 레이블, 형식, 범위 설정 가능
# 사용자가 관련 지표들을 한 번에 비교할 수 있게 해줌
panelOptions:
yaxes:
- format: percentunit # 첫 번째 Y축: 백분율 형식
label: CPU Usage # 축 레이블
min: 0 # 최소값 0
max: 1 # 최대값 1 (100%)
show: true # 축 표시 여부
- format: short # 두 번째 Y축: 일반 숫자 형식
label: Load # 축 레이블
min: 0 # 최소값 0
show: true # 축 표시 여부
- 히트맵 최적화
- 히스토그램 버킷 설정 최적화
- 색상 스키마 신중 선택 (연속형 데이터에 적합한 스키마)
- 너비와 높이 비율 조정
# 효과적인 히트맵을 위한 히스토그램 쿼리
# histogram_quantile(): 히스토그램 백분위수 계산 함수
# le: less than or equal (히스토그램 버킷 상한값)
# increase(): 지정 기간 동안의 증가량
# [5m]: 5분 간격으로 계산
# job="api-server": API 서버 메트릭만 선택
# sum by (le): 버킷(le)별로 합산
# 결과: 5분 간격으로 응답 시간 분포를 보여주는 히트맵 데이터
# 연속적인 시간 범위에서 응답 시간 분포 패턴 파악 가능
sum(increase(http_request_duration_seconds_bucket{job="api-server"}[5m])) by (le)
- 상태 타임라인
- 시간에 따른 상태 변화 시각화
- 색상으로 상태 인코딩 (정상, 경고, 오류 등)
- 중요 이벤트 주석 추가
# 상태 타임라인을 위한 쿼리 예시
# kube_pod_status_phase: 파드 상태 메트릭
# phase: 파드 상태 (Running, Pending, Failed 등)
# namespace="$namespace": 선택한 네임스페이스의 파드만 필터링
# sum by (phase): 상태별로 파드 수 집계
# 결과: 시간에 따른 각 상태(Running, Pending, Failed 등)의 파드 수 변화
# 타임라인 차트에서 색상으로 구분되어 상태 변화 추이 시각화
# 배포, 롤백, 장애 등의 이벤트 영향을 시각적으로 확인 가능
sum(kube_pod_status_phase{namespace="$namespace"}) by (phase)
✅ 인터랙티브 대시보드 구성
사용자가 데이터와 상호작용할 수 있는 인터랙티브 요소를 추가합니다:
- 데이터 드릴다운
- 패널 링크 활용
- 클릭 시 더 상세한 대시보드로 이동
- 컨텍스트(변수, 시간 범위) 유지 전달
# 패널 링크 설정 예시
# title: 링크 제목 (UI에 표시됨)
# url: 대상 대시보드 URL
# - /d/node-detail: 대시보드 UID
# - var-node=${__cell_name}: 선택한 셀 값을 노드 변수로 전달
# - from=${__from}&to=${__to}: 현재 시간 범위 유지
# targetBlank: 새 탭에서 열지 여부
# 이 설정으로 사용자가 패널의 특정 셀을 클릭하면
# 해당 노드의 상세 정보를 보여주는 대시보드로 이동
"links": [
{
"title": "Node Detail", // 링크 제목
"url": "/d/node-detail?var-node=${__cell_name}&from=${__from}&to=${__to}", // 대상 URL과 파라미터
"targetBlank": false // 현재 탭에서 열기
}
]
- 데이터 포인트 주석
- 중요 이벤트에 주석 추가
- 배포, 구성 변경, 장애 등 표시
- 컨텍스트 정보 제공
# Grafana 주석 쿼리 설정
# name: 주석 이름 (UI에 표시됨)
# datasource: 주석 데이터 소스 (일반적으로 Prometheus)
# expr: 주석을 생성할 이벤트를 찾는 Prometheus 쿼리
# - changes(): 값 변경 감지
# - kube_deployment_status_observed_generation: 디플로이먼트 변경 메트릭
# step: 주석 쿼리 실행 간격 (60초)
# titleFormat: 주석 제목 형식
# textFormat: 주석 내용 형식 (템플릿 변수 사용 가능)
# iconColor: 주석 아이콘 색상
annotations:
- name: Deployments # 주석 이름
datasource: Prometheus # 데이터 소스
expr: changes(kube_deployment_status_observed_generation{namespace="$namespace"}[1m]) > 0 # 디플로이먼트 변경 감지
step: 60s # 60초 간격으로 쿼리
titleFormat: "Deployment Changed" # 주석 제목
textFormat: "Deployment in namespace '{{namespace}}' changed" # 주석 내용 (변수 사용)
iconColor: "#5794F2" # 주석 아이콘 색상 (파란색)
- 동적 임계값
- 과거 데이터 기반 동적 임계값 설정
- 이상치 자동 감지 및 강조
- 계절성과 추세를 고려한 알림
# 동적 임계값 쿼리 예시
# avg_over_time(): 지정 기간 동안의 평균값 계산
# stddev_over_time(): 지정 기간 동안의 표준편차 계산
# [1d:1h]: 1일 기간을 1시간 간격으로 샘플링
# handler="/api/v1/query": 특정 API 엔드포인트에 대한 지표
# avg(...) + 2 * stddev(...): 평균 + 2*표준편차 (약 95% 신뢰구간 상한)
# 현재 값 (실제 측정된 응답 시간)
avg(rate(http_request_duration_seconds_sum{handler="/api/v1/query"}[5m]))
# 동적 상한 임계값 (평균 + 2*표준편차)
# 과거 1일 데이터의 통계를 기반으로 한 동적 임계값
# 정상 패턴과 추세를 고려한 임계값으로 거짓 경보 감소
# 시간에 따라 자동 조정되어 변화하는 패턴에 적응
avg_over_time(avg(rate(http_request_duration_seconds_sum{handler="/api/v1/query"}[5m]))[1d:1h])
+ 2 * stddev_over_time(avg(rate(http_request_duration_seconds_sum{handler="/api/v1/query"}[5m]))[1d:1h])
▶️ 고급 시각화 사례: Netflix는 동적 임계값을 활용한 이상 징후 감지 시스템을 구현하여 과거 평균과 표준편차를 기반으로 한 임계값을 자동으로 계산합니다. 이를 통해 거짓 경보를 70% 줄이고 실제 문제 감지율을 25% 향상시켰습니다.
📌 성능 최적화 전략
대시보드 성능은 사용자 경험에 직접적인 영향을 미치며, 특히 대규모 메트릭 데이터를 다룰 때 중요합니다.
✅ 쿼리 최적화
효율적인 PromQL 쿼리는 대시보드 로딩 시간과 Prometheus 서버 부하를 크게 줄일 수 있습니다:
- 쿼리 범위 제한
- 필요한 레이블만 선택
- 적절한 필터링 적용
- 불필요한 고해상도 데이터 지양
# 비효율적인 쿼리
# 모든 HTTP 요청의 평균 응답 시간 계산
# job이나 handler로 필터링하지 않아 모든 지표를 불러옴
# 불필요한 데이터 처리로 성능 저하 발생
rate(http_request_duration_seconds_sum[5m]) / rate(http_request_duration_seconds_count[5m])
# 최적화된 쿼리
# job="apiserver": API 서버 요청만 대상으로 함
# handler=~"/api/v1/.*": /api/v1/ 경로의 핸들러만 필터링
# 필요한 데이터만 정확히 지정하여 처리량 감소 및 성능 향상
rate(http_request_duration_seconds_sum{job="apiserver", handler=~"/api/v1/.*"}[5m])
/
rate(http_request_duration_seconds_count{job="apiserver", handler=~"/api/v1/.*"}[5m])
- 집계 및 기록 규칙 활용
- 복잡한 계산은 Prometheus 기록 규칙으로 사전 처리
- 자주 사용하는 집계 쿼리 최적화
- 시간 단위 집계로 데이터 양 감소
# Prometheus 기록 규칙 설정 예시
# groups: 규칙 그룹 (관련 규칙 모음)
# name: 그룹 이름
# rules: 실제 기록 규칙 목록
# record: 새로 생성될 메트릭 이름
# expr: 계산식 (PromQL 쿼리)
# 복잡한 집계 쿼리를 미리 계산하여 저장
# 대시보드에서는 단순히 미리 계산된 메트릭 사용
groups:
- name: k8s.rules # 규칙 그룹 이름
rules:
- record: instance:node_cpu_utilisation:rate5m # 새 메트릭 이름
expr: | # 계산식 (여러 줄)
sum without(mode) (
rate(node_cpu_seconds_total{mode!="idle"}[5m]) # 5분 간격 CPU 사용률
)
# 주석: 이 규칙은 모든 CPU 모드(idle 제외)의 사용률 합계를 계산
# 대시보드에서 복잡한 계산 없이 instance:node_cpu_utilisation:rate5m 메트릭 직접 사용 가능
- record: instance:node_memory_utilisation:ratio # 메모리 사용률 메트릭
expr: |
1 - (
node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes
)
# 주석: 사용 가능한 메모리와 전체 메모리 비율로 메모리 사용률 계산
- 샘플링 및 압축
- 장기 추세를 위한 데이터 다운샘플링
- 높은 시간 해상도가 필요 없는 경우 압축 활용
- 적절한 step 값 설정으로 데이터 포인트 수 제한
// Grafana 패널 데이터 옵션 설정 예시
// maxDataPoints: 패널당 최대 데이터 포인트 수 제한
// minInterval: 최소 데이터 포인트 간격 설정
// 이 설정은 쿼리 성능과 시각적 세부 사항 사이의 균형을 조정
// 패널 크기와 정밀도 요구 사항에 따라 적절히 조정
{
"options": {
"dataLinks": [], // 데이터 링크 설정 (없음)
},
"fieldConfig": {
"defaults": { // 기본 필드 설정
"custom": {}
}
},
"maxDataPoints": 500, // 패널당 최대 500개 데이터 포인트 표시
"minInterval": "1m", // 최소 1분 간격으로 데이터 샘플링
// 주석: 이 설정은 고해상도 데이터를 1분 간격으로 다운샘플링하여
// 데이터 전송량을 줄이고 렌더링 성능을 향상시킴
}
✅ 대시보드 로딩 속도 개선
대시보드 로딩 시간을 최적화하여 사용자 경험을 향상시킵니다:
- 패널 수 제한
- 대시보드당 15-20개 이하의 패널 유지
- 관련 정보를 논리적으로 그룹화
- 필요시 드릴다운 대시보드로 세부 정보 이동
- 느린 쿼리 최적화
- 대시보드 검사 도구로 느린 쿼리 식별
- 복잡한 정규 표현식 최소화
- 데이터 양이 많은 시계열 필터링
- 캐싱 및 선택적 새로고침
- 패널별 적절한 새로고침 간격 설정
- 변경이 적은 데이터는 더 긴 캐시 시간 적용
- 중요하지 않은 패널은 주문형 로딩으로 변경
# Grafana 서버 캐싱 설정 예시 (grafana.ini)
# enabled: 캐시 활성화 여부
# ttl: 캐시 유지 시간 (seconds)
# memory_store: 메모리 기반 캐싱 설정
# max_size_mb: 최대 캐시 크기 (MB)
# 이러한 설정으로 반복적인 쿼리 결과를 캐싱하여
# 데이터 소스 부하 감소 및 대시보드 성능 향상
[caching]
enabled = true # 캐싱 활성화
ttl = 60 # 60초 캐시 유지 시간
[caching.memory]
enabled = true # 메모리 캐싱 활성화
max_size_mb = 100 # 최대 100MB 캐시 사용
# 주석: 메모리 캐싱을 통해 자주 접근하는 쿼리 결과를 메모리에 저장
# 데이터 소스 부하 감소 및 응답 시간 단축
✅ 리소스 사용량 모니터링
Grafana 자체의 성능을 모니터링하여 지속적인 개선을 가능하게 합니다:
- Grafana 내부 메트릭 활용
- Grafana 프로메테우스 엔드포인트 활성화
- 대시보드 로딩 시간, 쿼리 성능 추적
- 메모리 및 CPU 사용량 모니터링
# Grafana 메트릭 설정 (grafana.ini)
# enabled: 메트릭 수집 활성화 여부
# basic_auth_username: 메트릭 엔드포인트 접근용 사용자 이름
# basic_auth_password: 메트릭 엔드포인트 접근용 비밀번호
# interval_seconds: 메트릭 수집 간격 (초)
# 이 설정으로 Grafana 자체의 성능 메트릭을 수집하여
# Grafana 인스턴스 성능 모니터링 및 최적화 가능
[metrics]
enabled = true # 메트릭 수집 활성화
basic_auth_username = admin # 기본 인증 사용자 이름
basic_auth_password = password # 기본 인증 비밀번호
interval_seconds = 10 # 10초 간격으로 메트릭 수집
[metrics.prometheus]
enabled = true # Prometheus 형식 메트릭 활성화
endpoint = /metrics # 메트릭 엔드포인트 경로
# 주석: /metrics 엔드포인트를 통해 Grafana 성능 메트릭 노출
# Prometheus로 수집하여 Grafana 자체 성능 모니터링 가능
- 성능 병목 식별
- 가장 느린 쿼리 및 패널 식별
- 대시보드 런타임 통계 분석
- 리소스 집약적 대시보드 최적화
▶️ 성능 최적화 사례: 한 대형 기업은 대시보드 성능 최적화 작업을 통해 평균 로딩 시간을 8초에서 2초로 단축했습니다. 주요 개선 사항으로는 복잡한 쿼리를 Prometheus 기록 규칙으로 대체하고, 패널 수를 줄이며, 데이터 포인트 수를 제한한 것이 포함되었습니다.
📌 팀 협업을 위한 대시보드 관리
대규모 팀이나 조직에서 대시보드를 효과적으로 관리하기 위한 전략을 알아봅니다.
✅ 대시보드 문서화
대시보드 목적과 사용법에 대한 명확한 문서화는 팀 협업의 기반입니다:
- 대시보드 설명
- 대시보드의 목적과 대상 사용자 명시
- 포함된 메트릭과 의미 설명
- 정상 범위와 비정상 패턴 안내
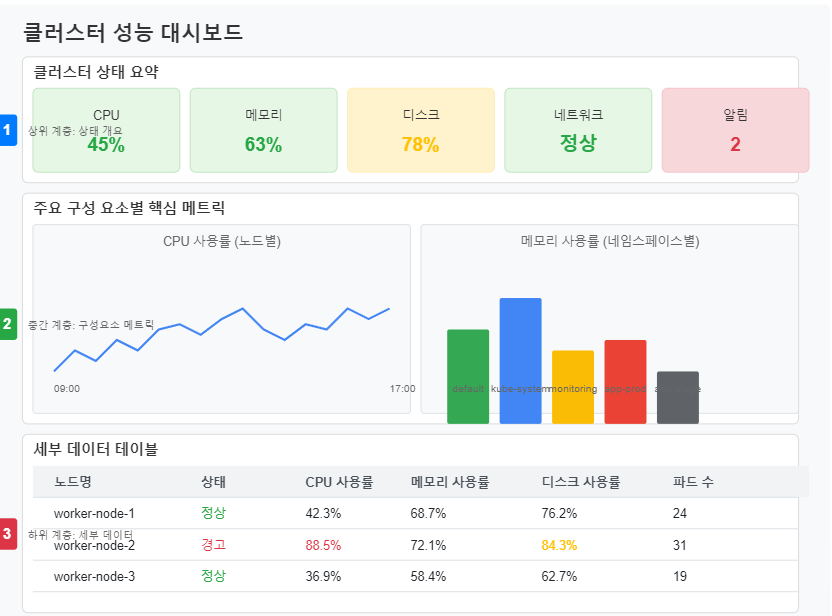
# 대시보드 설명 예시 (Markdown 형식)
## 클러스터 성능 대시보드
**목적**: 쿠버네티스 클러스터의 주요 성능 지표를 실시간으로 모니터링하고 성능 병목 현상을 신속하게 식별합니다.
**대상 사용자**: 클러스터 관리자, SRE 팀
**주요 메트릭**:
- **노드 CPU 사용률**: 80% 이상이면 조사 필요
- **메모리 사용률**: 85% 이상은 메모리 압박 상태
- **디스크 I/O**: 지속적으로 높은 값은 스토리지 병목 가능성
- **네트워크 트래픽**: 급격한 증가는 비정상 트래픽 가능성
**관련 알림**:
- NodeHighCPU: 노드 CPU 사용률 90% 이상 (5분)
- NodeMemoryPressure: 메모리 사용률 90% 이상 (10분)
**갱신 주기**: 30초
**데이터 보존**: 2주
- 패널 설명 및 주석
- 각 패널의 상세 목적
- 데이터 수집 및 계산 방법
- 해석 가이드 및 조치 방법
# 패널 설명 예시
# title: 패널 제목
# description: 패널 설명 (마크다운 지원)
# 각 패널에 명확한 설명을 추가하여 다른 팀원들이
# 대시보드를 더 잘 이해하고 활용할 수 있도록 지원
panel:
title: "노드 CPU 사용률" # 패널 제목
description: | # 설명 (여러 줄)
**이 패널은 무엇을 보여주나요?**
각 노드의 모든 코어에 대한 평균 CPU 사용률(%)을 표시합니다.
**계산 방법:**
`1 - avg(rate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance)`
**판단 기준:**
- <50%: 정상
- 50-80%: 주의
- >80%: 조사 필요, 자원 부족 가능성
**관련 알림:**
- NodeHighCPU (>90% for 5m)
**조치 방법:**
1. 어떤 프로세스가 CPU를 많이 사용하는지 확인
2. 필요시 워크로드 재분배 고려
3. 지속될 경우 노드 추가 검토
# 주석: 이런 상세한 설명은 다른 팀원이 대시보드를 이해하고
# 문제 상황에서 올바른 조치를 취할 수 있도록 도움
- 사용 가이드
- 대시보드 탐색 방법
- 변수 및 필터 사용법
- 일반적인 문제 해결 시나리오
✅ 접근 권한 및 공유 관리
대시보드의 효과적인 공유와 접근 제어를 통해 협업을 강화합니다:
- 역할 기반 접근 제어
- 팀 또는 역할별 권한 설정
- 뷰어, 편집자, 관리자 권한 구분
- 폴더 기반 접근 제어 구성
# Grafana 팀 및 권한 설정 예시
# [teams] 섹션: 팀 관련 설정
# teams_query_socket_timeout: 팀 정보 쿼리 타임아웃
# [auth.role_based_access_control] 섹션: RBAC 설정
# enabled: RBAC 활성화 여부
# 이러한 설정은 대규모 조직에서 대시보드 접근 권한을
# 체계적으로 관리하는 데 필수적
[teams]
enabled = true # 팀 기능 활성화
teams_query_socket_timeout = 30 # 팀 쿼리 타임아웃 30초
[auth.role_based_access_control]
enabled = true # RBAC 활성화
# 주석: 역할 기반 접근 제어로 팀원들에게 적절한 권한 부여
# 뷰어: 대시보드 보기만 가능
# 편집자: 대시보드 수정 가능
# 관리자: 폴더 및 권한 관리 가능
- 스냅샷 및 내보내기
- 특정 시점의 대시보드 상태 공유
- PDF, PNG 형식으로 보고서 내보내기
- 외부 시스템과 통합
# Grafana API를 사용한 대시보드 내보내기 스크립트
# curl: 명령줄 HTTP 클라이언트
# -H "Authorization: Bearer $API_KEY": API 키 인증
# jq: JSON 처리 도구로 응답 데이터 가공
# $DASHBOARD_UID: 내보낼 대시보드 고유 ID
# $GRAFANA_URL: Grafana 서버 URL
# 이 스크립트는 대시보드를 JSON 파일로 내보내고,
# 필요한 경우 CI/CD 파이프라인이나 자동화에 활용 가능
#!/bin/bash
# 환경 변수 설정
GRAFANA_URL="https://grafana.example.com"
API_KEY="eyJrIjoiT0tTcG1pUlQ2RnVKZTFVaDFsNFZXdE9ZWmNrMkZYbk"
DASHBOARD_UID="abc123"
OUTPUT_FILE="dashboard_export.json"
# 대시보드 내보내기
curl -s -H "Authorization: Bearer $API_KEY" \
"$GRAFANA_URL/api/dashboards/uid/$DASHBOARD_UID" | \
jq '.dashboard' > $OUTPUT_FILE
# 결과 확인
echo "대시보드가 $OUTPUT_FILE 파일로 내보내기 되었습니다."
# 주석: 이 스크립트는 지정된 대시보드를 JSON 형식으로 내보내
# 버전 관리, 백업, 다른 환경으로 이전 등에 활용 가능
- 공유 가능한 URL 생성
- 시간 범위, 변수 설정이 포함된 URL
- 임시 공개 URL (인증 없이 접근 가능)
- 임베디드 대시보드 URL
✅ 피드백 및 개선 프로세스
대시보드 품질을 지속적으로 향상시키기 위한 피드백 순환 구조를 만듭니다:
- 대시보드 리뷰 세션
- 정기적인 대시보드 리뷰 회의
- 사용자 경험 및 개선점 논의
- 새로운 요구사항 수집
- 버전 관리 및 변경 이력
- 대시보드 변경사항 추적
- 주요 업데이트 문서화
- 변경 이유 및 영향 기록
- 지속적인 개선
- 사용 패턴 분석
- 불필요한 패널 제거 또는 개선
- 새로운 시각화 기법 적용
▶️ 팀 협업 사례: 글로벌 기업의 SRE 팀은 "대시보드 챔피언" 역할을 도입하여 각 팀에서 한 명이 대시보드 품질과 표준화를 담당하도록 했습니다. 월간 대시보드 리뷰 세션을 통해 팀 간 지식 공유와 지속적인 개선이 이루어지며, 대시보드의 문서화 수준과 사용성이 크게 향상되었습니다.
📌 Summary
- 대시보드 목적 중심 설계: 효과적인 Grafana 대시보드는 명확한 목적을 가지고 설계되어야 합니다. 데이터를 단순히 보여주는 것이 아니라 실질적인 인사이트를 제공하는 도구로 활용해야 합니다.
- 정보의 계층적 구성: 핵심 정보부터 세부 데이터까지 자연스러운 흐름으로 배치하면 사용자가 직관적으로 필요한 정보를 찾을 수 있습니다. 이는 인지 부하를 줄이고 의사결정 속도를 높여줍니다.
- 일관된 시각적 언어: 표준화된 색상 체계, 레이아웃 패턴, 시각화 유형을 사용하면 대시보드 해석이 더 쉬워집니다. 특히 상태 표시와 데이터 유형별 시각화 방식의 일관성이 중요합니다.
- 체계적인 대시보드 관리: 명확한 네이밍 규칙과 폴더 구조, 태그 시스템을 통해 대시보드를 효율적으로 관리할 수 있습니다. 템플릿과 라이브러리 패널 활용은 일관성과 재사용성을 높여줍니다.
- 대시보드를 코드로 관리: Git 저장소에서 JSON 형식으로 대시보드를 관리하고 CI/CD 파이프라인과 연동하면 변경 추적과 자동 배포가 가능해집니다. 이는 대시보드 품질과 협업 효율성을 크게 향상시킵니다.
- 쿼리 및 성능 최적화: 효율적인 PromQL 쿼리 작성, 기록 규칙 활용, 적절한 데이터 샘플링으로 대시보드 로딩 시간을 최소화하고 Prometheus 서버의 부하를 줄일 수 있습니다.
- 고급 시각화 테크닉: 데이터 특성에 맞는 시각화 유형 선택, 다중 Y축, 히트맵 최적화, 상태 타임라인 등의 기법을 활용하면 복잡한 데이터도 효과적으로 전달할 수 있습니다.
- 팀 협업을 위한 전략: 대시보드 문서화, 역할 기반 접근 제어, 정기적인 리뷰 세션을 통해 대시보드의 가치를 지속적으로 높이고 팀 전체의 효율성을 개선할 수 있습니다.
'Observability > Prometheus' 카테고리의 다른 글
| EP14 [Part 5: 애플리케이션 레벨 모니터링] 데이터베이스 모니터링 (MySQL, PostgreSQL) (0) | 2025.03.24 |
|---|---|
| EP13 [Part 5: 애플리케이션 레벨 모니터링] 다양한 애플리케이션 익스포터 소개 (0) | 2025.03.24 |
| EP11 [Part 4: Grafana 대시보드 마스터하기] 대시보드 생성 및 커스터마이징 (0) | 2025.03.24 |
| EP10 [Part 4: Grafana 대시보드 마스터하기] Grafana 설치 및 기본 설정 (0) | 2025.03.24 |
| EP09 [Part 3: 클러스터 모니터링 깊게 들여다보기] 네트워크 및 시스템 메트릭 분석 (0) | 2025.03.24 |