이번 글에서는 프로메테우스와 그라파나를 활용한 Observability 구성 시리즈의 여섯 번째 포스트로, 효과적인 로그 관리와 표준화 방법, 그리고 최적의 로깅 시스템을 구축하는 방법에 대해 알아보겠습니다.
📌 로그의 중요성과 역할
로그(Logs)는 Observability의 세 가지 핵심 요소(메트릭, 로그, 트레이스) 중 하나로, 시스템에서 발생하는 이벤트를 시간 순서대로 기록한 데이터입니다. 로그는 시스템의 상태와 동작을 이해하고 문제를 진단하는 데 필수적인 정보를 제공합니다.
✅ 로그의 기본 개념
▶️ 로그의 정의:
로그는 애플리케이션이나 시스템에서 발생하는 이벤트를 기록한 텍스트 메시지입니다. 각 로그 항목은 일반적으로 타임스탬프, 로그 레벨, 소스(출처), 메시지 등의 정보를 포함합니다.
▶️ 로그의 유형:
- 애플리케이션 로그: 애플리케이션 코드에서 생성되는 로그 (예: 비즈니스 로직, 오류, 경고)
- 시스템 로그: 운영 체제나 인프라 구성 요소에서 생성되는 로그 (예: syslog, 커널 로그)
- 액세스 로그: 서비스에 대한 요청과 응답을 기록하는 로그 (예: 웹 서버 액세스 로그)
- 감사 로그: 보안 관련 이벤트와 활동을 기록하는 로그 (예: 로그인 시도, 권한 변경)

✅ 로그의 역할과 중요성
▶️ 문제 해결과 디버깅:
로그는 오류가 발생했을 때 문제의 원인을 파악하는 데 필수적인 정보를 제공합니다. 스택 트레이스, 오류 메시지, 컨텍스트 정보 등을 통해 개발자가 문제를 신속하게 해결할 수 있도록 도와줍니다.
▶️ 행동 분석과 이해:
로그는 시스템이 어떻게 동작하는지, 사용자가 어떻게 서비스를 이용하는지에 대한 통찰력을 제공합니다. 이를 통해 시스템 동작을 이해하고 개선할 수 있습니다.
▶️ 보안 모니터링:
로그는 비정상적인 접근 시도, 권한 변경, 중요 데이터 접근 등을 기록하여 보안 위협을 감지하고 대응하는 데 도움을 줍니다.
▶️ 규제 준수:
많은 산업에서는 특정 활동을 기록하고 로그를 일정 기간 보관하는 것이 규제 요구사항입니다. 로그는 이러한 규제 준수를 위한 증거 자료로 활용됩니다.
▶️ 트렌드 분석:
장기간에 걸친 로그 데이터 분석은 시스템 성능 트렌드, 사용자 행동 패턴 등을 파악하는 데 유용합니다.
📌 효과적인 로깅 전략
효과적인 로깅 전략은 시스템의 가시성을 높이고 문제 해결을 용이하게 만듭니다. 로깅 시스템을 구축할 때 고려해야 할 주요 사항들을 살펴보겠습니다.
✅ 로그 레벨과 용도
로그 메시지는 일반적으로 여러 레벨로 분류되며, 각 레벨은 로그 메시지의 중요도와 용도를 나타냅니다.
▶️ 주요 로그 레벨:
- TRACE: 매우 상세한 디버깅 정보, 개발 환경에서만 사용
- DEBUG: 디버깅 목적의 상세 정보, 개발 및 테스트 환경에서 유용
- INFO: 일반적인 정보성 메시지, 중요한 이벤트 기록
- WARN: 잠재적 문제나 비정상적 상황을 나타내는 경고
- ERROR: 오류 발생, 일부 기능이 동작하지 않을 수 있음
- FATAL/CRITICAL: 치명적인 오류, 시스템 중단 가능성
// Java에서의 로그 레벨 사용 예시 (Log4j2)
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
public class UserService {
// 클래스별 로거 인스턴스 생성 - 로거 이름으로 클래스 이름 사용은 모범 사례
private static final Logger logger = LogManager.getLogger(UserService.class);
public User findUserById(String userId) {
// TRACE: 매우 상세한 디버깅 정보, 개발 환경에서만 사용
// 메서드 호출 시작과 같은 매우 세부적인 정보
logger.trace("findUserById 메서드 호출: userId={}", userId);
try {
// DEBUG: 개발/테스트 환경에서 문제 해결에 유용한 정보
// 파라미터 값, DB 쿼리 실행 전 로깅 등
logger.debug("사용자 조회 시작: userId={}", userId);
User user = userRepository.findById(userId);
if (user == null) {
// WARN: 잠재적 문제나 예상치 못한 상황, 하지만 프로그램은 계속 실행 가능
// 사용자가 없는 경우는 오류는 아니지만 주의가 필요한 상황
logger.warn("ID에 해당하는 사용자 없음: userId={}", userId);
return null;
}
// INFO: 중요한 이벤트 또는 상태 변경, 운영 환경에서도 사용
// 성공적인 작업 완료, 중요 이벤트 발생 등을 기록
logger.info("사용자 조회 성공: userId={}, username={}", userId, user.getUsername());
return user;
} catch (DatabaseException e) {
// ERROR: 실제 오류 상황, 기능 일부가 실패했지만 애플리케이션은 계속 실행 가능
// 예외 객체를 직접 전달하면 스택 트레이스까지 자동으로 로깅됨
logger.error("사용자 조회 중 데이터베이스 오류 발생: userId={}", userId, e);
throw new ServiceException("사용자 조회 실패", e);
} catch (Exception e) {
// FATAL: 애플리케이션 전체 또는 핵심 기능이 완전히 실패한 치명적 오류
// 시스템 중단이 필요하거나 즉각적인 조치가 필요한 경우
logger.fatal("사용자 조회 중 치명적 오류 발생: userId={}", userId, e);
throw new SystemFailureException("시스템 장애", e);
}
}
}✅ 로그 형식과 구조화
로그의 형식과 구조는 로그 데이터의 가독성과 처리 용이성에 큰 영향을 미칩니다. 구조화된 로깅은 로그 데이터를 더 효과적으로 검색, 필터링, 분석할 수 있게 해줍니다.
▶️ 일반 텍스트 vs 구조화된 로그:
- 일반 텍스트 로그: 가독성은 좋지만 파싱과 분석이 어려움
- 구조화된 로그(JSON, XML 등): 기계적 처리가 용이하고, 필드별 검색과 필터링이 가능
# 일반 텍스트 로그 예시
[2023-03-15 14:22:33.456] [INFO] [UserService] - 사용자 '홍길동(user123)'이 로그인했습니다. IP: 192.168.1.100
# JSON 형식의 구조화된 로그 예시
{
"timestamp": "2023-03-15T14:22:33.456Z",
"level": "INFO",
"logger": "UserService",
"message": "사용자 로그인",
"data": {
"username": "홍길동",
"userId": "user123",
"ip": "192.168.1.100",
"action": "login"
}
}
▶️ 표준 로그 필드:
효과적인 로그 분석을 위해 모든 로그 메시지에 포함시켜야 할 표준 필드들입니다.
- 타임스탬프: 이벤트 발생 시간 (ISO 8601 형식 권장)
- 로그 레벨: 로그 메시지의 중요도 (INFO, ERROR 등)
- 소스/로거: 로그를 생성한 서비스, 클래스, 모듈
- 메시지: 이벤트에 대한 설명
- 컨텍스트 데이터: 요청 ID, 사용자 ID, 세션 ID 등
- 메타데이터: 환경, 버전, 호스트명 등
- 구조화된 데이터: 이벤트와 관련된 추가 정보 (JSON 객체 등)
# logstash 구성 예시 - 로그 형식 표준화
input {
# Filebeat로부터 로그 수신
beats {
port => 5044 # Filebeat가 로그를 전송할 포트
# SSL 설정을 추가할 수 있음
# ssl => true
# ssl_certificate => "/etc/logstash/ssl/logstash.crt"
# ssl_key => "/etc/logstash/ssl/logstash.key"
}
# Kafka로부터 로그 수신 (선택 사항)
kafka {
bootstrap_servers => "kafka:9092"
topics => ["logs"]
codec => "json"
# 컨슈머 그룹 ID 설정
group_id => "logstash_logs"
}
}
filter {
# 타임스탬프 파싱 - 로그의 타임스탬프 필드를 Logstash 이벤트 @timestamp로 변환
date {
match => [ "timestamp", "ISO8601", "yyyy-MM-dd HH:mm:ss,SSS" ]
target => "@timestamp" # 파싱된 날짜를 저장할 필드
remove_field => [ "timestamp" ] # 원본 타임스탬프 필드 제거
}
# JSON 형식 로그 파싱 - 구조화된 JSON 로그를 객체로 변환
if [message] =~ /^{.*}$/ {
json {
source => "message" # JSON 구문 분석할 필드
target => "parsed_json" # 파싱된 JSON을 저장할 필드 (선택 사항)
}
}
# 정규식 패턴 매칭 - 비구조화된 로그를 구조화된 형식으로 변환
grok {
# 일반적인 로그 패턴 매칭
match => {
"message" => "%{TIMESTAMP_ISO8601:timestamp} %{LOGLEVEL:level} %{NOTSPACE:service} - %{GREEDYDATA:msg}"
}
# 패턴이 매칭되지 않는 경우 태그 추가
tag_on_failure => ["_grokparsefailure"]
}
# 로그 레벨에 따른 태그 추가 - 심각도에 따른 필터링 및 알림 설정 용이
if [level] == "ERROR" or [level] == "FATAL" {
mutate {
add_tag => [ "error" ] # 에러 태그 추가
}
} else if [level] == "WARN" {
mutate {
add_tag => [ "warning" ] # 경고 태그 추가
}
}
# 상관관계 ID 추출 (로그 내에 포함된 경우)
if [msg] =~ /correlation_id=([a-zA-Z0-9-]+)/ {
grok {
match => { "msg" => "correlation_id=(?<correlation_id>[a-zA-Z0-9-]+)" }
}
}
# 필드 추가 및 수정
mutate {
# 표준 필드 추가 - 모든 로그에 공통 메타데이터 포함
add_field => {
"environment" => "${ENV:production}" # 환경 변수에서 환경 정보 가져오기
"version" => "${APP_VERSION}" # 애플리케이션 버전
"hostname" => "${HOSTNAME}" # 호스트 이름
"platform" => "kubernetes" # 플랫폼 정보
}
# 필드 변환 및 형식 조정
convert => {
"response_time" => "float" # 응답 시간을 숫자로 변환
}
# 민감 정보 제거 또는 마스킹
gsub => [
"message", "(password=)([^\\s]+)", "\\1[REDACTED]", # 비밀번호 마스킹
"message", "(token=)([^\\s]+)", "\\1[REDACTED]" # 토큰 마스킹
]
}
}
output {
# 에러 로그와 일반 로그 분리 - 에러는 별도 인덱스에 저장
if "error" in [tags] {
elasticsearch {
hosts => ["elasticsearch:9200"] # Elasticsearch 호스트
index => "logs-error-%{+YYYY.MM.dd}" # 날짜별 인덱스 (에러)
# 인덱스 템플릿 설정
template_name => "error-logs"
# 인증 정보 (필요시)
# user => "elastic"
# password => "${ES_PASSWORD}"
}
# 중요 에러는 알림 시스템으로 전송 (선택 사항)
if [level] == "FATAL" {
http {
url => "http://alert-service:8080/api/alerts"
http_method => "post"
content_type => "application/json"
format => "json"
body => '{"level":"%{level}","service":"%{service}","message":"%{msg}"}'
}
}
} else {
# 일반 로그는 표준 인덱스에 저장
elasticsearch {
hosts => ["elasticsearch:9200"]
index => "logs-%{+YYYY.MM.dd}" # 날짜별 인덱스 (일반)
# 필드 지정 (선택 사항)
document_id => "%{[@metadata][fingerprint]}" # 중복 방지를 위한 문서 ID
}
}
# 모든 로그의 복사본을 장기 보관용 S3에 저장 (선택 사항)
s3 {
bucket => "logs-archive"
region => "us-east-1"
prefix => "logs/%{+YYYY/MM/dd}"
time_file => 15 # 15분마다 파일 생성
codec => "json_lines"
# AWS 인증 정보
access_key_id => "${AWS_ACCESS_KEY}"
secret_access_key => "${AWS_SECRET_KEY}"
}
}
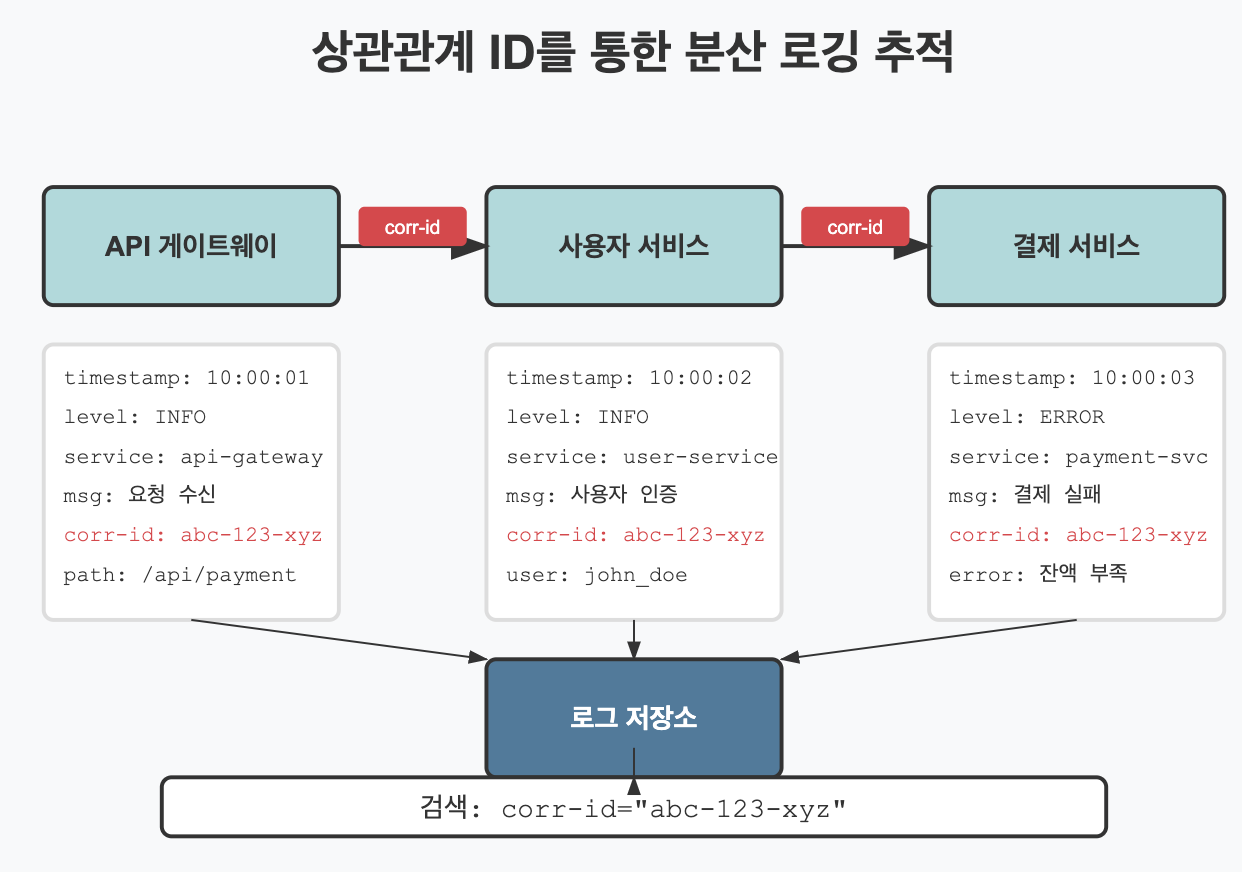
✅ 상관관계 ID와 컨텍스트 추적
복잡한 분산 시스템에서는 여러 서비스를 거치는 요청의 흐름을 추적하는 것이 중요합니다. 상관관계 ID(Correlation ID)는 여러 서비스와 구성 요소 간에 요청을 추적하는 데 사용되는 고유 식별자입니다.
▶️ 상관관계 ID의 역할:
- 단일 사용자 요청과 관련된 모든 로그 메시지를 연결
- 마이크로서비스 환경에서 요청 흐름 추적
- 요청-응답 사이클의 전체 컨텍스트 유지
# Python FastAPI에서 상관관계 ID 사용 예시
import uuid
from fastapi import FastAPI, Request, Depends
from fastapi.middleware.base import BaseHTTPMiddleware
import logging
app = FastAPI()
logger = logging.getLogger("app")
class CorrelationIdMiddleware(BaseHTTPMiddleware):
async def dispatch(self, request, call_next):
# 요청 헤더에서 상관관계 ID 추출 (없으면 새로 생성)
correlation_id = request.headers.get("X-Correlation-ID")
if not correlation_id:
# UUID를 사용하여 고유한 상관관계 ID 생성
correlation_id = str(uuid.uuid4())
# 요청 객체의 상태에 상관관계 ID 저장 (라우트 핸들러에서 접근 가능)
request.state.correlation_id = correlation_id
# MDC(Mapped Diagnostic Context)에 상관관계 ID 설정
# 이것은 로그 포맷터에서 자동으로 로그에 포함됨
# LoggerAdapter를 사용하여 모든 로그에 상관관계 ID 추가
adapter = logging.LoggerAdapter(
logger,
{"correlation_id": correlation_id}
)
# 요청 시작 로그 기록
adapter.info(f"Received request: {request.method} {request.url.path}")
# 다음 미들웨어 또는 엔드포인트 핸들러로 요청 전달
response = await call_next(request)
# 응답 헤더에 상관관계 ID 추가 (클라이언트에게 반환)
# 이를 통해 클라이언트는 후속 요청에 같은 ID를 사용할 수 있음
response.headers["X-Correlation-ID"] = correlation_id
# 응답 완료 로그 기록 (여기에 추가 가능)
adapter.info(f"Request completed: {request.method} {request.url.path} - Status: {response.status_code}")
return response
# 미들웨어 등록
app.add_middleware(CorrelationIdMiddleware)
# 엔드포인트 예시
@app.get("/api/users/{user_id}")
async def get_user(user_id: str, request: Request):
# 요청 객체에서 상관관계 ID 접근
correlation_id = request.state.correlation_id
# 상관관계 ID를 사용한 로그 기록
logger.info(f"Processing user request for user_id={user_id}", extra={"correlation_id": correlation_id})
# ... 비즈니스 로직 ...
return {"user_id": user_id, "correlation_id": correlation_id}▶️ 트레이스 컨텍스트와 통합:
상관관계 ID는 분산 추적 시스템의 트레이스 ID와 통합하여 로그, 메트릭, 트레이스 간의 상관관계를 형성할 수 있습니다.
# OpenTelemetry 상관관계 구성 예시
processors:
batch:
timeout: 1s
send_batch_size: 1024
# 로그에 트레이스 컨텍스트 추가
resource:
attributes:
- key: service.name
value: payment-service
# 트레이스, 로그 상관관계 설정
transform:
logs:
include:
match_type: strict
resource_attributes:
- key: service.name
output_attributes:
trace_id: >
OpenTelemetry.getContextTraceId()
span_id: >
OpenTelemetry.getContextSpanId()
📌 로그 수집과 중앙화
대규모 시스템에서는 로그를 효과적으로 수집하고 중앙화하는 것이 중요합니다. 로그 수집 아키텍처는 로그 데이터의 안정적인 수집, 처리, 저장을 담당합니다.
✅ 로그 수집 아키텍처
효과적인 로그 수집 아키텍처는 다음과 같은 구성 요소로 이루어집니다.
▶️ 로그 발생 계층:
- 애플리케이션: 비즈니스 이벤트, 오류, 경고 등을 기록
- 컨테이너: 컨테이너 stdout/stderr 로그
- 호스트: 시스템 및 운영체제 로그
▶️ 로그 수집 계층:
- 로그 에이전트: 로그 파일을 모니터링하고 수집 (Filebeat, Fluent Bit, Vector 등)
- 로그 파이프라인: 로그 데이터를 처리, 변환, 필터링 (Logstash, Fluentd 등)
- 로그 버퍼: 일시적인 로그 스토리지와 전송 실패 시 보호 (Kafka, Redis 등)
▶️ 로그 저장 계층:
- 로그 저장소: 로그를 인덱싱하고 저장 (Elasticsearch, Loki, CloudWatch Logs 등)
- 장기 보관: 오래된 로그의 저비용 보관 (S3, GCS, Azure Blob Storage 등)
# 로그 수집 아키텍처 예시 (Docker Compose)
version: '3'
services:
# 로그 수집기 - 파일 시스템에서 로그를 수집하여 Kafka로 전송
filebeat:
image: docker.elastic.co/beats/filebeat:7.17.0
volumes:
# Filebeat 설정 파일을 컨테이너에 마운트
- ./filebeat.yml:/usr/share/filebeat/filebeat.yml:ro
# Docker 컨테이너 로그 접근을 위한 볼륨 마운트
- /var/lib/docker/containers:/var/lib/docker/containers:ro
# 호스트 로그 파일 접근을 위한 볼륨 마운트
- /var/log:/var/log:ro
environment:
# Kafka 브로커 주소 환경 변수 설정
- KAFKA_HOSTS=kafka:9092
# 로그 수집 전 Kafka가 먼저 실행되어야 함
depends_on:
- kafka
# 컨테이너 재시작 정책 설정
restart: unless-stopped
# 메시지 버퍼 - 로그 메시지 임시 저장 및 안정적인 전달 보장
kafka:
image: confluentinc/cp-kafka:7.0.0
environment:
# Kafka 브로커 리스너 설정
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092
# 복제 인자 설정 (1: 단일 노드 환경용)
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
# Zookeeper 연결 설정
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
volumes:
# Kafka 데이터를 영구 볼륨에 저장
- kafka_data:/var/lib/kafka/data
# Zookeeper에 의존성 설정
depends_on:
- zookeeper
restart: unless-stopped
# Kafka 클러스터 관리를 위한 Zookeeper
zookeeper:
image: confluentinc/cp-zookeeper:7.0.0
environment:
ZOOKEEPER_CLIENT_PORT: 2181
volumes:
- zookeeper_data:/var/lib/zookeeper/data
restart: unless-stopped
# 로그 처리 및 변환 - 로그를 파싱, 변환, 강화하여 Elasticsearch로 전송
logstash:
image: docker.elastic.co/logstash/logstash:7.17.0
volumes:
# Logstash 파이프라인 설정 파일 마운트
- ./logstash.conf:/usr/share/logstash/pipeline/logstash.conf:ro
environment:
# Elasticsearch 호스트 설정
- ELASTICSEARCH_HOSTS=http://elasticsearch:9200
# JVM 힙 크기 설정
- LS_JAVA_OPTS="-Xms512m -Xmx512m"
# Kafka와 Elasticsearch 의존성 설정
depends_on:
- kafka
- elasticsearch
restart: unless-stopped
# 로그 저장 및 검색 - 로그를 인덱싱하고 검색 가능하게 저장
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.17.0
environment:
# 단일 노드 설정 (개발/테스트 환경용)
- discovery.type=single-node
# JVM 힙 사이즈 설정 (메모리 관리)
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
# 클러스터 이름 설정
- cluster.name=docker-logs-cluster
volumes:
# 로그 데이터 영구 저장을 위한 볼륨
- elasticsearch_data:/usr/share/elasticsearch/data
# 메모리 제한 설정
deploy:
resources:
limits:
memory: 1G
restart: unless-stopped
# 시각화 대시보드 - 로그 데이터 탐색 및 시각화 인터페이스
kibana:
image: docker.elastic.co/kibana/kibana:7.17.0
ports:
# Kibana 웹 인터페이스 포트 노출
- "5601:5601"
environment:
# Elasticsearch 연결 설정
- ELASTICSEARCH_HOSTS=http://elasticsearch:9200
# Kibana 서버 이름 설정
- SERVER_NAME=kibana-logs
# Elasticsearch 의존성 설정
depends_on:
- elasticsearch
restart: unless-stopped
# 영구 볼륨 정의 - 컨테이너 재시작/삭제 후에도 데이터 유지
volumes:
kafka_data:
elasticsearch_data:
zookeeper_data:

✅ ELK와 그라파나 로키
로그 수집 및 분석을 위한 가장 널리 사용되는 스택으로는 ELK 스택(Elasticsearch, Logstash, Kibana)과 그라파나 로키가 있습니다.
▶️ ELK 스택:
- Elasticsearch: 로그 데이터를 저장하고 인덱싱하는 검색 엔진
- Logstash: 로그 데이터를 수집, 처리, 변환하는 데이터 파이프라인
- Kibana: 로그 데이터를 시각화하고 탐색하는 대시보드
- Filebeat/Beats: 로그 데이터를 수집하여 Logstash나 Elasticsearch로 전송하는 경량 에이전트
# Logstash 구성 예시
input {
beats {
port => 5044
}
}
filter {
# JSON 형식 로그 파싱
if [message] =~ /^{.*}$/ {
json {
source => "message"
}
}
# 타임스탬프 파싱
date {
match => [ "timestamp", "ISO8601" ]
target => "@timestamp"
}
# 로그 레벨에 따른 태그 추가
if [level] == "ERROR" or [level] == "FATAL" {
mutate {
add_tag => [ "error" ]
}
}
}
output {
# 오류 로그는 별도 인덱스로 저장
if "error" in [tags] {
elasticsearch {
hosts => ["elasticsearch:9200"]
index => "logs-error-%{+YYYY.MM.dd}"
}
} else {
elasticsearch {
hosts => ["elasticsearch:9200"]
index => "logs-%{+YYYY.MM.dd}"
}
}
}
▶️ 그라파나 로키:
- 로키(Loki): 로그 집계 시스템으로, Prometheus와 유사한 레이블 기반 접근 방식 사용
- 프롬테일(Promtail): 로그를 수집하여 로키로 전송하는 에이전트
- 그라파나(Grafana): 로그 데이터를 시각화하고 쿼리하는 인터페이스
# Loki 구성 예시 (loki-config.yaml)
# 인증 설정 - 프로덕션 환경에서는 true로 설정하는 것을 권장
auth_enabled: false
# 서버 설정
server:
http_listen_port: 3100 # API 엔드포인트 리스닝 포트
grpc_listen_port: 9096 # gRPC 리스닝 포트 (내부 통신용)
http_server_read_timeout: 30s # HTTP 요청 읽기 타임아웃
http_server_write_timeout: 30s # HTTP 응답 쓰기 타임아웃
# 인제스터 설정 - 로그 데이터를 수신하고 청크로 변환하는 컴포넌트
ingester:
lifecycler:
address: 127.0.0.1 # 인제스터 서비스 주소
ring:
kvstore:
store: inmemory # 링 상태 저장 방식 (메모리 내, 소규모 배포용)
# 대규모 배포에서는 'consul', 'etcd', 'memberlist' 권장
replication_factor: 1 # 복제본 수 (고가용성을 위해 운영 환경에서는 3 이상 권장)
final_sleep: 0s # 셧다운 전 대기 시간
chunk_idle_period: 5m # 청크가 비활성 상태로 유지되는 기간
chunk_retain_period: 30s # 인제스터에서 청크 유지 기간
max_transfer_retries: 0 # 전송 재시도 최대 횟수
# 스키마 구성 - 로키가 로그 데이터를 저장하는 방식 정의
schema_config:
configs:
- from: 2020-10-24 # 이 구성이 적용되는 시작 날짜
store: boltdb-shipper # 인덱스 저장소 유형
object_store: filesystem # 청크 저장소 유형 (파일 시스템)
schema: v11 # 스키마 버전
index:
prefix: index_ # 인덱스 파일 접두사
period: 24h # 인덱스 회전 주기 (24시간마다 새 인덱스)
# 스토리지 구성 - 실제 로그 데이터와 인덱스 저장 설정
storage_config:
boltdb_shipper:
active_index_directory: /tmp/loki/boltdb-shipper-active # 활성 인덱스 디렉토리
cache_location: /tmp/loki/boltdb-shipper-cache # 캐시 위치
cache_ttl: 24h # 캐시 만료 시간
shared_store: filesystem # 공유 저장소 유형
filesystem: # 파일시스템 저장소 설정
directory: /tmp/loki/chunks # 청크 저장 디렉토리
# S3/GCS와 같은 객체 스토리지 사용 예시
# aws:
# bucketnames: loki-chunks
# region: us-east-1
# access_key_id: ${AWS_ACCESS_KEY}
# secret_access_key: ${AWS_SECRET_KEY}
# 한계 설정 - 리소스 사용량 및 쿼리 제한
limits_config:
enforce_metric_name: false # 메트릭 이름 강제 여부
reject_old_samples: true # 오래된 샘플 거부 여부
reject_old_samples_max_age: 168h # 거부할 샘플의 최대 나이 (7일)
max_query_length: 721h # 최대 쿼리 기간 (30일)
max_query_parallelism: 32 # 쿼리 병렬 처리 최대 개수
ingestion_rate_mb: 10 # 초당 수집 비율 제한 (MB)
ingestion_burst_size_mb: 20 # 수집 버스트 크기 제한 (MB)
# 청크 저장소 구성
chunk_store_config:
max_look_back_period: 0s # 청크 조회 최대 기간
# 테이블 관리자 구성 - 로그 보존 및 제거 설정
table_manager:
retention_deletes_enabled: false # 보존 정책 기반 삭제 활성화
retention_period: 0s # 보존 기간 (0s는 무제한)
# 운영 환경에서는 적절한 보존 기간 설정 권장, 예: 90d (90일)
# 압축 설정 - 로그 데이터 네트워크 전송 및 저장 시 압축
compactor:
working_directory: /tmp/loki/compactor # 컴팩터 작업 디렉토리
shared_store: filesystem # 공유 저장소 유형
compaction_interval: 10m # 압축 간격
retention_enabled: false # 보존 정책 활성화 여부
# retention_delete_delay: 2h # 삭제 지연
# retention_delete_worker_count: 150 # 삭제 작업자 수
# 쿼리 프론트엔드 설정 - 대규모 쿼리 처리 및 캐싱
frontend:
compress_responses: true # 응답 압축 활성화
log_queries_longer_than: 10s # 긴 쿼리 로깅 기준 시간
max_outstanding_per_tenant: 2048 # 테넌트당 최대 대기 쿼리 수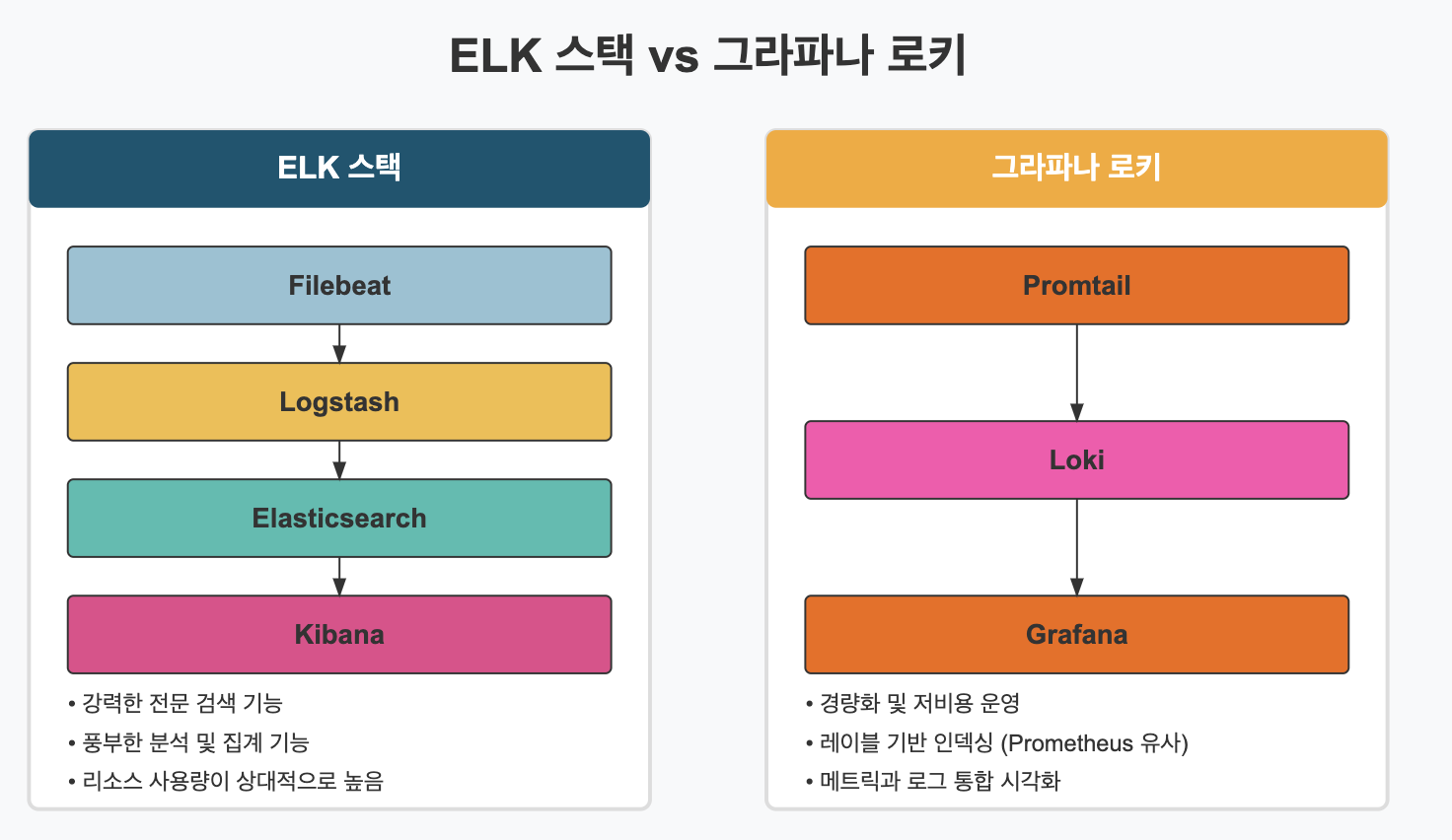
📌 로깅 시스템 최적화와 모범 사례
효과적인 로깅 시스템을 구축하고 유지하기 위한 모범 사례를 살펴보겠습니다.
✅ 로그 생성 최적화
로그 생성 단계에서부터 효율적으로 설계하면 전체 로깅 시스템의 성능과 유용성을 크게 향상시킬 수 있습니다.
▶️ 로그 볼륨 관리:
- 적절한 로그 레벨 설정: 각 환경(개발, 테스트, 프로덕션)에 적합한 로그 레벨 사용
- 샘플링 적용: 고빈도 이벤트는 일부만 샘플링하여 로깅
- 중복 로그 제거: 동일한 메시지의 반복 로깅 방지
// Java에서 로그 반복 제거를 위한 필터 구현 예시
import ch.qos.logback.classic.spi.ILoggingEvent;
import ch.qos.logback.core.filter.Filter;
import ch.qos.logback.core.spi.FilterReply;
/**
* 로그 중복 제거 필터
* 단시간에 동일한 로그 메시지가 반복해서 발생할 경우 중복 메시지를 필터링하여
* 로그 볼륨을 줄이고 가독성을 높이는 필터
*/
public class DuplicateLogFilter extends Filter<ILoggingEvent> {
// 마지막 로그 메시지를 저장
private String lastMessage = "";
// 마지막 로그 메시지 발생 시간
private long lastTimestamp = 0;
// 중복 메시지 카운터
private int duplicateCount = 0;
// 중복 판단 기준 시간 (밀리초) - 이 시간 내에 같은 메시지는 중복으로 판단
private final long thresholdTime = 5000; // 5초
@Override
public FilterReply decide(ILoggingEvent event) {
String message = event.getMessage();
long currentTimestamp = event.getTimeStamp();
// 동일한 메시지이고 임계값 시간(5초) 내의 중복이면
if (message.equals(lastMessage) && (currentTimestamp - lastTimestamp) < thresholdTime) {
duplicateCount++;
// 10개마다 한 번만 로깅 (중복 횟수 표시)
// 이렇게 하면 로그 패턴은 유지하면서 중복 발생을 알릴 수 있음
if (duplicateCount % 10 == 0) {
event.getLoggerContextVO().getLogger(event.getLoggerName())
.info("Last message repeated {} times", duplicateCount);
return FilterReply.ACCEPT;
}
return FilterReply.DENY; // 중복 메시지 로깅 거부
} else {
// 새로운 메시지이거나 중복 임계값 시간을 초과한 경우
if (duplicateCount > 0) {
// 이전에 중복 메시지가 있었다면 최종 중복 횟수 로깅
event.getLoggerContextVO().getLogger(event.getLoggerName())
.info("Previous message repeated {} times", duplicateCount);
duplicateCount = 0;
}
// 현재 메시지와 타임스탬프 업데이트
lastMessage = message;
lastTimestamp = currentTimestamp;
return FilterReply.ACCEPT; // 새 메시지 허용
}
}
}▶️ 로그 내용 최적화:
- 필요한 정보만 포함: 불필요한 정보 제외하여 로그 크기 감소
- 민감 정보 제외: 개인정보, 비밀번호, 토큰 등은 로깅 제외 또는 마스킹
- 적절한 문맥 포함: 문제 해결에 필요한 충분한 컨텍스트 제공
✅ 로그 보관 및 보존 전략
로그 데이터는 시간이 지남에 따라 크게 늘어날 수 있으므로, 효과적인 보존 전략이 필요합니다.
▶️ 로그 보존 정책:
- 계층형 보존 정책: 시간에 따라 다른 보존 기간 적용
- 최근 로그 (0-30일): 고성능 스토리지에 전체 로그 보관
- 중기 로그 (1-3개월): 압축 및 일부 필터링하여 보관
- 장기 로그 (3개월 이상): 추가 압축 및 중요 로그만 선별 보관
# Elasticsearch ILM(Index Lifecycle Management) 정책 예시
PUT _ilm/policy/logs_lifecycle_policy
{
"policy": {
"phases": {
// 핫 페이즈 - 적극적인 쓰기 및 쿼리를 처리하는 최신 데이터
"hot": {
"min_age": "0ms", // 인덱스 생성 즉시 시작
"actions": {
// 롤오버 조건 - 지정된 크기 또는 기간에 도달하면 새 인덱스로 전환
"rollover": {
"max_size": "50GB", // 인덱스 크기가 50GB에 도달하면 롤오버
"max_age": "1d", // 또는 1일이 지나면 롤오버
"max_docs": 100000000 // 또는 1억 문서에 도달하면 롤오버
},
// 인덱스 우선순위 설정 - 높은 값이 더 중요
"set_priority": {
"priority": 100 // 핫 인덱스에 높은 우선순위 부여
}
}
},
// 웜 페이즈 - 더 이상 업데이트되지 않지만 가끔 쿼리되는 데이터
"warm": {
"min_age": "7d", // 핫 페이즈 후 7일 후 시작
"actions": {
// 샤드 수 줄이기 - 스토리지 효율성 향상
"shrink": {
"number_of_shards": 1 // 단일 샤드로 축소
},
// 세그먼트 강제 병합 - 스토리지 효율성 및 쿼리 성능 향상
"forcemerge": {
"max_num_segments": 1 // 하나의 세그먼트로 병합
},
// 인덱스 우선순위 변경
"set_priority": {
"priority": 50 // 웜 인덱스는 중간 우선순위
},
// 읽기 전용으로 설정 (선택 사항)
"readonly": {}
}
},
// 콜드 페이즈 - 거의 쿼리되지 않지만 여전히 검색 가능한 데이터
"cold": {
"min_age": "30d", // 웜 페이즈 후 30일 후 시작
"actions": {
// 저비용 스토리지로 이동
"allocate": {
"require": {
"data": "cold" // cold 속성을 가진 노드로 할당
}
},
// 인덱스 우선순위 변경
"set_priority": {
"priority": 0 // 콜드 인덱스는 낮은 우선순위
},
// 비동기 검색만 허용 (선택 사항)
"freeze": {} // 메모리 사용량을 줄이기 위해 인덱스 동결
}
},
// 삭제 페이즈 - 더 이상 필요하지 않은 오래된 데이터
"delete": {
"min_age": "90d", // 콜드 페이즈 후 90일 후 시작
"actions": {
// 인덱스 삭제
"delete": {
// 삭제 전 스냅샷 생성 (선택 사항)
"delete_searchable_snapshot": true
}
}
}
}
}
}▶️ 데이터 압축과 저비용 스토리지:
- 압축 알고리즘 활용: 로그 데이터는 압축률이 높은 경우가 많음
- 객체 스토리지 활용: S3, GCS 등의 저비용 스토리지로 오래된 로그 이전
- 콜드 스토리지 계층: 거의 접근하지 않는 로그는 콜드 스토리지로 이동

✅ 로그 검색 및 분석 최적화
로그가 생성되고 저장된 후에는 효과적으로 검색하고 분석하는 기능이 중요합니다.
▶️ 검색 최적화:
- 효과적인 인덱싱: 자주 검색하는 필드에 대한 인덱스 생성
- 쿼리 최적화: 복잡한 쿼리보다 간단하고 효율적인 쿼리 사용
- 검색 필터 활용: 시간 범위, 로그 레벨 등으로 검색 범위 축소
# Elasticsearch 인덱스 템플릿 예시 - 로그 데이터 최적화
PUT _index_template/logs_template
{
// 이 템플릿을 적용할 인덱스 패턴 설정
"index_patterns": ["logs-*"], // "logs-"로 시작하는 모든 인덱스에 적용
"template": {
// 인덱스 설정
"settings": {
"number_of_shards": 3, // 각 인덱스의 샤드 수 (클러스터 크기에 맞게 조정)
"number_of_replicas": 1, // 각 샤드의 복제본 수 (고가용성을 위해)
"index.refresh_interval": "5s", // 인덱스 갱신 주기 (쿼리 가시성 vs 성능)
// 분석기 설정 - 텍스트 필드 검색 최적화
"analysis": {
"analyzer": {
"log_analyzer": { // 로그 메시지 분석기 정의
"type": "custom",
"tokenizer": "standard",
"filter": ["lowercase", "stop", "snowball"] // 토큰화, 소문자 변환, 불용어 제거
}
}
},
// 인덱스 라이프사이클 관리 연결
"index.lifecycle.name": "logs_policy", // ILM 정책 이름
"index.lifecycle.rollover_alias": "logs" // 롤오버 별칭
},
// 필드 매핑 정의
"mappings": {
// 공통 메타데이터 설정
"_meta": {
"description": "로그 데이터를 위한 템플릿",
"version": "1.0"
},
// 동적 매핑 설정
"dynamic_templates": [
{
// 문자열 필드는 기본적으로 keyword 타입으로 설정 (쿼리 성능 최적화)
"strings_as_keywords": {
"match_mapping_type": "string",
"mapping": {
"type": "keyword",
"ignore_above": 256 // 너무 긴 문자열은 인덱싱하지 않음
}
}
}
],
// 특정 필드 명시적 매핑
"properties": {
// 타임스탬프 - 날짜 타입으로 명시적 매핑
"@timestamp": {
"type": "date" // 날짜/시간 정보 인덱싱
},
// 로그 레벨 - 키워드 타입으로 매핑 (필터링 및 집계 용이)
"level": {
"type": "keyword" // 로그 레벨은 정확히 일치하는 검색을 위해 keyword 타입
},
// 서비스 이름 - 키워드 타입
"service": {
"type": "keyword" // 서비스 이름은 필터링을 위해 keyword 타입
},
// 추적 ID - 키워드 타입 (정확히 일치하는 검색)
"trace_id": {
"type": "keyword" // 분산 추적 ID는 정확히 일치하는 검색을 위해 keyword 타입
},
// 상관관계 ID - 키워드 타입
"correlation_id": {
"type": "keyword" // 관련 로그를 함께 검색하기 위한 키워드 타입
},
// 로그 메시지 - 텍스트 타입 (전문 검색)
"message": {
"type": "text", // 전문 검색을 위한 text 타입
"analyzer": "log_analyzer", // 위에서 정의한 분석기 적용
"fields": {
"keyword": { // message.keyword 필드 추가
"type": "keyword",
"ignore_above": 256 // 집계, 정렬 용도
}
}
},
// 사용자 ID - 키워드 타입
"user_id": {
"type": "keyword" // 사용자별 로그 필터링을 위한 키워드 타입
},
// 요청 처리 시간 - 숫자 타입
"duration_ms": {
"type": "long" // 성능 측정을 위한 숫자 필드
},
// HTTP 상태 코드 - 정수 타입
"status_code": {
"type": "integer" // HTTP 상태 코드 저장
},
// 태그 배열 - 키워드 타입
"tags": {
"type": "keyword" // 태그 기반 필터링 및 집계
},
// 지리적 위치 정보 (선택 사항)
"geo": {
"properties": {
"coordinates": {
"type": "geo_point" // 지도 시각화 및 지리적 검색 지원
}
}
}
}
}
}
}▶️ 로그 집계 및 시각화:
- 대시보드 구성: 중요 지표에 대한 대시보드 구성
- 알림 설정: 오류 패턴 감지 시 알림 구성
- 이상 감지: 비정상적인 로그 패턴 자동 감지
📌 로깅 체크리스트와 도전 과제
효과적인 로깅 시스템을 구축하고 유지하기 위한 체크리스트와 일반적인 도전 과제를 살펴보겠습니다.
✅ 로깅 시스템 체크리스트
▶️ 설계 단계:
- [ ] 일관된 로그 형식과 구조 정의
- [ ] 명확한 로그 레벨 정책 수립
- [ ] 필요한 컨텍스트 정보 식별
- [ ] 민감 정보 처리 정책 수립
- [ ] 로그 보존 기간 및 정책 결정
▶️ 구현 단계:
- [ ] 구조화된 로깅 라이브러리 선택
- [ ] 상관관계 ID 구현
- [ ] 로그 수집 파이프라인 구성
- [ ] 로그 저장소 설정
- [ ] 로그 보안 및 접근 제어 구현
▶️ 운영 단계:
- [ ] 로그 모니터링 대시보드 구성
- [ ] 로그 기반 알림 설정
- [ ] 로그 볼륨 및 성능 모니터링
- [ ] 정기적인 로그 검토 및 개선
- [ ] 장애 발생 시 로그 분석 훈련
✅ 일반적인 도전 과제와 해결책
▶️ 로그 볼륨 관리:
- 도전 과제: 대규모 시스템에서 생성되는 방대한 로그 양
- 해결책:
- 샘플링 및 필터링 적용
- 적절한 로그 레벨 사용
- 계층형 스토리지 전략 구현
▶️ 성능 영향:
- 도전 과제: 과도한 로깅으로 인한 애플리케이션 성능 저하
- 해결책:
- 비동기 로깅 구현
- 로깅 버퍼 사용
- 배치 처리 적용
▶️ 의미 있는 로그:
- 도전 과제: 너무 많거나 불충분한 정보로 인한 분석 어려움
- 해결책:
- 명확한 로깅 가이드라인 수립
- 구조화된 형식 사용
- 컨텍스트 정보 포함

📌 결론
이번 글에서 다룬 핵심 내용을 요약하면 다음과 같습니다:
- 로그의 중요성과 역할
- 시스템 이벤트를 기록하는 시간 순서 기반 데이터
- 문제 해결, 행동 분석, 보안 모니터링, 규제 준수에 필수
- 효과적인 로깅 전략
- 적절한 로그 레벨 활용과 구조화된 로깅 구현
- 상관관계 ID를 통한 분산 시스템 추적
- 민감 정보 보호와 충분한 컨텍스트 제공 균형
- 로그 수집과 중앙화
- 로그 에이전트, 파이프라인, 버퍼, 저장소로 구성된 아키텍처
- ELK 스택과 그라파나 로키와 같은 로그 관리 솔루션
- 효율적인 로그 집계 및 분석
- 최적화와 모범 사례
- 로그 생성, 보관, 검색 단계별 최적화 전략
- 계층형 보존 정책과 효율적인 스토리지 활용
- 일반적인 도전 과제와 해결책
효과적인 로그 관리는 시스템 운영에 필수적인 가시성을 제공하며, 메트릭, 트레이스와 함께 완전한 Observability를 달성하는 핵심 요소입니다. 표준화된 로깅 접근 방식과 최적화된 로깅 아키텍처를 구축함으로써 시스템의 상태와 동작을 더 잘 이해하고 문제를 신속하게 해결할 수 있습니다.