이번 글에서는 프로메테우스와 그라파나를 활용한 Observability 구성 시리즈의 다섯 번째 포스트로, 분산 시스템 추적(Distributed Tracing)의 기본 개념과 핵심 구성 요소에 대해 알아보겠습니다.
📌 분산 추적의 필요성
현대적인 애플리케이션은 대부분 마이크로서비스 아키텍처로 구축되어 있으며, 단일 요청이 여러 서비스와 컴포넌트를 통과하는 경우가 많습니다. 이러한 복잡한 환경에서는 문제가 발생했을 때 어디서 발생했는지, 어떤 서비스가 병목 현상을 일으키는지 파악하기 어렵습니다.
✅ 마이크로서비스 환경의 도전 과제
▶️ 복잡성 증가:
- 단일 애플리케이션이 수십 또는 수백 개의 마이크로서비스로 분할됩니다.
- 각 서비스는 독립적으로 개발, 배포, 확장됩니다.
- 다양한 기술 스택과 언어로 구현되어 있을 수 있습니다.
▶️ 문제 해결의 어려움:
- 단일 요청이 여러 서비스를 거치므로 장애 지점을 파악하기 어렵습니다.
- 개별 서비스 로그만으로는 전체 문맥을 이해하기 어렵습니다.
- 성능 저하의 원인을 식별하기 위해 여러 서비스의 메트릭을 상관관계 분석해야 합니다.
✅ 분산 추적의 역할
분산 추적은 이러한 문제를 해결하기 위한 핵심 도구입니다.
▶️ 분산 추적의 정의:
분산 추적은 여러 서비스와 시스템을 거치는 요청의 전체 경로를 추적하고 시각화하는 기술입니다. 요청이 시스템을 통과하는 과정에서 각 단계별 지연 시간, 오류, 의존성 등을 기록하고 분석합니다.
▶️ 분산 추적의 주요 목적:
- 전체 요청 흐름 파악: 요청이 여러 서비스를 어떻게 통과하는지 시각화합니다.
- 성능 병목 식별: 어떤 서비스나 작업이 지연을 유발하는지 정확히 파악합니다.
- 오류 발생 지점 추적: 오류가 어디서 시작되었는지, 어떻게 전파되었는지 확인합니다.
- 서비스 간 의존성 매핑: 서비스 간의 관계와 상호작용을 이해합니다.
- 리소스 최적화: 불필요하거나 중복된 호출을 식별하여 최적화합니다.
📌 분산 추적의 핵심 개념
분산 추적을 이해하기 위해서는 몇 가지 핵심 개념에 대한 이해가 필요합니다.
✅ 트레이스(Trace)와 스팬(Span)
▶️ 트레이스(Trace):
트레이스는 단일 요청의 전체 여정을 나타냅니다. 브라우저 요청부터 시작하여 모든 서비스를 거쳐 최종 응답이 반환될 때까지의 경로를 포함합니다.
- 트레이스 ID: 각 트레이스는 고유한 ID로 식별됩니다.
- 전체 요청 컨텍스트: 하나의 트레이스는 여러 스팬으로 구성됩니다.
- 근본 원인 분석: 트레이스를 통해 문제의 근본 원인을 파악할 수 있습니다.
▶️ 스팬(Span):
스팬은 트레이스의 기본 구성 요소로, 단일 작업 단위를 나타냅니다. 예를 들어, 데이터베이스 쿼리, API 호출, 함수 실행 등이 스팬이 될 수 있습니다.
- 스팬 ID: 각 스팬은 고유한 ID를 가집니다.
- 시작 시간과 종료 시간: 작업의 지속 시간을 측정합니다.
- 부모-자식 관계: 스팬 간의 계층 구조를 형성합니다.
- 태그와 로그: 스팬에 관련 메타데이터와 이벤트를 기록합니다.
✅ 컨텍스트 전파(Context Propagation)
분산 추적의 핵심 기능 중 하나는 컨텍스트 전파입니다. 이는 트레이스 식별자와 부모 스팬 정보를 서비스 간에 전달하여 요청의 전체 경로를 연결하는 메커니즘입니다.
▶️ 컨텍스트 전파 방식:
- HTTP 헤더: RESTful API 호출에서는 HTTP 헤더를 통해 컨텍스트를 전파합니다.
- 메시지 속성: 메시지 큐를 사용할 때는 메시지 속성에 컨텍스트를 포함합니다.
- gRPC 메타데이터: gRPC 호출에서는 메타데이터를 통해 컨텍스트를 전파합니다.
- 자동 계측: 많은 추적 라이브러리는 자동으로 컨텍스트를 전파하는 기능을 제공합니다.
▶️ 주요 컨텍스트 정보:
- 트레이스 ID(Trace ID): 전체 트레이스를 식별하는 고유 ID
- 스팬 ID(Span ID): 현재 작업을 식별하는 고유 ID
- 부모 스팬 ID(Parent Span ID): 현재 스팬의 부모를 식별하는 ID
- **샘플링 플래그
✅ 컨텍스트 전파(Context Propagation) (계속)
▶️ 주요 컨텍스트 정보 (계속):
- 샘플링 플래그(Sampling Flag): 이 트레이스가 샘플링 대상인지 여부
- 추가 속성(Baggage): 트레이스 전체에 걸쳐 전파되는 추가 정보
# HTTP 헤더를 통한 컨텍스트 전파 예시
GET /api/products/123 HTTP/1.1
Host: example.com
traceparent: 00-4bf92f3577b34da6a3ce929d0e0e4736-00f067aa0ba902b7-01
tracestate: congo=t61rcWkgMzE,rojo=00f067aa0ba902b7
▶️ 컨텍스트 전파 도전 과제:
- 비동기 처리: 비동기 작업에서 컨텍스트 유지
- 다양한 프로토콜: HTTP, gRPC, 메시징 시스템 등 다양한 프로토콜 지원
- 성능 오버헤드: 최소한의 오버헤드로 컨텍스트 전파
- 벤더 호환성: 다양한 추적 시스템 간의 호환성 보장

✅ 샘플링(Sampling)
분산 추적은 데이터 볼륨이 매우 크기 때문에, 모든 요청을 추적하는 것은 실용적이지 않을 수 있습니다. 샘플링은 전체 요청 중 일부만 추적하여 성능 영향과 저장 공간을 줄이는 방법입니다.
▶️ 샘플링 전략:
- 확률적 샘플링(Probabilistic Sampling): 무작위로 일정 비율의 트레이스만 수집합니다.
- 속도 제한 샘플링(Rate-limiting Sampling): 초당 최대 트레이스 수를 제한합니다.
- 우선순위 기반 샘플링(Priority-based Sampling): 중요도나 지연 시간에 따라 샘플링 여부를 결정합니다.
- 동적 샘플링(Dynamic Sampling): 시스템 부하나 오류율에 따라 샘플링 비율을 조정합니다.
- 테일 기반 샘플링(Tail-based Sampling): 요청이 완료된 후 특성(예: 지연 시간, 오류)을 기반으로 샘플링합니다.
# Jaeger 샘플링 구성 예시
sampling:
strategies:
- type: probabilistic
param: 0.1 # 10% 샘플링
- type: ratelimiting
param: 100 # 초당 최대 100개 트레이스
📌 분산 추적 표준과 구현체
분산 추적 분야에는 여러 표준과 구현체가 있습니다. 주요 표준과 도구를 살펴보겠습니다.
✅ 오픈트레이싱(OpenTracing)과 오픈텔레메트리(OpenTelemetry)
▶️ 오픈트레이싱(OpenTracing):
오픈트레이싱은 벤더 중립적인 분산 추적 API를 제공하는 표준입니다. 2019년에 오픈텔레메트리 프로젝트로 통합되었습니다.
- 목적: 다양한 추적 시스템 간의 호환성 보장
- 구성요소: API 명세, 다양한 언어별 구현체
- 장점: 벤더에 종속되지 않는 추적 코드 작성 가능
▶️ 오픈텔레메트리(OpenTelemetry):
오픈텔레메트리는 오픈트레이싱과 오픈센서스(OpenCensus)를 통합한 프로젝트로, 메트릭, 로그, 트레이스를 위한 통합 도구를 제공합니다.
- 목적: 분산 추적, 메트릭, 로그를 위한 통합 표준 제공
- 구성요소: API, SDK, 수집기(Collector), 계측 라이브러리
- 장점: 표준화된 방식으로 모든 관측 가능성 데이터 수집 가능
// OpenTelemetry Java 예시
Tracer tracer = GlobalOpenTelemetry.getTracer("my-service");
Span span = tracer.spanBuilder("processRequest")
.setSpanKind(SpanKind.SERVER)
.setAttribute("http.method", "GET")
.setAttribute("http.url", request.getRequestURL().toString())
.startSpan();
try (Scope scope = span.makeCurrent()) {
// 비즈니스 로직 실행
processRequest(request);
} catch (Exception e) {
span.recordException(e);
span.setStatus(StatusCode.ERROR, e.getMessage());
throw e;
} finally {
span.end();
}
✅ 주요 분산 추적 시스템
분산 추적을 위한 다양한 시스템이 있으며, 각각 고유한 특징과 장점을 가지고 있습니다.
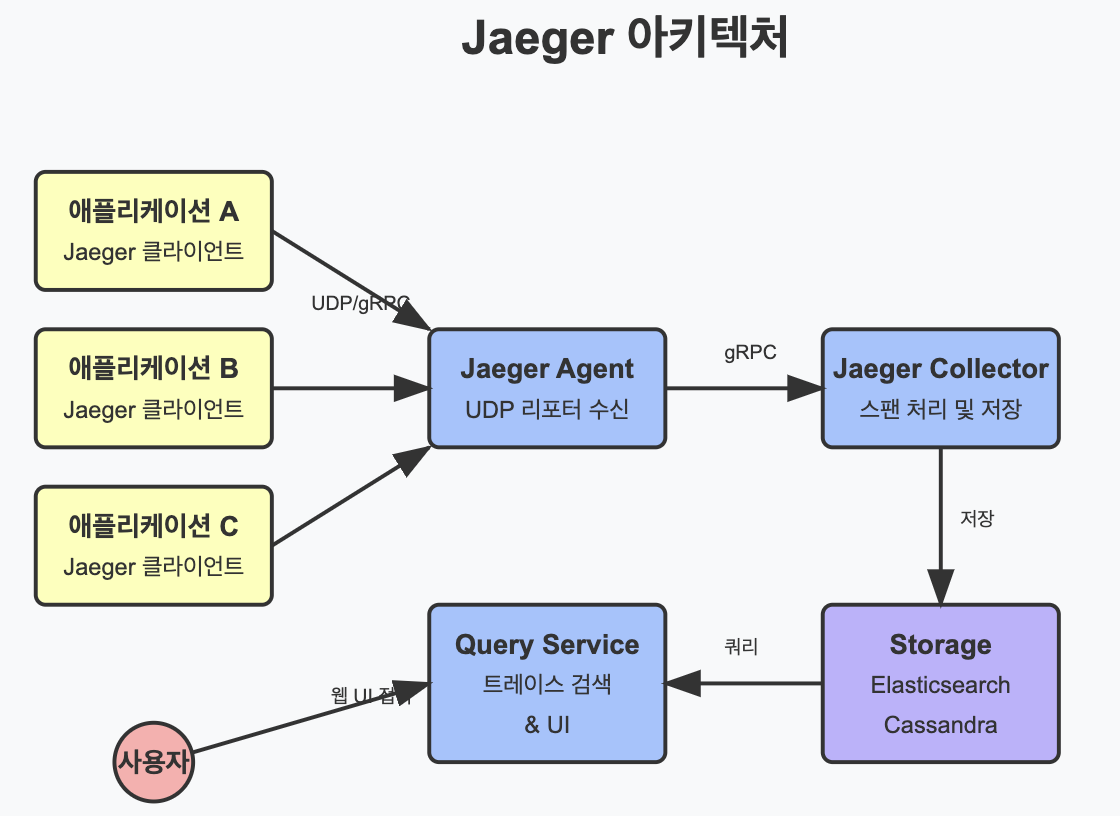
▶️ Jaeger:
Uber에서 개발하고 CNCF에 기부한 오픈소스 분산 추적 시스템입니다.
- 특징: 완전한 오픈소스, 쿠버네티스 친화적, 멀티 스토리지 지원
- 구성요소: 클라이언트 라이브러리, 에이전트, 수집기, 쿼리 서비스, UI
- 저장소: Elasticsearch, Cassandra, 인메모리
▶️ Zipkin:
Twitter에서 개발한 오픈소스 분산 추적 시스템입니다.
- 특징: 간단한 구조, 폭넓은 언어 지원, UI 시각화
- 구성요소: 수집기, 저장소, 쿼리 API, Web UI
- 저장소: MySQL, Cassandra, Elasticsearch
▶️ 그라파나 Tempo:
Grafana Labs에서 개발한 고성능 분산 추적 백엔드입니다.
- 특징: 대규모 분산 추적 저장 및 조회에 최적화, 저비용
- 구성요소: 수집기, 백엔드 저장소, 그라파나 쿼리 인터페이스
- 통합: Grafana 대시보드와 원활한 통합
▶️ AWS X-Ray:
AWS의 관리형 분산 추적 서비스입니다.
- 특징: AWS 서비스와 심층 통합, 서버리스 환경 지원
- 구성요소: X-Ray SDK, X-Ray 대몬, AWS 콘솔
- 장점: AWS 인프라 모니터링에 최적화
📌 분산 추적 구현 방법
분산 추적을 효과적으로 구현하기 위한 방법과 모범 사례를 살펴보겠습니다.
✅ 계측(Instrumentation) 방법
애플리케이션에 분산 추적을 추가하는 방법은 크게 세 가지가 있습니다.
▶️ 자동 계측(Auto-instrumentation):
코드 변경 없이 에이전트나 바이트코드 조작 기술을 사용하여 추적을 적용합니다.
- 장점: 코드 변경 최소화, 빠른 적용
- 단점: 세밀한 제어 어려움, 성능 영향 가능성
- 사용 사례: 기존 애플리케이션, 레거시 시스템
# Java 자동 계측 에이전트 사용 예시
java -javaagent:opentelemetry-javaagent.jar \
-Dotel.service.name=my-service \
-Dotel.exporter.otlp.endpoint=http://collector:4317 \
-jar myapp.jar
▶️ 수동 계측(Manual Instrumentation):
코드에 명시적으로 추적 코드를 추가합니다.
- 장점: 세밀한 제어, 비즈니스 로직 맞춤형 추적
- 단점: 개발 노력 증가, 코드 변경 필요
- 사용 사례: 중요 비즈니스 로직, 성능 중요 코드
// Node.js에서 OpenTelemetry 수동 계측 예시
const tracer = opentelemetry.trace.getTracer('my-service');
// 스팬 생성
const span = tracer.startSpan('processOrder');
span.setAttribute('order.id', orderId);
try {
// 비즈니스 로직 실행
processOrder(orderId);
// 성공 시
span.setStatus({ code: opentelemetry.SpanStatusCode.OK });
} catch (error) {
// 오류 발생 시
span.setStatus({
code: opentelemetry.SpanStatusCode.ERROR,
message: error.message
});
span.recordException(error);
throw error;
} finally {
// 스팬 종료
span.end();
}
▶️ 하이브리드 접근법:
자동 계측과 수동 계측을 함께 사용합니다.
- 장점: 기본 추적은 자동화, 중요 코드는 수동으로 세밀하게 제어
- 단점: 두 방식의 구성 및 관리 필요
- 사용 사례: 대부분의 현대적인 애플리케이션
✅ 모범 사례와 팁
효과적인 분산 추적 구현을 위한 모범 사례입니다.
▶️ 명명 규칙:
- 일관된 스팬 이름 사용 (예: "HTTP GET /users/:id")
- 표준화된 태그 이름 사용 (예: http.method, db.statement)
- 서비스 이름 표준화
▶️ 계측 범위:
- 모든 외부 호출(API, 데이터베이스, 캐시) 계측
- 중요 내부 함수와 비즈니스 로직 계측
- 비동기 작업 추적 확보
▶️ 컨텍스트 전파:
- 표준 전파 형식 사용(W3C Trace Context, B3)
- 비동기 컨텍스트 전파 신중하게 처리
- 모든 통신 채널(HTTP, gRPC, 메시징)에서 컨텍스트 전파 보장
▶️ 오류 처리:
- 예외와 오류를 스팬에 기록
- 오류 유형과 메시지 포함
- 스택 트레이스 기록 (적절한 수준에서)
# Python OpenTelemetry 오류 처리 예시
from opentelemetry import trace
tracer = trace.get_tracer(__name__)
with tracer.start_as_current_span("process_data") as span:
try:
# 비즈니스 로직
result = process_data(data)
# 성공 시 속성 추가
span.set_attribute("data.records", len(result))
span.set_status(trace.StatusCode.OK)
except DatabaseError as e:
# 데이터베이스 오류 처리
span.set_status(trace.StatusCode.ERROR, str(e))
span.record_exception(e)
span.set_attribute("error.type", "database_error")
except Exception as e:
# 일반 오류 처리
span.set_status(trace.StatusCode.ERROR, str(e))
span.record_exception(e)
raise

📌 실제 적용 사례와 도전 과제
분산 추적을 실제 환경에 적용할 때의 사례와 도전 과제에 대해 알아보겠습니다.
✅ 마이크로서비스 환경에서의 적용
마이크로서비스 아키텍처는 분산 추적의 주요 적용 영역입니다.
▶️ 공통 적용 패턴:
- API 게이트웨이 통합: 모든 요청 입구에서 추적 시작
- 서비스 메시 활용: Istio, Linkerd와 같은 서비스 메시를 통한 자동 계측
- 사이드카 프록시: 각 서비스 옆에 추적 에이전트 배포
# 쿠버네티스에서 Jaeger 에이전트 사이드카 배포 예시
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-service
spec:
template:
spec:
containers:
- name: my-service
image: my-service:latest
env:
- name: JAEGER_AGENT_HOST
value: localhost
- name: JAEGER_AGENT_PORT
value: "6831"
- name: jaeger-agent
image: jaegertracing/jaeger-agent:latest
ports:
- containerPort: 6831
protocol: UDP
✅ 현실적인 도전 과제
분산 추적을 구현할 때 직면할 수 있는 도전 과제들입니다.
▶️ 데이터 볼륨:
- 스토리지 요구사항: 대규모 시스템에서 많은 스토리지 필요
- 효과적인 샘플링: 의미 있는 데이터만 선택적으로 저장
- 비용 관리: 스토리지 및 처리 비용 최적화
▶️ 레거시 시스템 통합:
- 비계측 시스템: 추적 계측이 없는 레거시 애플리케이션
- 프로토콜 변환: 다양한 통신 프로토콜 간 컨텍스트 전파
- 확장성: 전체 환경으로 점진적 확장
▶️ 조직적 과제:
- 다양한 팀 협업: 여러 팀이 관리하는 서비스 간 일관된 계측
- 표준화: 명명 규칙, 태그, 컨텍스트 전파 표준화
- 활용 및 교육: 팀이 추적 데이터를 효과적으로 활용하도록 교육
📌 결론
이번 글에서 다룬 핵심 내용을 요약하면 다음과 같습니다:
- 분산 추적의 필요성
- 마이크로서비스 환경에서 요청 경로 추적
- 성능 병목과 오류 발생 지점 식별
- 서비스 간 의존성 이해
- 핵심 개념과 구성 요소
- 트레이스와 스팬의 구조와 관계
- 컨텍스트 전파 메커니즘
- 샘플링 전략과 구현
- 주요 표준과 도구
- OpenTelemetry 통합 표준
- Jaeger, Zipkin, Tempo 등의 구현체
- 자동 및 수동 계측 방법
- 모범 사례와 도전 과제
- 효과적인 계측과 컨텍스트 관리
- 성능 및 리소스 영향 관리
- 대규모 시스템과 레거시 환경 통합
분산 추적은 복잡한 마이크로서비스 환경에서 시스템 동작을 이해하고 문제를 해결하는 데 필수적인 도구입니다. 메트릭과 로그와 함께 사용하면 완전한 Observability를 달성하여 시스템의 상태와 성능에 대한 포괄적인 시각을 제공합니다.