HPC에서 I/O 스케줄러가 중요한 이유
HPC(High Performance Computing) 환경에서는 연산 성능뿐 아니라 스토리지 성능이 전체 작업 속도를 좌우합니다. 특히 AI 학습, CFD(Computational Fluid Dynamics), 분자동역학, 기상 시뮬레이션과 같은 워크로드는 방대한 데이터를 지속적으로 읽고 쓰게 됩니다. 이 과정에서 디스크 I/O 지연이 발생하면 GPU와 CPU가 동시에 대기 상태에 빠지며, 결과적으로 자원 활용률이 떨어집니다.
리눅스 커널은 이러한 디스크 요청을 처리하기 위해 **I/O 스케줄러(I/O Scheduler)**를 사용합니다. 어떤 스케줄러를 선택하느냐에 따라 지연(latency), 처리량(throughput), CPU 오버헤드가 달라지며, 워크로드 특성에 따라 성능 편차가 상당히 크게 나타날 수 있습니다. 따라서 HPC 환경에서는 단순히 기본값을 쓰는 것이 아니라, 스토리지 구조와 애플리케이션 특성에 맞는 스케줄러 튜닝이 필요합니다.
리눅스 I/O 스케줄러의 구조와 종류
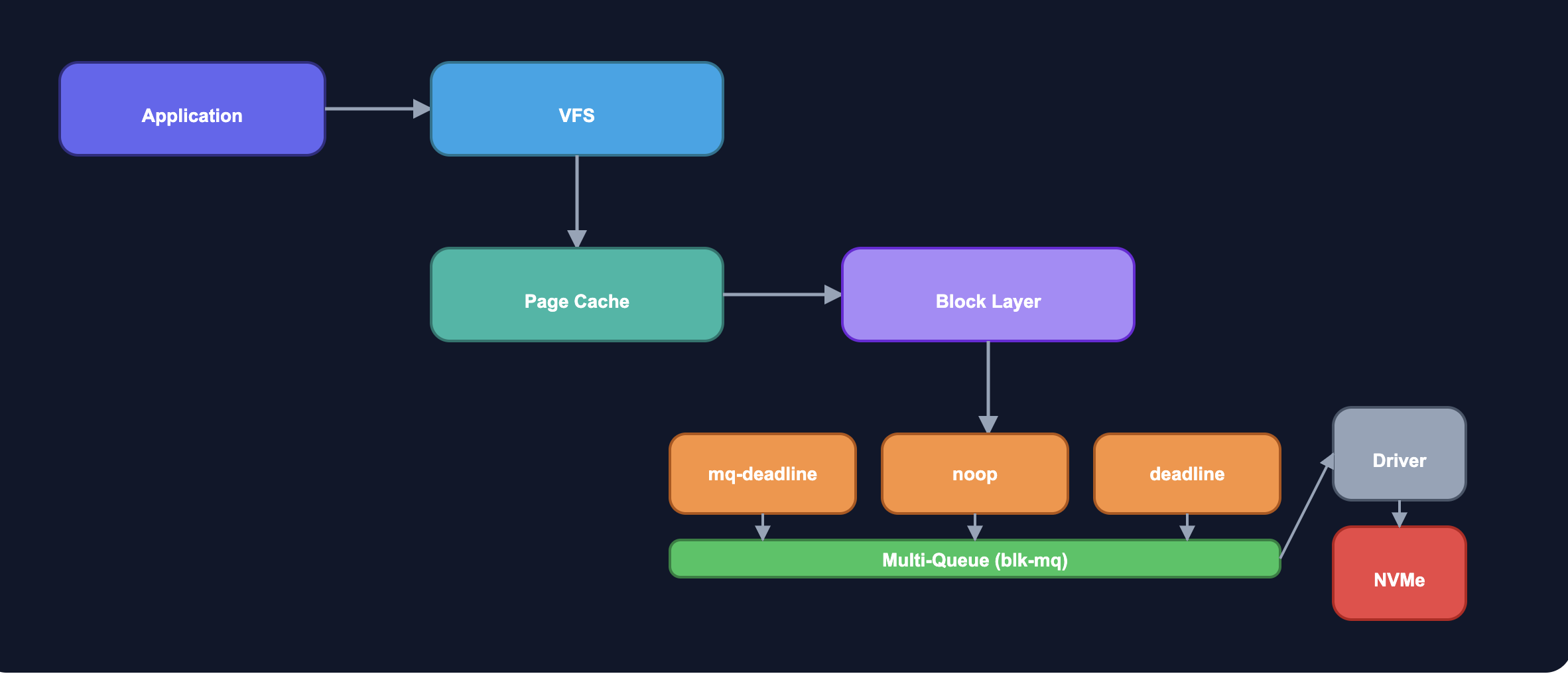
리눅스 커널의 블록 계층(Block Layer)에는 다양한 스케줄러가 존재합니다. 각각의 스케줄러는 요청을 재정렬하거나 병합하여 성능을 최적화하려는 목적을 가지고 있으며, 환경에 따라 적합성과 성능 차이가 크게 발생합니다.
| 스케줄러 | 특징 | 장점 | 단점 | 권장 환경 |
| CFQ (Completely Fair Queuing) | 프로세스별 균등 I/O 분배 | 공정성 확보 | HPC처럼 대량 I/O 환경에서는 오버헤드 | 데스크톱, 범용 서버 |
| Deadline | 요청에 마감 시간 부여 | 지연 최소화, 예측 가능 | 처리량보다는 지연에 집중 | DB, OLTP 워크로드 |
| NOOP | 단순 FIFO 큐 | CPU 부하 최소, SSD 적합 | 순차 I/O 최적화 부족 | SSD, NVMe |
| BFQ (Budget Fair Queuing) | 대역폭 기반 분배 | 대용량 스트리밍에 강점 | 랜덤 I/O에서는 비효율 | 멀티미디어, 대용량 전송 |
| mq-deadline | 멀티큐 기반 Deadline | NVMe와 병렬 스토리지 최적화 | 단순성, 커스터마이징 제한 | NVMe SSD, HPC 병렬 파일시스템 |
최근 HPC 환경은 대부분 NVMe 기반 스토리지를 사용하기 때문에, 일반적으로 mq-deadline이나 NOOP을 우선 고려하는 경우가 많습니다.
동작 원리와 데이터 흐름
I/O 스케줄러는 다음과 같은 단계로 동작합니다.
- I/O 요청 수집 – 애플리케이션의 읽기·쓰기 요청을 커널이 수집합니다.
- 큐잉(Queuing) – 요청을 스케줄러 큐에 저장하고, 연속된 요청은 병합합니다.
- 스케줄링(Scheduling) – 알고리즘에 따라 요청 순서를 정합니다. (마감시간, 우선순위, 대역폭 고려)
- 디스패치(Dispatch) – 디바이스 드라이버에 요청을 전달합니다.
- 완료 처리 – 요청이 처리되면 애플리케이션에 결과가 반환됩니다.
이 과정에서 스케줄러를 어떤 방식으로 선택하느냐가 곧 지연과 처리량의 균형을 결정하게 됩니다.
HPC 환경 적용 사례
Lustre + NVMe 기반 환경
한 HPC 클러스터에서 Lustre 파일시스템과 NVMe SSD 조합을 사용했을 때, mq-deadline 스케줄러로 전환하고 큐 크기를 조정하여 성능을 개선한 사례가 있습니다.
# 현재 스케줄러 확인
cat /sys/block/nvme0n1/queue/scheduler
# mq-deadline으로 변경
echo mq-deadline | sudo tee /sys/block/nvme0n1/queue/scheduler
# 큐 크기 조정 (128 → 1024)
echo 1024 | sudo tee /sys/block/nvme0n1/queue/nr_requests조정 이후, 대규모 딥러닝 학습에서 I/O 대기 시간이 평균 18% 감소했고, 전체 학습 시간이 7% 단축되었습니다.
BeeGFS + SSD 환경
BeeGFS 메타데이터 서버에서는 NOOP 스케줄러를 적용했을 때 CPU 사용량이 줄고, 메타데이터 응답 지연이 개선되었습니다.
Ceph + HDD 환경
HDD 기반 Ceph 클러스터에서는 deadline 스케줄러를 적용해 지연 변동성을 줄였고, 대규모 백업 작업의 안정성이 크게 향상되었습니다.
벤치마크와 검증
I/O 스케줄러를 변경한 후에는 반드시 벤치마크 도구로 성능을 검증해야 합니다. 가장 많이 사용하는 툴은 fio입니다.
# 랜덤 읽기 성능 테스트
fio --name=randread --ioengine=libaio --rw=randread --bs=4k \
--numjobs=8 --size=1G --runtime=60 --group_reporting벤치마크 결과에서는 IOPS, 대역폭(MB/s), 평균 지연(latency)을 확인하고, 스케줄러 변경 전후를 비교해야 합니다. HPC 환경에서는 워크로드 특성(랜덤 I/O vs 순차 I/O, 읽기 vs 쓰기 비율)에 따라 최적의 스케줄러가 달라질 수 있으므로, 반드시 검증 과정을 거치셔야 합니다.
장점과 단점
장점
- 워크로드 특성에 맞게 선택하면 성능을 극대화할 수 있습니다.
- 지연 최소화 또는 처리량 극대화 전략을 명확하게 선택할 수 있습니다.
- 병렬 스토리지의 성능을 충분히 끌어낼 수 있습니다.
단점
- 잘못 선택할 경우 오히려 성능이 저하될 수 있습니다.
- 하드웨어 변경 시 다시 최적화를 진행해야 합니다.
- 커널 버전에 따라 스케줄러의 지원 범위가 다를 수 있습니다.
실무 팁과 주의사항
- NVMe 기반 병렬 파일시스템에서는 기본적으로 mq-deadline을 권장합니다.
- SSD 순차 읽기 위주의 워크로드라면 NOOP도 좋은 선택이 될 수 있습니다.
- HDD 기반 OLTP 시스템에서는 deadline이 더 안정적인 성능을 보장합니다.
- 스케줄러를 바꾼 후에는 반드시 fio, ioping, dd 등을 활용해 성능을 측정하시기 바랍니다.
- /sys/block/<device>/queue/* 경로에 있는 큐 관련 파라미터(nr_requests, scheduler)도 함께 조정하면 더욱 정밀한 최적화가 가능합니다.
정리하며
HPC에서 I/O 스케줄러는 단순한 커널 설정 옵션이 아니라 전체 워크로드 성능을 좌우하는 핵심 요소입니다. 올바른 스케줄러 선택과 파라미터 조정을 통해 수%에서 수십 %까지 성능 향상을 얻을 수 있으며, 특히 I/O 지연에 민감한 AI 학습, 시뮬레이션, 데이터 분석 워크로드에서는 효과가 더욱 두드러집니다.
운영자는 하드웨어 구조, 스토리지 타입, 워크로드 특성을 종합적으로 고려하여 스케줄러를 선택하고, 반드시 검증 과정을 통해 결과를 확인해야 합니다.
'HPC & GPU Engineering > Linux 성능 튜닝과 모니터링' 카테고리의 다른 글
| pdsh 가이드 | 수백 대 노드에 동시에 명령어 실행하기 (0) | 2025.10.17 |
|---|