이 글에서는 Kubernetes 모니터링의 핵심 요소인 메트릭의 개념과 효과적인 수집 방법에 대해 알아봅니다. 메트릭의 종류와 구조를 이해하고, Kubernetes 환경에서 다양한 계층의 메트릭을 어떻게 수집할지 살펴보겠습니다. 또한 실무에서 활용할 수 있는 주요 Exporter와 메트릭 수집 전략을 소개합니다.
📌 메트릭(Metrics)이란 무엇인가?
메트릭은 시스템의 상태를 수치화한 데이터로, 모니터링의 기본 단위입니다. 쿠버네티스와 같은 복잡한 분산 시스템에서는 다양한 계층에서 발생하는 메트릭을 통합적으로 수집하고 분석하는 것이 중요합니다.
✅ 메트릭의 정의
- 시간에 따른 숫자 기반 측정값
- 시계열 데이터(Time Series Data)의 형태
- 레이블을 통한 다차원 컨텍스트 제공
- 시스템의 동작과 상태를 정량적으로 표현
✅ 메트릭 vs 로그 vs 트레이싱
| 특성 | 메트릭 | 로그 | 트레이싱 |
| 데이터 형태 | 숫자 값(수치) | 텍스트 기반 이벤트 | 분산 트랜잭션 추적 |
| 데이터 양 | 상대적으로 적음 | 매우 많음 | 중간 수준 |
| 저장 효율성 | 높음 (압축 용이) | 낮음 | 중간 |
| 쿼리 성능 | 빠름 | 느림 | 중간 |
| 주요 용도 | 동향 파악, 알림 | 디버깅, 감사 | 성능 병목 분석 |
▶️ 메트릭의 중요성: "측정할 수 없으면 개선할 수 없다(You can't improve what you can't measure)" - 피터 드러커의 명언처럼, 메트릭은 시스템 개선의 첫 걸음입니다.
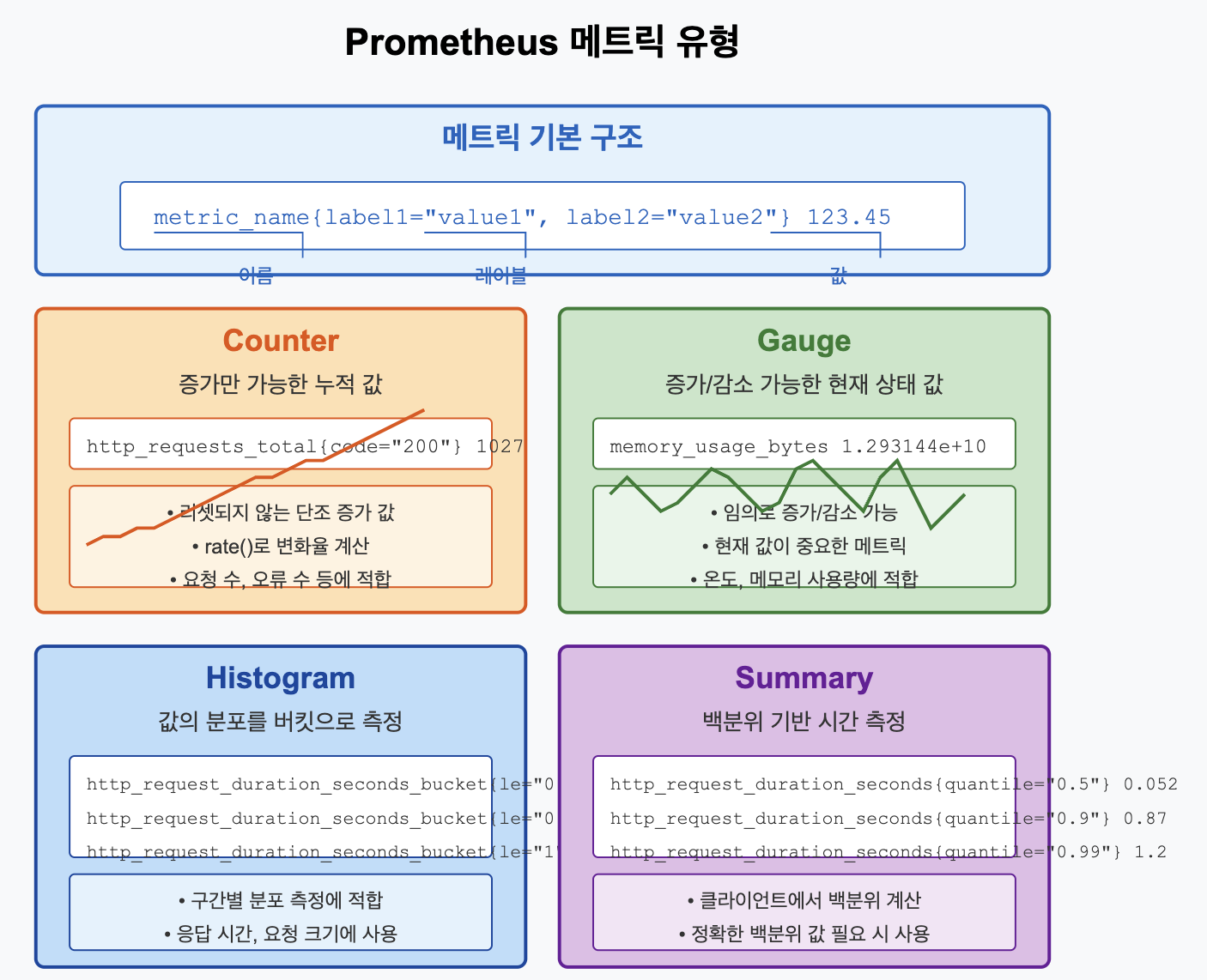
📌 Prometheus 메트릭 형식
Prometheus는 시계열 데이터로 모든 정보를 저장하며, 각 시계열은 메트릭 이름과 키-값 쌍인 레이블 세트로 고유하게 식별됩니다.
✅ 메트릭 이름 규칙
- 알파벳, 숫자, 언더스코어(_), 콜론(:) 사용
- 알파벳으로 시작
- 네임스페이스 구분을 위해 콜론 사용
- 일반적으로 스네이크 케이스(http_requests_total) 사용
- 접미사로 단위 표시(process_cpu_seconds_total)
# 메트릭 네이밍 예시
node_cpu_seconds_total # CPU 사용 시간 (초 단위)
http_requests_total # HTTP 요청 총 수
kube_pod_container_resource_limits_cpu_cores # 컨테이너 CPU 리밋 (코어 단위)
✅ 메트릭 형식 구조
Prometheus 메트릭은 다음과 같은 텍스트 형식으로 노출됩니다:
# HELP http_requests_total 총 HTTP 요청 수
# TYPE http_requests_total counter
http_requests_total{method="post",code="200",handler="/api/users"} 1027
http_requests_total{method="get",code="200",handler="/api/users"} 8343
- # HELP: 메트릭에 대한 설명
- # TYPE: 메트릭 유형(counter, gauge, histogram, summary)
- 메트릭 이름과 레이블: metric_name{label1="value1",label2="value2"}
- 값: 숫자 (정수 또는 부동소수점)
▶️ 명명 규칙 팁: 메트릭 이름은 그 목적을 명확히 나타내야 합니다. count나 total과 같은 접미사를 사용하여 누적 카운터임을 표시하거나, bytes, seconds, ratio와 같은 단위를 포함하여 메트릭 값의 단위를 명확히 합니다.
📌 메트릭 유형과 적절한 사용 사례
Prometheus는 네 가지 주요 메트릭 유형을 제공합니다. 각 유형은 특정 사용 사례에 적합합니다.
✅ Counter (카운터)
누적되는 단조 증가 값으로, 감소하지 않습니다(프로세스 재시작 시에만 0으로 리셋).
# 예시: 총 HTTP 요청 수
http_requests_total{method="GET", status="200"} 8734
적합한 사용 사례:
- 요청 수 카운팅
- 오류 발생 횟수
- 완료된 작업 수
- 처리된 바이트 수
주요 연산:
# 최근 5분간 초당 요청 비율 계산
rate(http_requests_total[5m])
# 최근 5분간 증가량
increase(http_requests_total[5m])
✅ Gauge (게이지)
현재 값을 표현하는 메트릭으로, 증가하거나 감소할 수 있습니다.
# 예시: 현재 메모리 사용량
node_memory_MemFree_bytes 1.293144e+10
적합한 사용 사례:
- 메모리/CPU 사용량
- 온도와 같은 물리적 측정값
- 현재 활성 연결 수
- 큐 크기
- 가용 디스크 공간
주요 연산:
# 현재 값
node_memory_MemFree_bytes
# 1시간 평균 값
avg_over_time(node_memory_MemFree_bytes[1h])
✅ Histogram (히스토그램)
값의 분포를 측정하기 위한 메트릭으로, 버킷(bucket)별로 관측값을 분류합니다.
# 예시: HTTP 요청 처리 시간 분포
http_request_duration_seconds_bucket{le="0.1"} 24054
http_request_duration_seconds_bucket{le="0.5"} 33444
http_request_duration_seconds_bucket{le="1.0"} 34435
http_request_duration_seconds_bucket{le="+Inf"} 34439
http_request_duration_seconds_sum 53423.504
http_request_duration_seconds_count 34439
적합한 사용 사례:
- 요청 지연 시간
- 응답 크기
- 작업 실행 시간
- 대기 시간 분포
주요 연산:
# 90번째 백분위수 계산
histogram_quantile(0.9, rate(http_request_duration_seconds_bucket[5m]))
✅ Summary (요약)
Histogram과 유사하지만, 클라이언트 측에서 백분위수를 계산합니다.
# 예시: API 응답 시간 요약
api_response_latency_seconds{quantile="0.5"} 0.042
api_response_latency_seconds{quantile="0.9"} 0.114
api_response_latency_seconds{quantile="0.99"} 0.323
api_response_latency_seconds_sum 53423.504
api_response_latency_seconds_count 34439
적합한 사용 사례:
- 클라이언트에서 정확한 백분위수 계산이 필요한 경우
- 네트워크 오버헤드 최소화가 중요한 경우
▶️ 유형 선택 가이드: 대부분의 경우 Counter와 Gauge가 충분합니다. 응답 시간과 같이 분포를 측정해야 할 때는 일반적으로 Histogram을 사용합니다. Summary는 서버 부하가 클 때 클라이언트에서 계산이 가능하지만, 이후 백분위수 집계가 어렵습니다.
📌 쿠버네티스에서의 메트릭 수집 계층
쿠버네티스 환경에서는 여러 계층에서 메트릭을 수집해야 합니다.

✅ 인프라 계층 메트릭
- 노드 수준: CPU, 메모리, 디스크, 네트워크 사용률 등
- 수집 방법: Node Exporter (호스트 시스템 메트릭)
# Node Exporter DaemonSet 예시 (주요 부분)
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
namespace: monitoring
labels:
app: node-exporter
spec:
selector:
matchLabels:
app: node-exporter
template:
metadata:
labels:
app: node-exporter
spec:
hostNetwork: true # 호스트 네트워크 사용 (포트 충돌 방지)
hostPID: true # 호스트 PID 네임스페이스 접근 (프로세스 정보 수집)
containers:
- name: node-exporter
image: prom/node-exporter:v1.5.0 # Node Exporter 최신 버전 사용
args:
- --path.procfs=/host/proc # 호스트의 /proc 마운트
- --path.sysfs=/host/sys # 호스트의 /sys 마운트
- --collector.filesystem.mount-points-exclude=^/(dev|proc|sys|var/lib/docker/.+|var/lib/kubelet/.+)($|/) # 특정 마운트포인트 제외
- --collector.netclass.ignored-devices=^(lo|veth.*)$ # 무시할 네트워크 디바이스
ports:
- containerPort: 9100 # Node Exporter 기본 포트
name: metrics
volumeMounts:
- name: proc # 호스트 /proc 마운트
mountPath: /host/proc
readOnly: true
- name: sys # 호스트 /sys 마운트
mountPath: /host/sys
readOnly: true
volumes:
- name: proc
hostPath:
path: /proc
- name: sys
hostPath:
path: /sys
✅ 컨테이너 계층 메트릭
- 컨테이너 수준: CPU/메모리 사용량, 제한, 요청, 네트워크 I/O 등
- 수집 방법: cAdvisor (kubelet에 내장됨)
# Prometheus 설정에서 kubelet 스크래핑 설정 예시
- job_name: 'kubernetes-cadvisor'
kubernetes_sd_configs:
- role: node # 노드 기반 서비스 디스커버리
scheme: https # kubelet은 HTTPS 사용
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt # K8s CA 인증서
insecure_skip_verify: true # 자체 서명 인증서 허용 (프로덕션에서는 주의 필요)
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token # 인증 토큰
relabel_configs:
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: node
replacement: $1
- source_labels: [__address__]
regex: (.+):(.+)
target_label: __address__
replacement: ${1}:10250 # kubelet metrics 포트
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /metrics/cadvisor # cAdvisor 메트릭 경로
✅ 쿠버네티스 객체 계층 메트릭
- 리소스 수준: 디플로이먼트, 파드, 서비스 상태 등
- 수집 방법: kube-state-metrics
# kube-state-metrics 주요 설정 예시
apiVersion: apps/v1
kind: Deployment
metadata:
name: kube-state-metrics
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app: kube-state-metrics
template:
metadata:
labels:
app: kube-state-metrics
spec:
serviceAccountName: kube-state-metrics # RBAC 권한 필요
containers:
- name: kube-state-metrics
image: registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.8.0
ports:
- containerPort: 8080 # 메트릭 포트
name: metrics
resources:
requests:
memory: "128Mi" # 최소 메모리 요청
cpu: "100m" # 최소 CPU 요청
limits:
memory: "256Mi" # 최대 메모리 제한
cpu: "200m" # 최대 CPU 제한
# 중요 kube-state-metrics 설정을 위한 Arguments 추가
args:
- --metric-labels-allowlist=pods=[app,component],deployments=[app,component] # 메트릭에 포함할 레이블 지정
- --metric-annotations-allowlist=pods=[prometheus.io/scrape,prometheus.io/port] # 메트릭에 포함할 어노테이션 지정
- --resources=pods,deployments,services,nodes,namespaces,persistentvolumes # 수집할 리소스 종류 지정
✅ 애플리케이션 계층 메트릭
- 앱 수준: 비즈니스 로직, 요청 수, 에러율, 응답 시간 등
- 수집 방법: 애플리케이션 내 클라이언트 라이브러리 또는 커스텀 Exporter
# Python 애플리케이션에서 Prometheus 메트릭 노출 예시
from flask import Flask
from prometheus_client import Counter, Histogram, generate_latest
import time
app = Flask(__name__)
# 메트릭 정의
REQUEST_COUNT = Counter(
'app_request_count', # 메트릭 이름
'Application Request Count', # 설명
['method', 'endpoint', 'status'] # 레이블
)
REQUEST_LATENCY = Histogram(
'app_request_latency_seconds', # 메트릭 이름
'Application Request Latency', # 설명
['method', 'endpoint'], # 레이블
buckets=[0.01, 0.05, 0.1, 0.5, 1, 2, 5] # 히스토그램 버킷 지정
)
@app.route('/metrics')
def metrics():
"""Prometheus 메트릭 엔드포인트"""
return generate_latest() # Prometheus 형식의 메트릭 반환
@app.route('/api/users')
def get_users():
"""유저 목록 API - 메트릭 계측"""
start_time = time.time()
# 실제 API 로직...
response_data = {"users": [...]}
status_code = 200
# 요청 지연시간 기록
REQUEST_LATENCY.labels(
method='GET',
endpoint='/api/users'
).observe(time.time() - start_time)
# 요청 카운트 증가
REQUEST_COUNT.labels(
method='GET',
endpoint='/api/users',
status=status_code
).inc()
return response_data, status_code
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
▶️ 계층별 메트릭 수집 전략: 각 계층의 메트릭을 적절히 조합하면 시스템 전체의 상태를 포괄적으로 파악할 수 있습니다. 예를 들어, 노드 레벨 CPU 사용률이 높다면 어떤 파드가 원인인지 컨테이너 메트릭을 확인하고, 해당 파드의 응답 시간이 느려졌는지 애플리케이션 메트릭을 함께 분석합니다.
📌 주요 Exporter와 활용
Prometheus 생태계에는 다양한 시스템과 애플리케이션에서 메트릭을 수집하기 위한 Exporter가 있습니다.
✅ 필수 Exporter
- Node Exporter
- 역할: 호스트 시스템 메트릭 수집
- 주요 메트릭: CPU, 메모리, 디스크, 네트워크, 파일시스템 등
- 유용한 대시보드: Grafana ID 1860 (Node Exporter Full)
# 주요 Node Exporter 메트릭 예시
node_cpu_seconds_total{mode="idle"} # CPU 유휴 시간
node_memory_MemAvailable_bytes # 사용 가능한 메모리
node_filesystem_avail_bytes # 파일시스템 가용 공간
node_network_receive_bytes_total # 네트워크 수신 바이트
node_disk_io_time_seconds_total # 디스크 I/O 시간
- kube-state-metrics
- 역할: 쿠버네티스 객체 상태 메트릭 수집
- 주요 메트릭: 파드 상태, 디플로이먼트, 노드, PVC 등
- 유용한 대시보드: Grafana ID 13332 (Kubernetes Cluster)
# 주요 kube-state-metrics 메트릭 예시
kube_pod_status_phase # 파드 상태 (Running, Failed 등)
kube_deployment_status_replicas_available # 디플로이먼트 가용 레플리카 수
kube_node_status_condition # 노드 상태 (Ready, DiskPressure 등)
kube_pod_container_resource_requests # 컨테이너 리소스 요청량
kube_pod_container_resource_limits # 컨테이너 리소스 제한
- Blackbox Exporter
- 역할: 블랙박스 모니터링 (프로브 기반 외부 모니터링)
- 주요 기능: HTTP, TCP, ICMP, DNS 프로브
- 유용한 대시보드: Grafana ID 7587 (Prometheus Blackbox Exporter)
# Blackbox Exporter 설정 예시 (blackbox.yml)
modules:
http_2xx: # HTTP 200-299 응답 확인
prober: http
timeout: 5s
http:
method: GET
preferred_ip_protocol: ip4 # IPv4 우선
valid_status_codes: [200, 201, 202, 203, 204] # 유효한 상태 코드
fail_if_ssl: false # SSL 사용 시 실패하지 않음
fail_if_not_ssl: false # SSL 미사용 시 실패하지 않음
tls_config:
insecure_skip_verify: false # 인증서 검증 수행
icmp: # ICMP 핑 테스트
prober: icmp
timeout: 5s
icmp:
preferred_ip_protocol: ip4 # IPv4 우선
dns_example: # DNS 확인
prober: dns
timeout: 5s
dns:
query_name: "kubernetes.io"
query_type: "A"
valid_rcodes: [NOERROR] # 유효한 응답 코드
✅ 데이터베이스 Exporter
- MySQL Exporter
- 주요 메트릭: 쿼리 실행 수, 연결 수, InnoDB 버퍼 풀 등
# MySQL Exporter 설정 예시
apiVersion: v1
kind: Secret
metadata:
name: mysql-exporter-secret
namespace: monitoring
type: Opaque
data:
# 'monitoring:password' 인코딩 문자열
data_source_name: bW9uaXRvcmluZzpwYXNzd29yZA==
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: mysql-exporter
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app: mysql-exporter
template:
metadata:
labels:
app: mysql-exporter
spec:
containers:
- name: mysql-exporter
image: prom/mysqld-exporter:v0.14.0
ports:
- containerPort: 9104
name: metrics
env:
- name: DATA_SOURCE_NAME
valueFrom:
secretKeyRef:
name: mysql-exporter-secret
key: data_source_name
# MySQL 커넥션 관련 설정 추가
args:
- --collect.info_schema.tables # 테이블 정보 수집
- --collect.info_schema.innodb_metrics # InnoDB 메트릭 수집
- --collect.global_status # 글로벌 상태 수집
- --collect.global_variables # 글로벌 변수 수집
- --collect.slave_status # 복제 상태 수집
- --collect.binlog_size # 바이너리 로그 크기 수집
# MySQL 접속 오버헤드 줄이기 위한 설정
- --collect.info_schema.processlist=false # 프로세스 리스트 비활성화
- PostgreSQL Exporter
- 주요 메트릭: 활성 연결, 데이터베이스 크기, 쿼리 실행 시간 등
- Redis Exporter
- 주요 메트릭: 메모리 사용량, 연결 수, 명령 처리 수 등
- MongoDB Exporter
- 주요 메트릭: 연결 수, 쿼리 수, 컬렉션 통계 등
✅ 메시징/캐시 시스템 Exporter
- RabbitMQ Exporter
- 주요 메트릭: 큐 크기, 메시지 속도, 소비자 수 등
- Kafka Exporter
- 주요 메트릭: 토픽 오프셋, 컨슈머 랙, 메시지 처리량 등
- Memcached Exporter
- 주요 메트릭: 적중률, 메모리 사용량, 연결 수 등
▶️ Exporter 선택 및 배포 팁: 필요한 Exporter만 배포하고, 각 Exporter의 공식 문서를 확인하여 리소스 요구사항을 파악하세요. 많은 Exporter는 특정 권한이 필요하므로 적절한 RBAC 설정이 중요합니다.
📌 효과적인 메트릭 수집 전략
메트릭을 효율적으로 수집하려면 몇 가지 핵심 전략이 필요합니다.
✅ 스크래핑 간격 최적화
# prometheus.yml 최적화 예시
global:
scrape_interval: 30s # 기본 스크래핑 간격 (30초)
evaluation_interval: 30s # 규칙 평가 간격 (30초)
scrape_configs:
- job_name: 'kubernetes-nodes'
scrape_interval: 60s # 노드 메트릭은 60초 간격 (변화가 느림)
kubernetes_sd_configs:
- role: node
# ...
- job_name: 'kubernetes-apiserver'
scrape_interval: 15s # API 서버는 15초 간격 (중요 컴포넌트)
kubernetes_sd_configs:
- role: endpoints
# ...
- job_name: 'high-volume-service'
scrape_interval: 5s # 중요 서비스는 5초 간격 (높은 정밀도 필요)
kubernetes_sd_configs:
- role: pod
# ...
✅ 샘플 제한 관리
# prometheus.yml 샘플 제한 설정
global:
scrape_interval: 30s
evaluation_interval: 30s
# 샘플 제한 설정
scrape_config:
sample_limit: 10000 # 작업당 최대 샘플 수 제한
✅ 카디널리티 관리
높은 카디널리티는 메모리 사용량을 크게 증가시킵니다. 다음과 같은 방법으로 관리할 수 있습니다:
- 불필요한 레이블 제거
# 레이블 제거 예시
scrape_configs:
- job_name: 'high-cardinality-target'
metric_relabel_configs:
# 필요 없는 레이블 삭제
- source_labels: [__name__]
regex: 'http_request_duration_seconds'
action: keep # 이 메트릭만 유지
- regex: 'id|uuid|email|trace_id|span_id' # 높은 카디널리티 유발 레이블
action: labeldrop # 레이블 삭제
- 집계 메트릭 활용
# 집계 규칙 예시 (prometheus-rules.yml)
groups:
- name: aggregation_rules
rules:
# 상세 요청 메트릭에서 상태 코드별 요약 메트릭 생성
- record: job:http_requests_total:sum_rate5m # 새 메트릭 이름
expr: sum(rate(http_requests_total[5m])) by (job, status_code) # 작업과 상태 코드로만 집계
# 노드별 CPU 사용률 집계
- record: node:cpu_usage:avg_5m
expr: avg by (node) (rate(node_cpu_seconds_total{mode!="idle"}[5m]))
✅ 적응형 스크래핑 구현
# 어노테이션 기반 스크래핑 설정
scrape_configs:
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
# 스크래핑 활성화된 파드만 선택
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
# 커스텀 스크래핑 간격 파드별 설정
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape_interval]
regex: (.+)
target_label: __scrape_interval__
replacement: ${1}
# 커스텀 스크래핑 타임아웃 파드별 설정
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape_timeout]
regex: (.+)
target_label: __scrape_timeout__
replacement: ${1}
# 메트릭 경로 커스터마이징
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
regex: (.+)
target_label: __metrics_path__
replacement: ${1}
# 타겟 포트 커스터마이징
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
regex: ([^:]+)(?::\d+)?;(\d+)
target_label: __address__
replacement: $1:$2
✅ 멀티 스크레이핑 전략
대규모 클러스터에서는 여러 Prometheus 인스턴스를 사용한 샤딩이 효과적입니다.
# Prometheus 샤딩 예시 - 첫 번째 인스턴스
scrape_configs:
- job_name: 'sharded-kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
# Prometheus 샤딩 ID를 기반으로 파드 필터링
# (파드 이름 해시가 0-4 범위에 있는 경우)
- source_labels: [__meta_kubernetes_pod_name]
regex: (.*)
modulus: 10 # 10개 샤드 가정
target_label: __tmp_hash
action: hashmod
- source_labels: [__tmp_hash]
regex: ^[0-4]$ # 0-4 범위의 해시만 스크래핑 (나머지는 다른 Prometheus 인스턴스에서)
action: keep
▶️ 설계 원칙: "수집은 덜, 보관은 짧게, 집계는 더 많이" - 이 원칙을 따르면 리소스를 효율적으로 사용하면서 필요한 인사이트를 얻을 수 있습니다.
📌 메트릭 라벨링 모범 사례
라벨은 메트릭의 문맥을 제공하는 중요한 요소입니다. 효과적인 라벨링 전략은 모니터링 시스템의 유용성을 크게 향상시킵니다.
✅ 핵심 라벨링 원칙
- 일관성 유지: 모든 메트릭에 공통 라벨 적용
- 간결성 유지: 필요한 최소한의 라벨만 사용
- 의미적 명확성: 라벨 이름과 값이 명확하게 의미 전달
# Prometheus 레이블 재작성 예시
scrape_configs:
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
# 애플리케이션 레이블 추가
- source_labels: [__meta_kubernetes_pod_label_app]
target_label: app
replacement: $1
# 네임스페이스 추가
- source_labels: [__meta_kubernetes_namespace]
target_label: namespace
replacement: $1
# 클러스터 정보 추가
- target_label: cluster
replacement: 'production-us-east' # 클러스터 식별자
# 환경 정보 추가
- target_label: env
replacement: 'production' # 환경 식별자
✅ 추천 표준 라벨
모든 메트릭에 다음과 같은 표준 라벨 세트를 고려하세요:
- cluster: 클러스터 식별자
- namespace: 쿠버네티스 네임스페이스
- app: 애플리케이션 식별자
- service: 서비스 이름
- instance: 인스턴스 ID/호스트 이름
- env: 환경 (prod, dev, staging 등)
- team: 담당 팀
✅ 라벨 카디널리티 관리
과도한 카디널리티를 방지하기 위해 다음과 같은 라벨은 피해야 합니다:
- 사용자 ID, 이메일 주소
- 세션 ID, 요청 ID
- IP 주소 (세분화된 분석이 필요한 경우 외에는)
- 타임스탬프
- 상세 URL 경로 (패턴화된 경로 사용)
# 높은 카디널리티 제어 예시
scrape_configs:
- job_name: 'api-server'
metric_relabel_configs:
# URL 경로를 패턴화
- source_labels: [path]
regex: '/api/users/[0-9]+'
target_label: path
replacement: '/api/users/:id'
# 임의 요청 ID 제거
- regex: 'request_id'
action: labeldrop
▶️ 라벨링 팁: "모든 것을 라벨링하지 말고, 정말 필요한 것만 라벨링하세요." 라벨은 쿼리 유연성을 제공하지만, 각 고유한 라벨 조합이 새로운 시계열을 생성하여 메모리 사용량을 증가시킵니다.
📌 서비스 디스커버리 최적화
쿠버네티스 환경에서는 서비스 디스커버리를 통해 메트릭 타겟을 자동으로 찾을 수 있습니다.
✅ 주요 서비스 디스커버리 유형
# 다양한 서비스 디스커버리 유형 예시
scrape_configs:
# 노드 디스커버리
- job_name: 'kubernetes-nodes'
kubernetes_sd_configs:
- role: node # 클러스터의 모든 노드 검색
# 서비스 디스커버리
- job_name: 'kubernetes-services'
kubernetes_sd_configs:
- role: service # 모든 서비스 검색
# 엔드포인트 디스커버리
- job_name: 'kubernetes-endpoints'
kubernetes_sd_configs:
- role: endpoints # 서비스 엔드포인트 검색
# 파드 디스커버리
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod # 모든 파드 검색
# 인그레스 디스커버리
- job_name: 'kubernetes-ingresses'
kubernetes_sd_configs:
- role: ingress # 모든 인그레스 검색
✅ 관련 메타데이터 활용
서비스 디스커버리는 다양한 메타데이터를 제공하며, 이를 레이블로 활용할 수 있습니다:
# 메타데이터 활용 예시
scrape_configs:
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
# 파드 이름 추가
- source_labels: [__meta_kubernetes_pod_name]
target_label: pod
# 노드 이름 추가
- source_labels: [__meta_kubernetes_pod_node_name]
target_label: node
# 컨테이너 이름 추가
- source_labels: [__meta_kubernetes_pod_container_name]
target_label: container
# 워크로드 정보 추가
- source_labels: [__meta_kubernetes_pod_controller_kind]
target_label: workload_kind
- source_labels: [__meta_kubernetes_pod_controller_name]
target_label: workload_name
# 레이블 추가
- source_labels: [__meta_kubernetes_pod_label_app_kubernetes_io_name]
target_label: app_name
- source_labels: [__meta_kubernetes_pod_label_app_kubernetes_io_instance]
target_label: app_instance
✅ 필터링과 성능 최적화
모든 파드나 서비스를 스크래핑하는 것은 비효율적일 수 있습니다. 선별적인 타겟 필터링이 중요합니다:
# 필터링 예시
scrape_configs:
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
# 메트릭 노출 파드만 스크래핑
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
# 특정 네임스페이스만 스크래핑
- source_labels: [__meta_kubernetes_namespace]
action: keep
regex: 'default|kube-system|monitoring' # 특정 네임스페이스만 포함
# 특정 워크로드 유형 제외
- source_labels: [__meta_kubernetes_pod_controller_kind]
action: drop
regex: 'Job|CronJob' # 임시 작업은 제외
▶️ 성능 최적화 팁: 대규모 클러스터에서는 네임스페이스별로 별도의 Prometheus 인스턴스를 실행하거나, role: pod 대신 role: service나 role: endpoints를 사용하여 스크래핑 타겟 수를 줄이는 것을 고려하세요.
📌 메트릭 확장 및 사용자 정의
기본 제공되는 메트릭 외에도 비즈니스 관련 메트릭을 정의하고 수집하면 더 풍부한 인사이트를 얻을 수 있습니다.
✅ 애플리케이션 수준 메트릭 정의
// Java 애플리케이션에서 Micrometer를 사용한 메트릭 예시
import io.micrometer.core.instrument.*;
import io.micrometer.prometheus.PrometheusConfig;
import io.micrometer.prometheus.PrometheusMeterRegistry;
public class MetricsConfig {
private final PrometheusMeterRegistry registry =
new PrometheusMeterRegistry(PrometheusConfig.DEFAULT);
// 카운터 메트릭 - 주문 처리 수
private Counter orderProcessed = Counter
.builder("orders_processed_total")
.description("총 처리된 주문 수")
.tags("region", "us-east")
.register(registry);
// 게이지 메트릭 - 장바구니 크기
private Gauge cartSize = Gauge
.builder("shopping_cart_size", shoppingCartService, ShoppingCartService::getActiveCartCount)
.description("현재 활성 장바구니 수")
.tags("status", "active")
.register(registry);
// 타이머 메트릭 - 결제 처리 시간
private Timer paymentTimer = Timer
.builder("payment_processing_seconds")
.description("결제 처리 시간")
.tags("payment_method", "credit_card")
.publishPercentiles(0.5, 0.95, 0.99) // 50번째, 95번째, 99번째 백분위수 계산
.register(registry);
// 메트릭 활용 예시
public void processOrder(Order order) {
paymentTimer.record(() -> {
// 결제 처리 로직
paymentService.process(order);
});
// 주문 처리 후 카운터 증가
orderProcessed.increment();
}
// Prometheus 메트릭 엔드포인트
public String getMetricsData() {
return registry.scrape();
}
}
✅ 사용자 정의 지표 모범 사례
- 비즈니스 KPI 메트릭
- 사용자 회원가입 수: user_registrations_total
- 일일 활성 사용자: daily_active_users
- 완료된 주문: orders_completed_total
- 장바구니 포기율: cart_abandonment_ratio
- 서비스 수준 지표
- API 성공/실패 비율: api_requests_total{status="success|failure"}
- 작업 완료 시간: task_completion_seconds
- 리소스 사용률: resource_utilization_ratio
- 시스템 상태 지표
- 큐 깊이: queue_depth
- 커넥션 풀 사용률: connection_pool_usage_ratio
- 캐시 적중률: cache_hit_ratio
✅ 메트릭 명명 규칙
# 메트릭 명명 규칙 예시
# 1. 접두사로 도메인 지정
api_requests_total
database_connections_active
cache_hits_total
# 2. 단위를 접미사로 지정
request_duration_seconds
response_size_bytes
memory_usage_bytes
# 3. 누적 값에 _total 접미사 사용
errors_total
requests_total
bytes_transferred_total
# 4. 현재 값에는 접미사 없음 또는 상태 표시
connections_active
pods_running
cache_items
▶️ 메트릭 설계 원칙: "유의미한 비즈니스 컨텍스트를 갖는 메트릭을 선택하세요." 기술적 메트릭도 중요하지만, 비즈니스 가치와 연결된 메트릭이 의사 결정에 더 유용합니다.
📌 Summary: 효과적인 메트릭 수집을 위한 핵심 원칙
- 계층적 접근: 인프라, 쿠버네티스, 애플리케이션 계층의 메트릭을 모두 수집하여 완전한 뷰 확보
- 목적 중심 설계: 모니터링 목적에 맞는 메트릭 선택 및 수집 빈도 설정
- 카디널리티 관리: 필수적인 라벨만 사용하고 레이블 값의 카디널리티 제한
- 자동화된 디스커버리: 쿠버네티스 서비스 디스커버리를 활용한 타겟 자동 발견
- 표준화: 일관된 명명 규칙과 라벨링 체계 적용
- 비즈니스 관련성: 기술적 메트릭과 비즈니스 KPI를 연결하는 메트릭 설계
- 성능 균형: 데이터 정밀도와 시스템 부하 간의 균형 유지
- 점진적 확장: 필수 메트릭부터 시작하여 필요에 따라 점진적으로 확장