이번 글에서는 프로메테우스와 그라파나를 활용한 Observability 구성 시리즈의 두 번째 포스트로, 효과적인 메트릭 이해와 가용성 측정, 그리고 구글이 제안한 골든 시그널에 대해 알아보겠습니다.
📌 메트릭의 기본 개념
메트릭은 시스템의 상태나 성능을 수치적으로 표현한 데이터로, Observability의 핵심 구성 요소 중 하나입니다. 메트릭은 시간에 따라 변화하는 값을 시계열 형태로 수집하고 저장하여 시스템의 동작과 추세를 파악할 수 있게 해줍니다.
✅ 메트릭의 특징
- 수치적: 메트릭은 숫자 형태로 표현되어 수학적 분석이 가능합니다.
- 시계열 데이터: 타임스탬프와 함께 저장되어 시간에 따른 변화를 추적합니다.
- 집계 가능: 합계, 평균, 백분위수 등으로 집계하여 분석할 수 있습니다.
- 낮은 저장 비용: 로그나 트레이스에 비해 저장 공간을 적게 차지합니다.
- 장기 보관 가능: 압축하여 장기간 보관할 수 있어 추세 분석에 유리합니다.
📌 메트릭의 주요 유형
효과적인 시스템 모니터링을 위해서는 다양한 유형의 메트릭을 이해하고 적절히 활용하는 것이 중요합니다. 각 메트릭 유형은 시스템의 다른 측면을 측정하고 분석하는 데 특화되어 있습니다.
✅ 카운터(Counter)
카운터는 시간이 지남에 따라 증가만 하는 단조 증가(monotonically increasing) 값입니다.
▶️ 특징:
- 리셋되지 않는 한 항상 증가하거나 동일합니다(감소하지 않음)
- 시스템 재시작 시 0으로 초기화될 수 있습니다
- 주로 '총 이벤트 수'를 측정합니다
▶️ 사용 예:
- 총 요청 수
- 처리된 작업 수
- 오류 발생 횟수
- 네트워크 패킷 전송량
▶️ 측정 및 분석:
카운터는 주로 rate() 함수를 사용하여 특정 시간 간격 동안의 변화율을 계산합니다. 예를 들어, 초당 요청 수(RPS)를 측정하려면 다음과 같이 계산합니다:
# 최근 5분간의 초당 요청 수 계산
rate(http_requests_total[5m])
✅ 게이지(Gauge)
게이지는 시간에 따라 증가하거나 감소할 수 있는 순간 값입니다.
▶️ 특징:
- 현재 상태를 나타내는 스냅샷 값입니다
- 증가하거나 감소할 수 있습니다
- 주로 '현재 값'을 측정합니다
▶️ 사용 예:
- 현재 CPU 사용률
- 메모리 사용량
- 현재 활성 연결 수
- 큐 크기
- 온도 측정값
▶️ 측정 및 분석:
게이지는 일반적으로 즉각적인 값을 관찰하거나 시간에 따른 변화 추세를 분석하는 데 사용됩니다.
# 현재 메모리 사용량
node_memory_used_bytes
# 5분 동안의 평균 CPU 사용률
avg_over_time(cpu_usage_percent[5m])
✅ 히스토그램(Histogram)
히스토그램은 값의 분포를 측정하고 버킷으로 집계합니다.
▶️ 특징:
- 값을 사전 정의된 버킷으로 분류합니다
- 분위수(percentile)를 계산할 수 있습니다
- 값의 분포와 이상치를 파악하는 데 유용합니다
▶️ 사용 예:
- 요청 지연 시간
- 응답 크기
- 작업 처리 시간
▶️ 측정 및 분석:
히스토그램은 특정 임계값 이상의 비율이나 분위수(예: 95번째 백분위수)를 계산하는 데 사용됩니다.
# 95번째 백분위수의 요청 지연 시간
histogram_quantile(0.95, rate(http_request_duration_seconds_bucket[5m]))
✅ 서머리(Summary)
서머리는 히스토그램과 유사하지만, 클라이언트 측에서 계산된 분위수를 직접 추적합니다.
▶️ 특징:
- 클라이언트 측에서 분위수를 계산합니다
- 더 정확한 분위수를 제공할 수 있지만, 계산 비용이 높습니다
- 서버에서의 집계가 어렵습니다
▶️ 사용 예:
- 응답 시간 분포
- 리소스 사용량 분포

📌 가용성과 SLI/SLO/SLA
시스템의, 특히 서비스로 제공되는 시스템의 가장 중요한 특성 중 하나는 가용성(Availability)입니다. 가용성은 시스템이 사용자에게 서비스를 제공할 수 있는 시간의 비율을 나타냅니다.
✅ 가용성 측정 방법
가용성은 일반적으로 다음과 같은 공식으로 계산됩니다:
가용성(%) = (전체 시간 - 장애 시간) / 전체 시간 × 100
예를 들어, 한 달(30일)의 가동 시간 중 43분 동안 서비스를 이용할 수 없었다면:
가용성(%) = (43,200분 - 43분) / 43,200분 × 100 = 99.9%
이는 "세 개의 9(three nines)" 가용성에 해당합니다.
✅ 가용성 수준과 의미
가용성 월간 다운타임 연간 다운타임 일반적인
| 90% (1개의 9) | 72시간 | 36.5일 | 취미 웹사이트 |
| 99% (2개의 9) | 7.2시간 | 3.65일 | 내부 기업 시스템 |
| 99.9% (3개의 9) | 43분 | 8.76시간 | 대부분의 웹 서비스 |
| 99.99% (4개의 9) | 4.3분 | 52.6분 | 중요 비즈니스 애플리케이션 |
| 99.999% (5개의 9) | 26초 | 5.26분 | 전화 시스템, 결제 시스템 |
| 99.9999% (6개의 9) | 2.6초 | 31.5초 | 항공, 의료, 금융 시스템 |
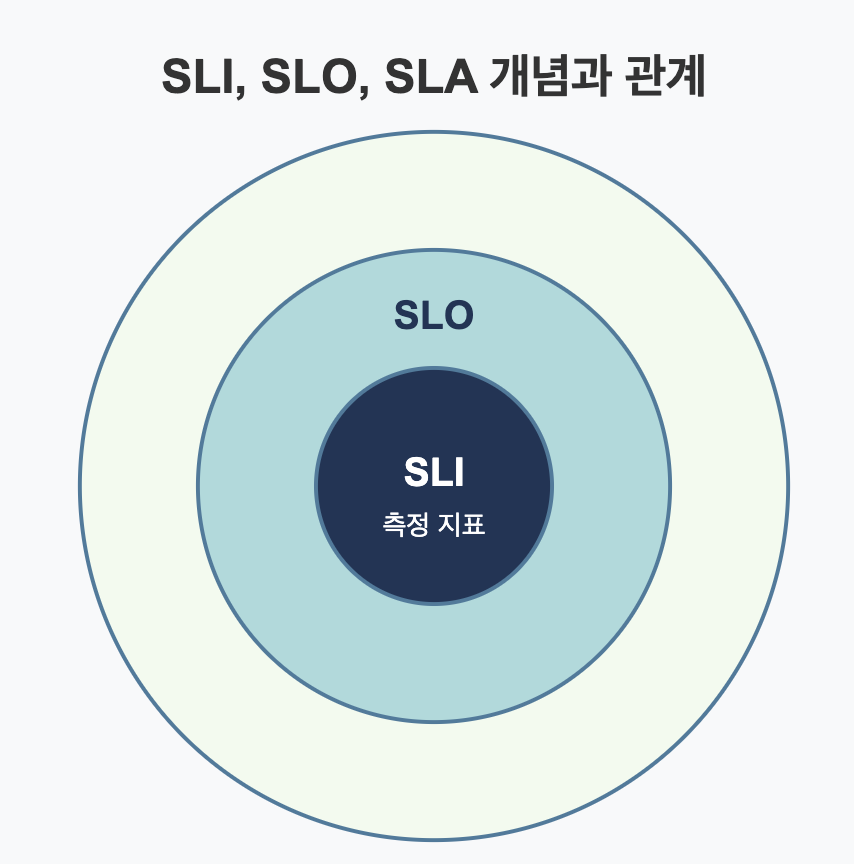
✅ SLI, SLO, SLA 개념
가용성을 측정하고 관리하기 위해 다음과 같은 개념들이 사용됩니다:
▶️ SLI (Service Level Indicator)
서비스 수준 지표는 서비스의 특정 측면을 측정하는 실제 메트릭입니다.
- 예시: 요청 지연 시간, 오류율, 시스템 처리량, 가용성 등
- 특징: 객관적이고 측정 가능한 수치로 표현됩니다
- 용도: 서비스 성능을 정량적으로 측정하고 모니터링합니다
▶️ SLO (Service Level Objective)
서비스 수준 목표는 SLI에 대한 목표값으로, 내부적으로 설정한 성능 기준입니다.
- 예시: "월간 99.9% 가용성", "95% 요청의 응답 시간 < 200ms"
- 특징: 팀 내부에서 설정하고 모니터링하는 목표입니다
- 용도: 시스템이 충족해야 할 내부 성능 기준을 정의합니다
▶️ SLA (Service Level Agreement)
서비스 수준 계약은 서비스 제공자와 고객 간의 공식적인 계약으로, 제공되는 서비스 수준을 명시합니다.
- 예시: "월간 99.5% 가용성 보장, 미달 시 요금 환불"
- 특징: 법적 구속력이 있는 비즈니스 계약입니다
- 용도: 서비스 실패 시 책임과 보상 범위를 정의합니다