이 글에서는 Apache Kafka의 기본 개념, 탄생 배경과 문제 해결 목적을 알아보겠습니다. 분산 시스템의 메시지 처리에 관심 있는 분들에게 Kafka가 왜 중요한지, 그리고 어떤 특징을 가지고 있는지 명확히 이해할 수 있도록 도와드립니다.
📌 Kafka의 정의와 핵심 특징
Kafka는 LinkedIn에서 개발되어 2011년 오픈소스로 공개된 분산 이벤트 스트리밍 플랫폼입니다. 간단히 말하면, Kafka는 다양한 시스템 간에 대용량 데이터를 안정적으로 주고받을 수 있게 해주는 메시징 시스템입니다.
✅ Kafka의 세 가지 핵심 기능
- 데이터 스트림 발행(publish)과 구독(subscribe) - 다른 시스템에서 발생한 이벤트를 실시간으로 주고받을 수 있습니다
- 데이터 스트림 저장 - 내구성 있게 데이터를 저장하여 필요할 때 다시 처리할 수 있습니다
- 데이터 스트림 처리 - 들어오는 데이터를 실시간으로 변환하거나 집계할 수 있습니다
✅ Kafka의 주요 특징
- 고성능 - 초당 수백만 개의 메시지를 처리할 수 있는 높은 처리량
- 확장성 - 필요에 따라 브로커(서버)를 추가하여 수평적으로 확장 가능
- 내구성 - 데이터 복제를 통해 장애 상황에서도 데이터 손실 방지
- 분산 처리 - 여러 서버에 부하를 분산하여 효율적인 처리 가능
▶️ 예시: 기본적인 Kafka 구조
[Producer] → [Kafka Cluster (Broker1, Broker2, Broker3)] → [Consumer]
📌 Kafka의 탄생 배경
LinkedIn이라는 대규모 소셜 네트워크에서 Kafka가 탄생하게 된 이유를 살펴보면 Kafka의 존재 이유를 더 잘 이해할 수 있습니다.
✅ LinkedIn의 도전과제
- 다양한 웹 서비스와 백엔드 시스템 간의 복잡한 데이터 파이프라인
- 점점 늘어나는 데이터 양과 시스템 간 통합 복잡도
- 기존 메시징 시스템의 확장성 제한
✅ 기존 시스템의 한계
- 대량의 데이터를 처리하기에 충분한 처리량 부족
- 데이터 영속성(persistence) 부재로 장애 시 복구 어려움
- 확장 시 성능 저하 발생
LinkedIn의 엔지니어들은 이러한 문제를 해결하기 위해 분산 시스템 원칙을 기반으로 한 새로운 접근법이 필요하다고 판단했고, 그 결과 Kafka가 탄생했습니다.

📌 Kafka가 해결하는 문제들
Kafka는 현대 데이터 아키텍처에서 다음과 같은 핵심 문제들을 해결합니다.
✅ 데이터 통합 문제
- 기존 방식: 시스템 A와 B를 연결하고, B와 C를 연결하는 등 개별 연결 구성
- 시스템이 n개일 때, 최대 n(n-1)/2개의 연결이 필요
- 각 연결마다 다른 프로토콜과 데이터 형식 처리 필요
- Kafka 방식: 모든 시스템이 Kafka와만 통신
- 시스템이 n개일 때, n개의 연결만 필요
- 표준화된 통신 방식으로 통합 단순화
✅ 실시간 처리 문제
- 기존 방식: 배치 처리 위주로 인한 지연 시간 발생
- Kafka 방식: 이벤트 발생 즉시 처리 가능한 스트리밍 아키텍처 제공
✅ 확장성 문제
- 기존 방식: 트래픽 증가에 따른 성능 저하
- Kafka 방식: 브로커 추가만으로 수평적 확장 가능
✅ 장애 복구 문제
- 기존 방식: 메시지 손실 위험과 복구 메커니즘 부재
- Kafka 방식: 데이터 복제와 파티션 분산으로 내결함성 확보
▶️ Kafka 적용 사례
- 사용자 활동 추적 (클릭, 검색, 페이지뷰 등)
- 로그 수집 및 분석
- 시스템 간 데이터 동기화
- 실시간 모니터링 및 알림
- IoT 센서 데이터 처리
- 마이크로서비스 간 비동기 통신
📌 Kafka의 아키텍처 개요
Kafka의 기본 아키텍처는 크게 네 가지 핵심 구성요소로 이루어져 있습니다.
✅ Producer (생산자)
- 데이터를 생성하여 Kafka에 전송하는 애플리케이션
- 다양한 소스(웹서버, 센서, 로그 등)에서 데이터 수집 가능
- 메시지를 어떤 토픽과 파티션으로 보낼지 결정
✅ Broker (브로커)
- Kafka 서버를 의미하며, 여러 브로커가 모여 클러스터 구성
- 데이터를 수신하고 저장하며 Consumer의 요청에 응답
- 각 브로커는 특정 토픽의 파티션들을 관리
✅ Consumer (소비자)
- Kafka에서 데이터를 읽어가는 애플리케이션
- 개별 또는 컨슈머 그룹을 형성하여 병렬 처리 가능
- 자신이 어디까지 읽었는지(offset) 직접 관리
✅ ZooKeeper (주키퍼)
- Kafka 클러스터의 메타데이터 관리 (최근 버전에서는 선택적)
- 브로커 상태 모니터링 및 리더 선출
- 토픽 구성 정보 저장
📌 Kafka vs 전통적인 메시징 시스템
Kafka와 기존 메시징 시스템의 차이점을 이해하면 Kafka의 혁신적인 면을 더 잘 이해할 수 있습니다.
✅ 메시지 저장 방식
- 전통적 메시징 시스템: 소비된 메시지는 즉시 또는 짧은 시간 내에 삭제
- Kafka: 구성된 보존 기간(기본 7일) 동안 메시지 유지
✅ 메시지 소비 패턴
- 전통적 메시징 시스템: Push 방식 (브로커가 소비자에게 메시지 전달)
- Kafka: Pull 방식 (소비자가 능동적으로 메시지 요청)
✅ 확장성
- 전통적 메시징 시스템: 단일 큐에 대한 확장 제한적
- Kafka: 파티션 기반 분산으로 높은 확장성
✅ 처리 보장
- 전통적 메시징 시스템: 대부분 exactly-once 전달 추구
- Kafka: at-least-once 기본 제공, exactly-once는 추가 설정 필요
▶️ 비교 표
| 특성 | 전통적 메시징 시스템 (RabbitMQ, ActiveMQ) | Kafka |
| 주요 용도 | 작업 큐, 요청-응답 패턴 | 스트리밍, 로그 수집 |
| 메시지 보존 | 소비 후 삭제 | 설정된 기간 동안 유지 |
| 전송 방식 | Push | Pull |
| 처리량 | 중간 | 매우 높음 |
| 지연 시간 | 낮음 | 약간 높음 |
| 메시지 순서 | 엄격한 FIFO | 파티션 내에서만 보장 |
📌 Kafka의 발전과 생태계
Kafka는 처음 LinkedIn에서 개발된 이후 빠르게 성장하여 다양한 기업과 산업에서 핵심 인프라로 자리잡았습니다.
✅ Kafka의 발전 과정
- 2011년: LinkedIn에서 오픈소스로 공개
- 2014년: LinkedIn의 엔지니어들이 Confluent 설립
- 2017년: Kafka Streams 추가로 스트림 처리 기능 강화
- 2019년: Kafka Connect 생태계 확장으로 다양한 시스템 연동 간소화
- 2022년: KRaft 모드 도입으로 ZooKeeper 의존성 제거 시작
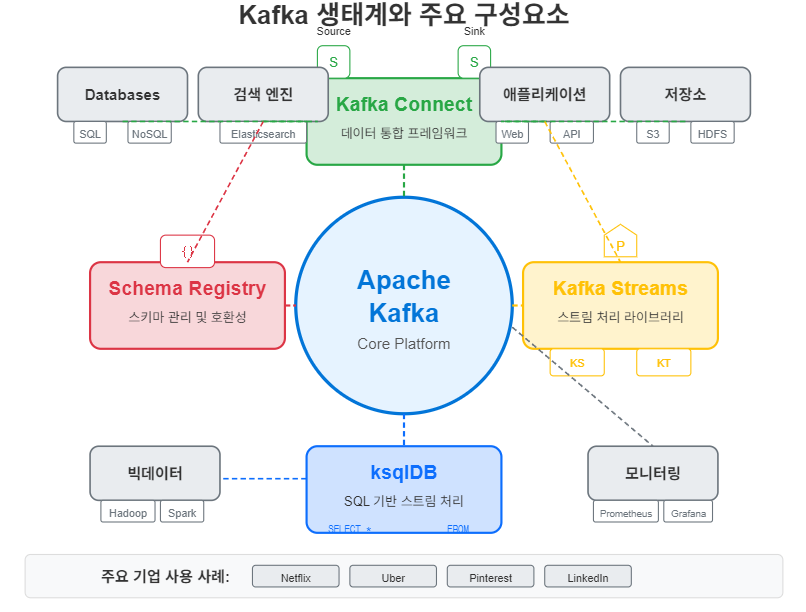
✅ Kafka 생태계 구성요소
- Kafka Connect: 외부 시스템과의 데이터 통합 프레임워크
- Kafka Streams: 스트림 처리를 위한 클라이언트 라이브러리
- ksqlDB: SQL 기반 스트림 처리 엔진
- Schema Registry: 데이터 스키마 관리 및 진화 지원
✅ 주요 기업 적용 사례
- Netflix: 실시간 모니터링 및 추천 시스템
- Uber: 승차 요청, 위치 데이터 처리
- Pinterest: 사용자 활동 추적 및 분석
- Goldman Sachs: 금융 거래 처리
📌 Kafka 시작하기 위한 준비
Kafka를 시작하기 위해 알아두면 좋은 기본 개념들을 정리해보겠습니다.
✅ 알아두면 좋은 핵심 용어
- Topic: 특정 유형의 메시지를 위한 채널
- Partition: 토픽을 분할하여 병렬 처리를 가능하게 하는 단위
- Offset: 파티션 내 메시지 위치를 나타내는 순차적 ID
- Consumer Group: 하나의 토픽을 공동으로 소비하는 컨슈머 집합
- Replication Factor: 데이터 복제본 수로, 안정성을 결정하는 값
✅ 시작하기 전 고려할 점
- 시스템 요구사항 (메모리, 디스크 공간, 네트워크 대역폭)
- 개발 환경 vs 운영 환경 구성 차이
- 보안 요구사항 (인증, 권한, 암호화)
- 모니터링 전략
✅ 사용 가능한 클라이언트 라이브러리
- Java (공식 클라이언트)
- Python (kafka-python, confluent-kafka-python)
- Node.js (KafkaJS, node-rdkafka)
- Go (sarama, confluent-kafka-go)
- .NET (Confluent.Kafka)
📌 Summary
- Kafka는 LinkedIn에서 개발된 분산 이벤트 스트리밍 플랫폼으로, 고성능과 확장성이 특징입니다.
- 복잡한 시스템 간 데이터 통합, 실시간 처리, 확장성, 장애 복구 문제를 효과적으로 해결합니다.
- Producer, Broker, Consumer, ZooKeeper라는 4가지 핵심 구성요소로 이루어져 있습니다.
- 전통적인 메시징 시스템과 달리 데이터를 지정 기간 동안 보존하고 Pull 방식으로 소비합니다.
- 다양한 산업과 기업에서 실시간 데이터 파이프라인 구축에 활용되고 있습니다.
- Kafka Connect, Kafka Streams, ksqlDB 등 풍부한 생태계를 갖추고 있습니다.
'Data Engineering > Kafka' 카테고리의 다른 글
| [Kafka 초보자 가이드 Ep.02] 메시지 큐와 Kafka의 차이점 (2) | 2025.04.12 |
|---|