이 글에서는 Airflow에서 Task 간 의존성을 설정하는 다양한 방법과 트리거 규칙에 대해 자세히 알아봅니다. 복잡한 워크플로우를 위한 다양한 의존성 패턴과 조건부 실행 방법을 실제 코드 예제와 함께 살펴보겠습니다.
📌 기본 의존성 설정 방법
✅ 비트시프트 연산자 (>>, <<)
Airflow에서 Task 간 의존성을 설정하는 가장 직관적인 방법은 비트시프트 연산자(>>, <<)를 사용하는 것입니다.

# 비트시프트 연산자를 사용한 기본 의존성 설정
# 필요한 모듈 임포트
from datetime import datetime, timedelta # 날짜/시간 처리를 위한 모듈
from airflow import DAG # DAG 객체 임포트
from airflow.operators.bash import BashOperator # Bash 명령어 실행 연산자
from airflow.operators.python import PythonOperator # Python 함수 실행 연산자
# DAG의 기본 인자 설정
default_args = {
'owner': 'airflow', # DAG 소유자 설정
'depends_on_past': False, # 이전 DAG 실행 결과에 의존하지 않음
'start_date': datetime(2023, 1, 1), # DAG 시작 날짜
'email_on_failure': False, # 실패 시 이메일 알림 비활성화
'email_on_retry': False, # 재시도 시 이메일 알림 비활성화
'retries': 1, # 실패 시 재시도 횟수
'retry_delay': timedelta(minutes=5), # 재시도 간격 (5분)
}
# DAG 정의
dag = DAG(
'dependency_example', # DAG ID
default_args=default_args, # 위에서 정의한 기본 인자 적용
description='Task dependency example DAG', # DAG 설명
schedule_interval=timedelta(days=1), # 매일 실행 (일간 간격)
)
# 태스크 1 정의 - Bash 명령어 실행
task_1 = BashOperator(
task_id='task_1', # 태스크 ID
bash_command='echo "Executing Task 1"', # 실행할 Bash 명령어
dag=dag, # 이 태스크가 속한 DAG
)
# 태스크 2 정의 - Bash 명령어 실행
task_2 = BashOperator(
task_id='task_2', # 태스크 ID
bash_command='echo "Executing Task 2"', # 실행할 Bash 명령어
dag=dag, # 이 태스크가 속한 DAG
)
# 태스크 3 정의 - Bash 명령어 실행
task_3 = BashOperator(
task_id='task_3', # 태스크 ID
bash_command='echo "Executing Task 3"', # 실행할 Bash 명령어
dag=dag, # 이 태스크가 속한 DAG
)
# 태스크 4 정의 - Bash 명령어 실행
task_4 = BashOperator(
task_id='task_4', # 태스크 ID
bash_command='echo "Executing Task 4"', # 실행할 Bash 명령어
dag=dag, # 이 태스크가 속한 DAG
)
# 직렬 의존성 설정 (선형적 실행)
# '>>' 연산자는 '다음에 실행'을 의미함
# task_1이 완료된 후 task_2가 실행되고, task_2가 완료된 후 task_3이 실행됨
task_1 >> task_2 >> task_3
# 위 코드와 동일한 의미를 갖는 다른 표현 방식
# '<<' 연산자는 '이전에 실행'을 의미함
task_3 << task_2 << task_1
# 비트시프트 연산자를 혼합하여 사용하는 예시
# task_1과 task_4가 모두 완료된 후에만 task_2가 실행됨
task_1 >> task_2 << task_4
# 위 표현은 두 개의 개별 의존성을 설정한 것과 같음:
# 1. task_1 >> task_2 (task_1 다음에 task_2 실행)
# 2. task_4 >> task_2 (task_4 다음에 task_2 실행)
✅ set_upstream과 set_downstream 메서드
비트시프트 연산자 외에도, set_upstream과 set_downstream 메서드를 사용하여 의존성을 설정할 수 있습니다.
# set_upstream과 set_downstream 메서드를 사용한 의존성 설정
# 직렬 의존성 설정
# set_upstream: 해당 태스크가 실행되기 전에 인자로 전달된 태스크가 완료되어야 함
task_2.set_upstream(task_1) # task_1이 완료된 후 task_2 실행
task_3.set_upstream(task_2) # task_2가 완료된 후 task_3 실행
# 위 코드는 다음 비트시프트 표현과 동일한 의미를 가짐
# task_1 >> task_2 >> task_3
# set_downstream: 해당 태스크가 완료된 후 인자로 전달된 태스크가 실행됨
task_1.set_downstream(task_2) # task_1이 완료된 후 task_2 실행
task_2.set_downstream(task_3) # task_2가 완료된 후 task_3 실행
# 위 코드 역시 다음 비트시프트 표현과 동일한 의미를 가짐
# task_1 >> task_2 >> task_3
이 두 메서드는 비트시프트 연산자보다 더 명시적이지만, 일반적으로 코드 가독성 측면에서 비트시프트 연산자가 더 많이 사용됩니다.
📌 고급 의존성 패턴
✅ 병렬 실행 (Fan-Out)
다수의 태스크를 병렬로 실행하려면 리스트를 사용하여 의존성을 정의할 수 있습니다.
# 병렬 실행 패턴 (Fan-Out)
# 하나의 태스크가 완료된 후 여러 태스크가 병렬로 실행되는 패턴
# DummyOperator 임포트 - 실제 작업 없이 의존성 표현만을 위한 간단한 연산자
from airflow.operators.dummy import DummyOperator
# 시작 태스크 정의 - 워크플로우의 시작점
start = DummyOperator(task_id='start', dag=dag)
# 종료 태스크 정의 - 워크플로우의 종료점
end = DummyOperator(task_id='end', dag=dag)
# 병렬로 실행할 태스크들을 저장할 빈 리스트 생성
parallel_tasks = []
# 5개의 병렬 태스크 생성하는 반복문
for i in range(1, 6): # 1부터 5까지 반복
task = BashOperator(
task_id=f'parallel_task_{i}', # 동적 태스크 ID 생성 (parallel_task_1, parallel_task_2, ...)
bash_command=f'echo "Executing Parallel Task {i}"', # 동적 명령어 생성
dag=dag, # 이 태스크가 속한 DAG
)
parallel_tasks.append(task) # 생성한 태스크를 리스트에 추가
# 병렬 실행을 위한 의존성 설정
# start 태스크 완료 후 모든 parallel_tasks가 병렬로 실행됨
start >> parallel_tasks
# 모든 parallel_tasks가 완료된 후에 end 태스크 실행
parallel_tasks >> end
# 위 두 줄의 표현은 다음과 같이 풀어서 작성할 수도 있음
# for task in parallel_tasks:
# start >> task # start 다음에 각 병렬 태스크 실행
# task >> end # 각 병렬 태스크 다음에 end 실행
✅ 합류 패턴 (Fan-In)
여러 태스크가 완료된 후 하나의 태스크가 실행되는 패턴입니다.
# 합류 패턴 (Fan-In)
# 여러 태스크가 완료된 후 하나의 태스크가 실행되는 패턴
# 업스트림 태스크들을 저장할 빈 리스트 생성
upstream_tasks = []
# 5개의 업스트림 태스크 생성하는 반복문
for i in range(1, 6): # 1부터 5까지 반복
task = BashOperator(
task_id=f'upstream_task_{i}', # 동적 태스크 ID 생성 (upstream_task_1, upstream_task_2, ...)
bash_command=f'echo "Executing Upstream Task {i}"', # 동적 명령어 생성
dag=dag, # 이 태스크가 속한 DAG
)
upstream_tasks.append(task) # 생성한 태스크를 리스트에 추가
# 모든 업스트림 태스크가 완료된 후 실행할 합류 태스크 정의
join_task = BashOperator(
task_id='join_task', # 태스크 ID
bash_command='echo "All upstream tasks completed"', # 실행할 Bash 명령어
dag=dag, # 이 태스크가 속한 DAG
)
# 합류 패턴 의존성 설정
# 모든 upstream_tasks가 완료된 후에만 join_task 실행
upstream_tasks >> join_task
# 위 표현은 다음과 같이 풀어서 작성할 수도 있음
# for task in upstream_tasks:
# task >> join_task # 각 업스트림 태스크 다음에 합류 태스크 실행
✅ 다이아몬드 패턴 (Diamond Pattern)
병렬 실행과 합류 패턴을 결합한 형태로, 하나의 태스크가 완료된 후 여러 태스크가 병렬로 실행되고, 이들이 모두 완료된 후 다시 하나의 태스크가 실행되는 패턴입니다.
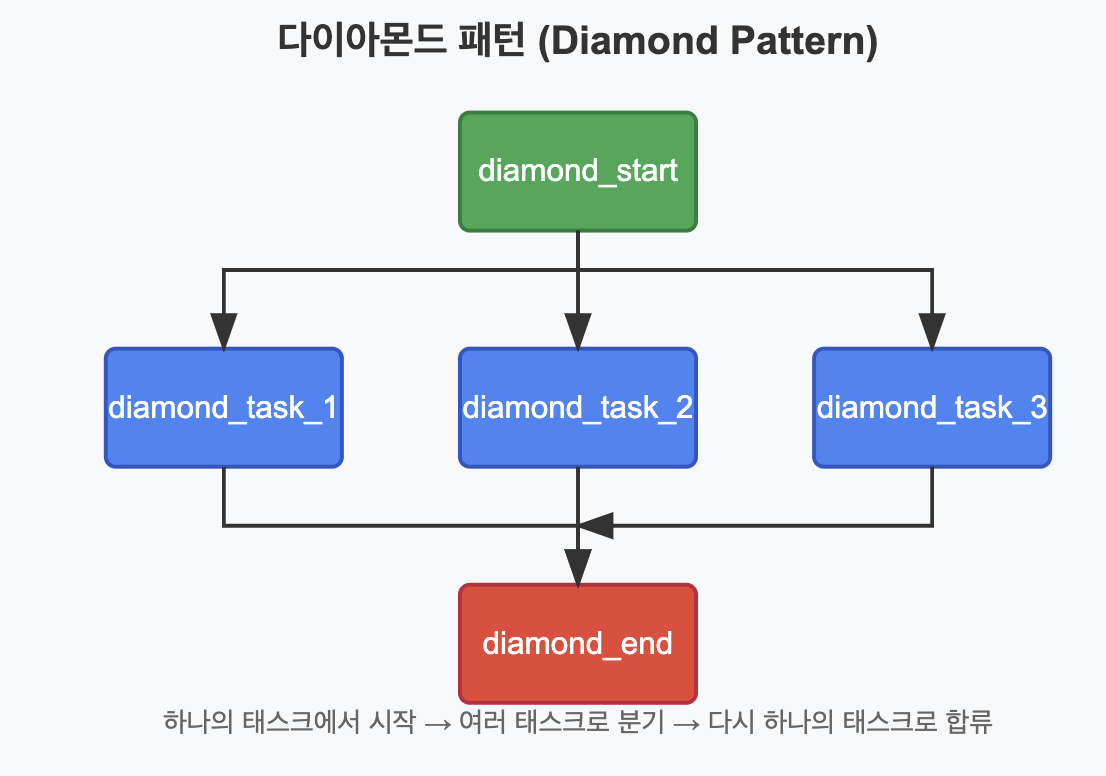
# 다이아몬드 패턴 (Diamond Pattern)
# 하나의 태스크에서 여러 태스크로 나누었다가(Fan-Out) 다시 하나로 합쳐지는(Fan-In) 패턴
# 다이아몬드 패턴의 시작 태스크 정의
diamond_start = DummyOperator(
task_id='diamond_start', # 태스크 ID
dag=dag, # 이 태스크가 속한 DAG
)
# 다이아몬드 패턴의 종료 태스크 정의
diamond_end = DummyOperator(
task_id='diamond_end', # 태스크 ID
dag=dag, # 이 태스크가 속한 DAG
)
# 다이아몬드 중간에 병렬로 실행될 태스크들을 저장할 빈 리스트 생성
diamond_tasks = []
# 3개의 병렬 태스크 생성하는 반복문
for i in range(1, 4): # 1부터 3까지 반복
task = BashOperator(
task_id=f'diamond_task_{i}', # 동적 태스크 ID 생성 (diamond_task_1, diamond_task_2, ...)
bash_command=f'echo "Executing Diamond Task {i}"', # 동적 명령어 생성
dag=dag, # 이 태스크가 속한 DAG
)
diamond_tasks.append(task) # 생성한 태스크를 리스트에 추가
# 다이아몬드 패턴 의존성 설정
# diamond_start 태스크 완료 후 모든 diamond_tasks가 병렬로 실행되고,
# 모든 diamond_tasks가 완료된 후 diamond_end 태스크 실행
diamond_start >> diamond_tasks >> diamond_end
# 위 표현은 다음과 같이 풀어서 작성할 수도 있음
# for task in diamond_tasks:
# diamond_start >> task # 시작 태스크 다음에 각 병렬 태스크 실행
# task >> diamond_end # 각 병렬 태스크 다음에 종료 태스크 실행
✅ 크로스 의존성 (Cross-Dependency)
여러 그룹의 태스크 간에 교차하는 의존성을 설정하는 패턴입니다.
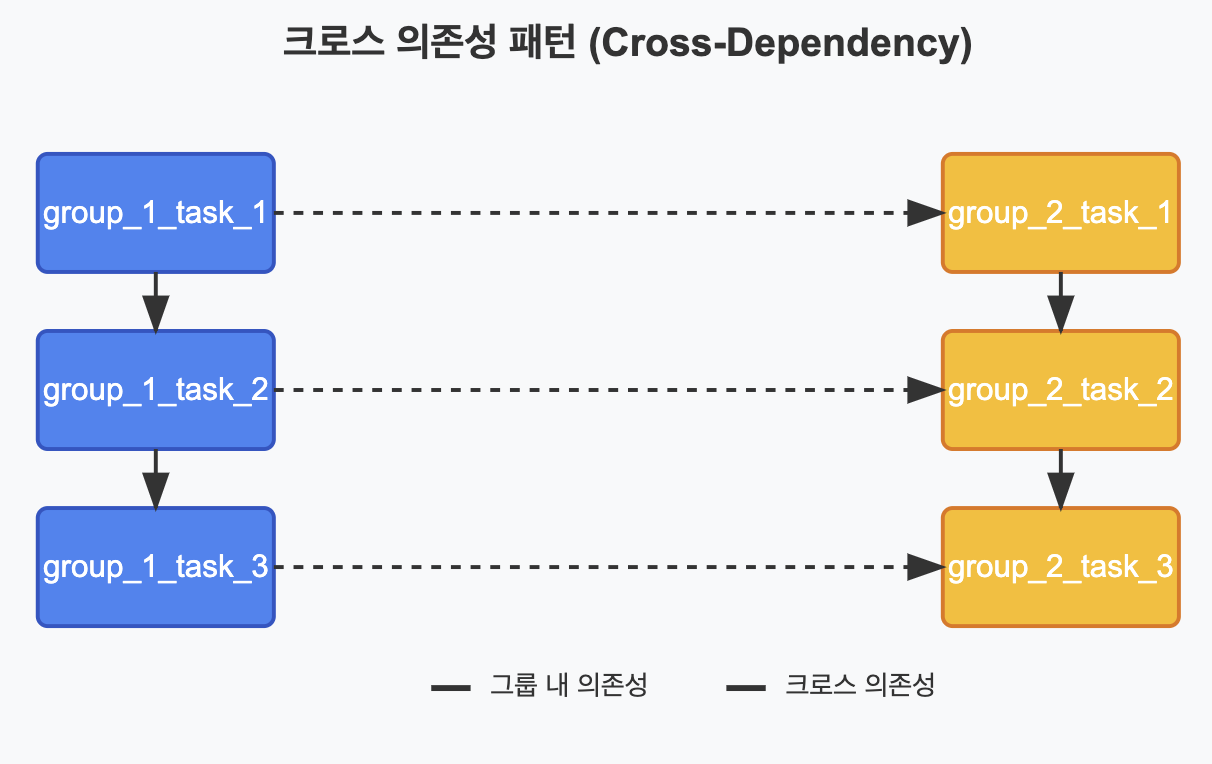
# 크로스 의존성 패턴 (Cross-Dependency)
# 여러 그룹의 태스크 간에 교차하는 의존성을 설정하는 패턴
# 첫 번째 그룹의 태스크들 정의
group_1_tasks = []
for i in range(1, 4): # 1부터 3까지 반복
task = BashOperator(
task_id=f'group_1_task_{i}', # 동적 태스크 ID 생성
bash_command=f'echo "Executing Group 1 Task {i}"', # 동적 명령어 생성
dag=dag, # 이 태스크가 속한 DAG
)
group_1_tasks.append(task) # 생성한 태스크를 리스트에 추가
# 두 번째 그룹의 태스크들 정의
group_2_tasks = []
for i in range(1, 4): # 1부터 3까지 반복
task = BashOperator(
task_id=f'group_2_task_{i}', # 동적 태스크 ID 생성
bash_command=f'echo "Executing Group 2 Task {i}"', # 동적 명령어 생성
dag=dag, # 이 태스크가 속한 DAG
)
group_2_tasks.append(task) # 생성한 태스크를 리스트에 추가
# 크로스 의존성 설정
# 각 그룹의 첫 번째 태스크는 다른 그룹의 이전 태스크에 의존
group_1_tasks[0] >> group_2_tasks[0] # group_1_task_1 -> group_2_task_1
group_1_tasks[1] >> group_2_tasks[1] # group_1_task_2 -> group_2_task_2
group_1_tasks[2] >> group_2_tasks[2] # group_1_task_3 -> group_2_task_3
# 그룹 내 의존성 설정
group_1_tasks[0] >> group_1_tasks[1] >> group_1_tasks[2] # group_1 내부 의존성
group_2_tasks[0] >> group_2_tasks[1] >> group_2_tasks[2] # group_2 내부 의존성
📌 트리거 규칙 (Trigger Rules)
기본적으로 Airflow에서 태스크는 모든 직접적인 업스트림 태스크가 성공적으로 완료되었을 때 실행됩니다. 그러나 태스크의 trigger_rule 파라미터를 설정하여 이 동작을 변경할 수 있습니다.
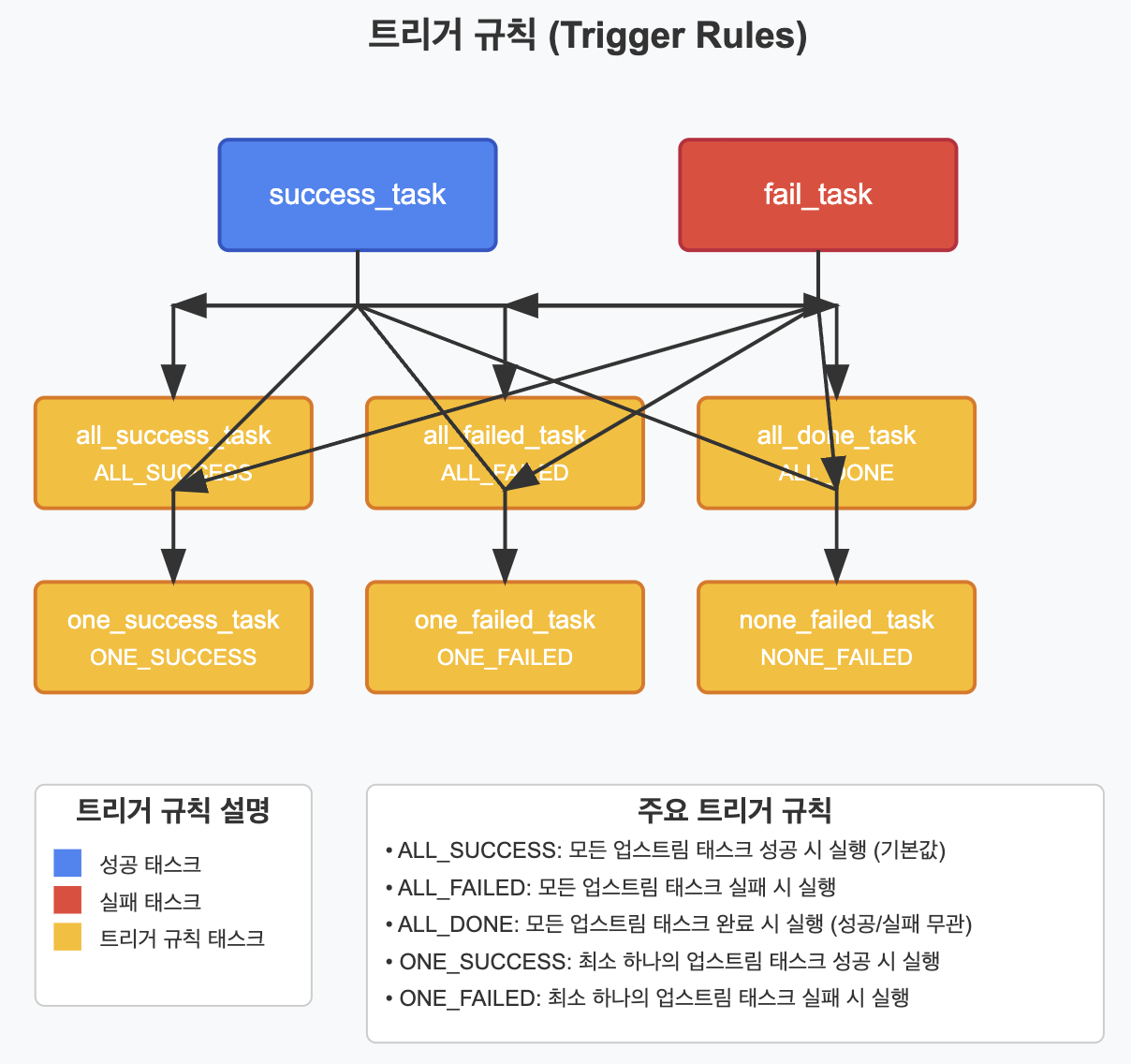
✅ 기본 트리거 규칙
Airflow에서 제공하는 주요 트리거 규칙은 다음과 같습니다:
- all_success (기본값): 모든 직접적인 업스트림 태스크가 성공적으로 완료되었을 때 실행
- all_failed: 모든 직접적인 업스트림 태스크가 실패했을 때 실행
- all_done: 모든 직접적인 업스트림 태스크가 완료되었을 때 실행 (성공 또는 실패)
- one_success: 최소한 하나의 직접적인 업스트림 태스크가 성공적으로 완료되었을 때 실행
- one_failed: 최소한 하나의 직접적인 업스트림 태스크가 실패했을 때 실행
- none_failed: 직접적인 업스트림 태스크 중 실패한 것이 없을 때 실행 (모두 성공 또는 스킵)
- none_skipped: 직접적인 업스트림 태스크 중 스킵된 것이 없을 때 실행
- dummy: 의존성을 무시하고 항상 실행 (주로 테스트용)
다음은 트리거 규칙을 사용한 예시입니다:
# 트리거 규칙 예시
from airflow.operators.bash import BashOperator
from airflow.operators.dummy import DummyOperator
from airflow.utils.trigger_rule import TriggerRule
# 기본 DAG 정의 (위 예제와 동일)
# 시작 태스크
start = DummyOperator(
task_id='start', # 태스크 ID
dag=dag, # 이 태스크가 속한 DAG
)
# 업스트림 태스크들 - 결과가 다양할 수 있는 태스크들
success_task = BashOperator(
task_id='success_task', # 태스크 ID
bash_command='echo "This will succeed" && exit 0', # 항상 성공하는 명령어
dag=dag, # 이 태스크가 속한 DAG
)
fail_task = BashOperator(
task_id='fail_task', # 태스크 ID
bash_command='echo "This will fail" && exit 1', # 항상 실패하는 명령어
dag=dag, # 이 태스크가 속한 DAG
)
# 의존성 설정
start >> [success_task, fail_task] # 시작 태스크 다음에 성공/실패 태스크 병렬 실행
# 다양한 트리거 규칙을 가진 태스크들 정의
# 1. all_success (기본값) - 모든 업스트림 태스크가 성공해야 실행
all_success_task = DummyOperator(
task_id='all_success_task', # 태스크 ID
trigger_rule=TriggerRule.ALL_SUCCESS, # 트리거 규칙 설정
dag=dag, # 이 태스크가 속한 DAG
)
# 2. all_failed - 모든 업스트림 태스크가 실패해야 실행
all_failed_task = DummyOperator(
task_id='all_failed_task', # 태스크 ID
trigger_rule=TriggerRule.ALL_FAILED, # 트리거 규칙 설정
dag=dag, # 이 태스크가 속한 DAG
)
# 3. all_done - 모든 업스트림 태스크가 완료되면 실행 (성공/실패 무관)
all_done_task = DummyOperator(
task_id='all_done_task', # 태스크 ID
trigger_rule=TriggerRule.ALL_DONE, # 트리거 규칙 설정
dag=dag, # 이 태스크가 속한 DAG
)
# 4. one_success - 최소 하나의 업스트림 태스크가 성공하면 실행
one_success_task = DummyOperator(
task_id='one_success_task', # 태스크 ID
trigger_rule=TriggerRule.ONE_SUCCESS, # 트리거 규칙 설정
dag=dag, # 이 태스크가 속한 DAG
)
# 5. one_failed - 최소 하나의 업스트림 태스크가 실패하면 실행
one_failed_task = DummyOperator(
task_id='one_failed_task', # 태스크 ID
trigger_rule=TriggerRule.ONE_FAILED, # 트리거 규칙 설정
dag=dag, # 이 태스크가 속한 DAG
)
# 트리거 규칙 기반 태스크들의 의존성 설정
[success_task, fail_task] >> all_success_task # 모든 업스트림이 성공해야 하므로 실행되지 않음
[success_task, fail_task] >> all_failed_task # 모든 업스트림이 실패해야 하므로 실행되지 않음
[success_task, fail_task] >> all_done_task # 모든 업스트림이 완료되면 실행됨
[success_task, fail_task] >> one_success_task # 하나 이상이 성공하므로 실행됨
[success_task, fail_task] >> one_failed_task # 하나 이상이 실패하므로 실행됨
✅ 트리거 규칙 활용 사례
트리거 규칙은 복잡한 워크플로우 구현에 매우 유용합니다. 몇 가지 실제 활용 사례를 살펴보겠습니다:
- 오류 처리 및 알림
# 오류 처리 및 알림 예시
# 태스크가 실패하더라도 알림을 보내고 DAG를 계속 진행하는 패턴
from airflow.operators.email import EmailOperator
from airflow.utils.trigger_rule import TriggerRule
# 태스크 정의
task_a = BashOperator(
task_id='task_a', # 태스크 ID
bash_command='echo "Task A" && exit 0', # 성공하는 명령어
dag=dag, # 이 태스크가 속한 DAG
)
task_b = BashOperator(
task_id='task_b', # 태스크 ID
bash_command='echo "Task B will fail" && exit 1', # 실패하는 명령어
dag=dag, # 이 태스크가 속한 DAG
)
# 알림 태스크 - 업스트림 태스크 중 하나라도 실패하면 이메일 발송
send_notification = EmailOperator(
task_id='send_notification', # 태스크 ID
to='admin@example.com', # 수신자 이메일
subject='Airflow Task Failed', # 이메일 제목
html_content='One or more tasks have failed. Please check the Airflow UI.', # 이메일 내용
trigger_rule=TriggerRule.ONE_FAILED, # 하나라도 실패하면 트리거
dag=dag, # 이 태스크가 속한 DAG
)
# 계속 진행하는 태스크 - 모든 작업이 완료되면 실행 (성공/실패 무관)
continue_task = DummyOperator(
task_id='continue_processing', # 태스크 ID
trigger_rule=TriggerRule.ALL_DONE, # 모든 업스트림 태스크가 완료되면 실행
dag=dag, # 이 태스크가 속한 DAG
)
# 의존성 설정
[task_a, task_b] >> send_notification >> continue_task
- 조건부 실행 경로
# 조건부 실행 경로 예시
# 여러 검사 태스크의 결과에 따라 다른 경로로 진행하는 패턴
from airflow.operators.python import PythonOperator, BranchPythonOperator
from airflow.utils.trigger_rule import TriggerRule
# 데이터 검사 함수들 정의
def check_data_quality():
# 실제로는 데이터 품질을 검사하는 로직이 들어감
import random
quality_score = random.randint(0, 100)
print(f"Data quality score: {quality_score}")
if quality_score < 50:
return False # 품질이 낮음
return True # 품질이 높음
def check_data_volume():
# 실제로는 데이터 양을 검사하는 로직이 들어감
import random
volume = random.randint(0, 1000)
print(f"Data volume: {volume}")
if volume < 500:
return False # 데이터 양이 적음
return True # 데이터 양이 충분함
# 검사 태스크들 정의
quality_check = PythonOperator(
task_id='check_data_quality', # 태스크 ID
python_callable=check_data_quality, # 실행할 함수
dag=dag, # 이 태스크가 속한 DAG
)
volume_check = PythonOperator(
task_id='check_data_volume', # 태스크 ID
python_callable=check_data_volume, # 실행할 함수
dag=dag, # 이 태스크가 속한 DAG
)
# 모든 검사 통과 시 실행되는 태스크
all_checks_passed = DummyOperator(
task_id='all_checks_passed', # 태스크 ID
trigger_rule=TriggerRule.ALL_SUCCESS, # 모든 검사가 성공해야 실행
dag=dag, # 이 태스크가 속한 DAG
)
# 하나 이상의 검사 실패 시 실행되는 태스크
some_checks_failed = DummyOperator(
task_id='some_checks_failed', # 태스크 ID
trigger_rule=TriggerRule.ONE_FAILED, # 하나라도 실패하면 실행
dag=dag, # 이 태스크가 속한 DAG
)
# 정상 처리 태스크 (데이터가 좋을 때)
process_data = BashOperator(
task_id='process_data', # 태스크 ID
bash_command='echo "Processing data..."', # 실행할 명령어
dag=dag, # 이 태스크가 속한 DAG
)
# 데이터 정제 태스크 (데이터가 좋지 않을 때)
clean_data = BashOperator(
task_id='clean_data', # 태스크 ID
bash_command='echo "Cleaning data..."', # 실행할 명령어
dag=dag, # 이 태스크가 속한 DAG
)
# 최종 태스크 - 모든 경로가 합류
final_task = DummyOperator(
task_id='final_task', # 태스크 ID
trigger_rule=TriggerRule.ALL_DONE, # 모든 업스트림 태스크가 완료되면 실행 (성공/실패 무관)
dag=dag, # 이 태스크가 속한 DAG
)
# 의존성 설정
# 두 가지 검사를 병렬로 실행
[quality_check, volume_check] >> all_checks_passed >> process_data # 모든 검사 통과 시 경로
[quality_check, volume_check] >> some_checks_failed >> clean_data # 일부 검사 실패 시 경로
[process_data, clean_data] >> final_task # 두 경로가 최종 태스크에서 합류
📌 조건부 태스크 실행 (BranchPythonOperator)
복잡한 워크플로우에서는 조건에 따라 다른 태스크를 실행해야 하는 경우가 많습니다. 이를 위해 Airflow는 BranchPythonOperator를 제공합니다.
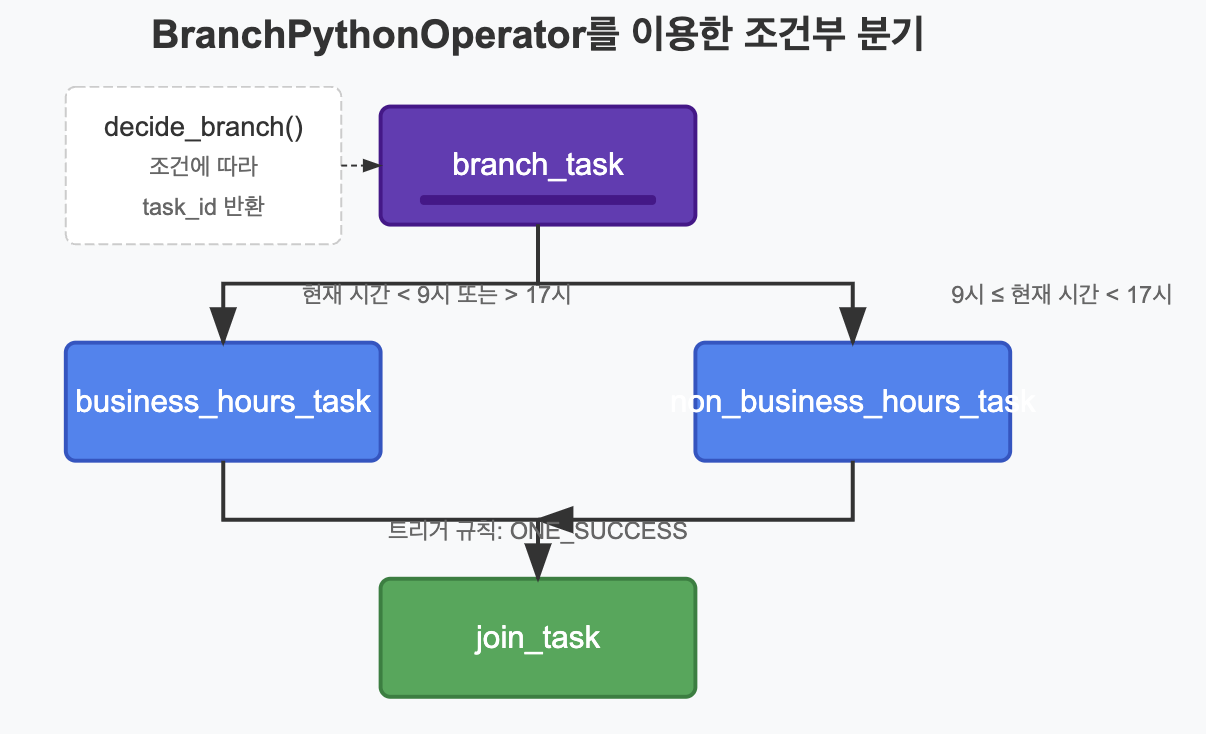
✅ 기본 분기 패턴
BranchPythonOperator는 정의된 Python 함수의 반환값에 따라 다음에 실행할 태스크를 결정합니다.
# BranchPythonOperator를 사용한 조건부 분기 예시
from airflow.operators.python import BranchPythonOperator
from airflow.operators.dummy import DummyOperator
from datetime import datetime
# 분기 결정 함수 정의
def decide_branch(**context):
"""
현재 시간에 따라 다른 태스크로 분기하는 함수
Returns:
str: 다음에 실행할 태스크의 task_id를 반환
"""
current_hour = datetime.now().hour
# 업무 시간(9-17시) 여부에 따라 다른 태스크 ID 반환
if 9 <= current_hour < 17:
return 'business_hours_task' # 업무 시간 중일 때 실행할 태스크
else:
return 'non_business_hours_task' # 업무 시간 외일 때 실행할 태스크
# 분기 태스크 정의
branch_task = BranchPythonOperator(
task_id='branch_task', # 태스크 ID
python_callable=decide_branch, # 분기를 결정할 함수
dag=dag, # 이 태스크가 속한 DAG
)
# 분기 후 태스크들 정의
business_hours_task = DummyOperator(
task_id='business_hours_task', # 태스크 ID - 함수의 반환값과 일치해야 함
dag=dag, # 이 태스크가 속한 DAG
)
non_business_hours_task = DummyOperator(
task_id='non_business_hours_task', # 태스크 ID - 함수의 반환값과 일치해야 함
dag=dag, # 이 태스크가 속한 DAG
)
# 두 경로가 합류하는 태스크
join_task = DummyOperator(
task_id='join_task', # 태스크 ID
trigger_rule=TriggerRule.ONE_SUCCESS, # 하나라도 성공하면 실행 (둘 중 하나만 실행되므로)
dag=dag, # 이 태스크가 속한 DAG
)
# 의존성 설정
branch_task >> [business_hours_task, non_business_hours_task] >> join_task
✅ 다중 경로 분기
BranchPythonOperator는 하나의 태스크 ID뿐 아니라 여러 태스크 ID의 리스트도 반환할 수 있어 다중 경로로 분기할 수 있습니다.
# 다중 경로 분기 예시
def decide_multiple_branches(**context):
"""
조건에 따라 여러 태스크로 분기하는 함수
Returns:
list: 다음에 실행할 태스크들의 task_id 리스트를 반환
"""
# 실제로는 더 복잡한 조건이 있을 수 있음
execution_date = context['execution_date']
weekday = execution_date.weekday() # 0=월요일, 6=일요일
# 요일에 따라 다른 태스크 조합 반환
if weekday < 5: # 평일
if weekday == 0: # 월요일
return ['monday_report', 'weekday_task'] # 두 태스크 모두 실행
else:
return 'weekday_task' # 하나의 태스크만 실행
else: # 주말
return ['weekend_task', 'low_priority_task'] # 두 태스크 모두 실행
# 다중 분기 태스크 정의
multi_branch_task = BranchPythonOperator(
task_id='multi_branch_task', # 태스크 ID
python_callable=decide_multiple_branches, # 분기를 결정할 함수
provide_context=True, # 컨텍스트 제공 활성화
dag=dag, # 이 태스크가 속한 DAG
)
# 다양한 경로의 태스크들 정의
monday_report = DummyOperator(
task_id='monday_report', # 태스크 ID
dag=dag, # 이 태스크가 속한 DAG
)
weekday_task = DummyOperator(
task_id='weekday_task', # 태스크 ID
dag=dag, # 이 태스크가 속한 DAG
)
weekend_task = DummyOperator(
task_id='weekend_task', # 태스크 ID
dag=dag, # 이 태스크가 속한 DAG
)
low_priority_task = DummyOperator(
task_id='low_priority_task', # 태스크 ID
dag=dag, # 이 태스크가 속한 DAG
)
# 모든 경로가 합류하는 태스크
multi_join_task = DummyOperator(
task_id='multi_join_task', # 태스크 ID
trigger_rule=TriggerRule.ONE_SUCCESS, # 하나라도 성공하면 실행
dag=dag, # 이 태스크가 속한 DAG
)
# 의존성 설정
multi_branch_task >> [monday_report, weekday_task, weekend_task, low_priority_task] >> multi_join_task
✅ 브랜치와 트리거 규칙 조합
브랜치와 트리거 규칙을 조합하면 더 복잡한 조건부 워크플로우를 구현할 수 있습니다.
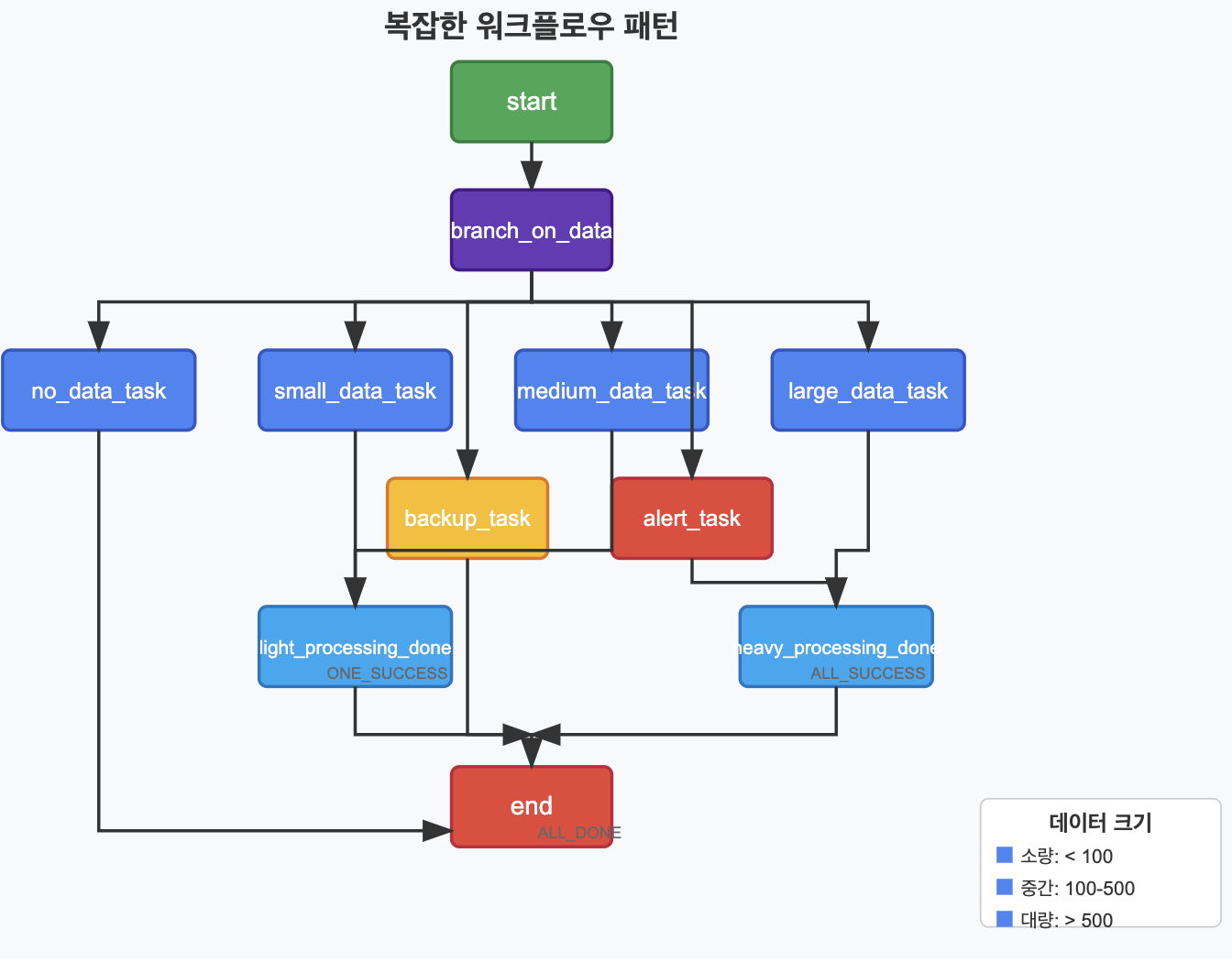
# 브랜치와 트리거 규칙을 조합한 예시
# 복잡한 데이터 처리 워크플로우를 위한 DAG 생성
with DAG(
'complex_workflow',
default_args=default_args,
description='Complex workflow with branches and trigger rules',
schedule_interval=timedelta(days=1),
) as complex_dag:
# 시작 태스크
start = DummyOperator(
task_id='start', # 태스크 ID
)
# 데이터 로드 함수 정의
def load_data(**context):
"""데이터를 로드하고 크기에 따라 처리 경로를 결정하는 함수"""
import random
# 실제로는 데이터베이스나 파일에서 데이터를 로드할 것
data_size = random.randint(0, 1000)
print(f"Data size: {data_size}")
# 데이터 크기에 따라 다른 처리 경로 결정
if data_size == 0:
return 'no_data_task'
elif data_size < 100:
return 'small_data_task'
elif data_size < 500:
return ['medium_data_task', 'backup_task']
else:
return ['large_data_task', 'backup_task', 'alert_task']
# 데이터 크기 기반 분기 태스크
branch_on_data_size = BranchPythonOperator(
task_id='branch_on_data_size', # 태스크 ID
python_callable=load_data, # 분기를 결정할 함수
provide_context=True, # 컨텍스트 제공 활성화
)
# 데이터 없음 처리 태스크
no_data_task = BashOperator(
task_id='no_data_task', # 태스크 ID
bash_command='echo "No data to process"', # 실행할 명령어
)
# 소량 데이터 처리 태스크
small_data_task = BashOperator(
task_id='small_data_task', # 태스크 ID
bash_command='echo "Processing small data set"', # 실행할 명령어
)
# 중간 크기 데이터 처리 태스크
medium_data_task = BashOperator(
task_id='medium_data_task', # 태스크 ID
bash_command='echo "Processing medium data set"', # 실행할 명령어
)
# 대량 데이터 처리 태스크
large_data_task = BashOperator(
task_id='large_data_task', # 태스크 ID
bash_command='echo "Processing large data set"', # 실행할 명령어
)
# 백업 태스크
backup_task = BashOperator(
task_id='backup_task', # 태스크 ID
bash_command='echo "Backing up data"', # 실행할 명령어
)
# 알림 태스크
alert_task = BashOperator(
task_id='alert_task', # 태스크 ID
bash_command='echo "Sending large data alert"', # 실행할 명령어
)
# 소량/중간 데이터 처리 후 실행되는 태스크
light_processing_done = DummyOperator(
task_id='light_processing_done', # 태스크 ID
trigger_rule=TriggerRule.ONE_SUCCESS, # 하나라도 성공하면 실행
)
# 대량 데이터 처리 후 실행되는 태스크
heavy_processing_done = DummyOperator(
task_id='heavy_processing_done', # 태스크 ID
trigger_rule=TriggerRule.ALL_SUCCESS, # 모든 업스트림이 성공해야 실행
)
# 모든 경로가 합류하는 최종 태스크
end = DummyOperator(
task_id='end', # 태스크 ID
trigger_rule=TriggerRule.ALL_DONE, # 모든 업스트림이 완료되면 실행 (성공/실패 무관)
)
# 의존성 설정
start >> branch_on_data_size
# 각 데이터 크기에 따른 경로 설정
branch_on_data_size >> no_data_task >> end
branch_on_data_size >> small_data_task >> light_processing_done
branch_on_data_size >> medium_data_task >> light_processing_done
branch_on_data_size >> large_data_task >> heavy_processing_done
branch_on_data_size >> backup_task
branch_on_data_size >> alert_task >> heavy_processing_done
# 모든 처리가 끝난 후 최종 태스크로 합류
[light_processing_done, heavy_processing_done, backup_task] >> end
📌 실무 응용 패턴
✅ 오류 처리 및 재시도 메커니즘
태스크 간 의존성을 설정할 때, 오류 처리와 재시도 메커니즘은 중요한 고려사항입니다.
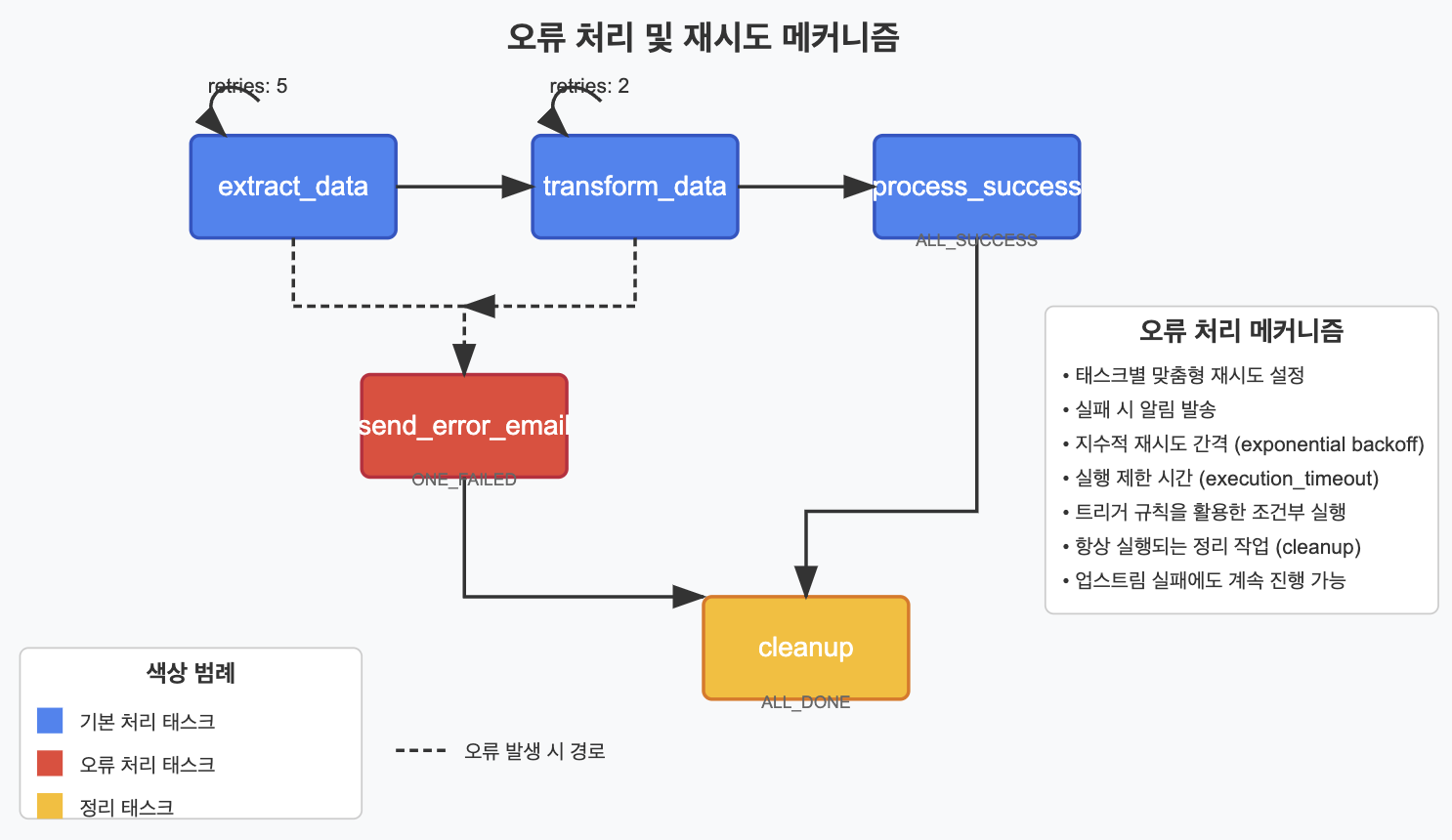
# 오류 처리 및 재시도 메커니즘을 포함한 예시
from airflow.operators.python import PythonOperator
from airflow.operators.email import EmailOperator
from airflow.operators.bash import BashOperator
from airflow.utils.trigger_rule import TriggerRule
from datetime import datetime, timedelta
# DAG 정의
with DAG(
'error_handling_pattern',
default_args={
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2023, 1, 1),
'email': ['alert@example.com'],
'email_on_failure': False, # DAG 레벨에서는 비활성화하고 별도로 처리
'email_on_retry': False,
'retries': 3, # 기본적으로 3번 재시도
'retry_delay': timedelta(minutes=5), # 5분 간격으로 재시도
'retry_exponential_backoff': True, # 재시도 간격을 지수적으로 증가시킴
'max_retry_delay': timedelta(hours=1), # 최대 재시도 간격은 1시간
},
schedule_interval='@daily',
) as dag:
# 데이터 추출 함수 - 간헐적으로 실패할 수 있는 작업
def extract_data(**context):
"""외부 시스템에서 데이터를 추출하는 함수"""
import random
# 20% 확률로 실패하는 시뮬레이션
if random.random() < 0.2:
raise Exception("Data extraction failed: API timeout")
return {"data": "sample extracted data"}
# 데이터 변환 함수 - 일관된 작업
def transform_data(**context):
"""추출된 데이터를 변환하는 함수"""
ti = context['ti']
extracted_data = ti.xcom_pull(task_ids='extract_data')
if not extracted_data:
raise Exception("No data to transform")
return {"transformed_data": extracted_data["data"].upper()}
# 태스크 정의 - 추출 단계 (재시도 설정 추가)
extract_task = PythonOperator(
task_id='extract_data', # 태스크 ID
python_callable=extract_data, # 실행할 함수
retries=5, # 데이터 추출은 더 많은 재시도 설정
retry_delay=timedelta(minutes=2), # 더 짧은 재시도 간격
execution_timeout=timedelta(minutes=30), # 실행 시간 제한
provide_context=True, # 컨텍스트 제공 활성화
)
# 태스크 정의 - 변환 단계
transform_task = PythonOperator(
task_id='transform_data', # 태스크 ID
python_callable=transform_data, # 실행할 함수
retries=2, # 변환은 적은 재시도 설정
provide_context=True, # 컨텍스트 제공 활성화
)
# 태스크 정의 - 성공 시 처리
success_task = BashOperator(
task_id='process_success', # 태스크 ID
bash_command='echo "Processing completed successfully at $(date)"', # 실행할 명령어
trigger_rule=TriggerRule.ALL_SUCCESS, # 모든 업스트림 태스크가 성공해야 실행
)
# 태스크 정의 - 오류 알림
error_notification = EmailOperator(
task_id='send_error_email', # 태스크 ID
to='data-team@example.com', # 알림 수신자
subject='Airflow Data Pipeline Failed', # 이메일 제목
html_content='''
<h3>Data Pipeline Error</h3>
<p>The data processing pipeline has failed after all retries.</p>
<p>Please check the Airflow logs for more details.</p>
<p>Time: {{ execution_date }}</p>
''', # 이메일 내용 (템플릿 사용)
trigger_rule=TriggerRule.ONE_FAILED, # 하나라도 실패하면 실행
)
# 태스크 정의 - 항상 실행되는 정리 작업
cleanup_task = BashOperator(
task_id='cleanup', # 태스크 ID
bash_command='echo "Performing cleanup at $(date)" && rm -f /tmp/airflow_temp_*', # 실행할 명령어
trigger_rule=TriggerRule.ALL_DONE, # 모든 업스트림 태스크가 완료되면 실행 (성공/실패 무관)
)
# 의존성 설정
extract_task >> transform_task >> success_task
# 오류 알림 및 정리 작업 설정
[extract_task, transform_task] >> error_notification >> cleanup_task
success_task >> cleanup_task
✅ 센서 태스크와 의존성
센서(Sensor)는 외부 조건이 충족될 때까지 대기하는 특수한 유형의 태스크입니다. 센서와 의존성을 조합하면 외부 조건에 따른 워크플로우를 구현할 수 있습니다.
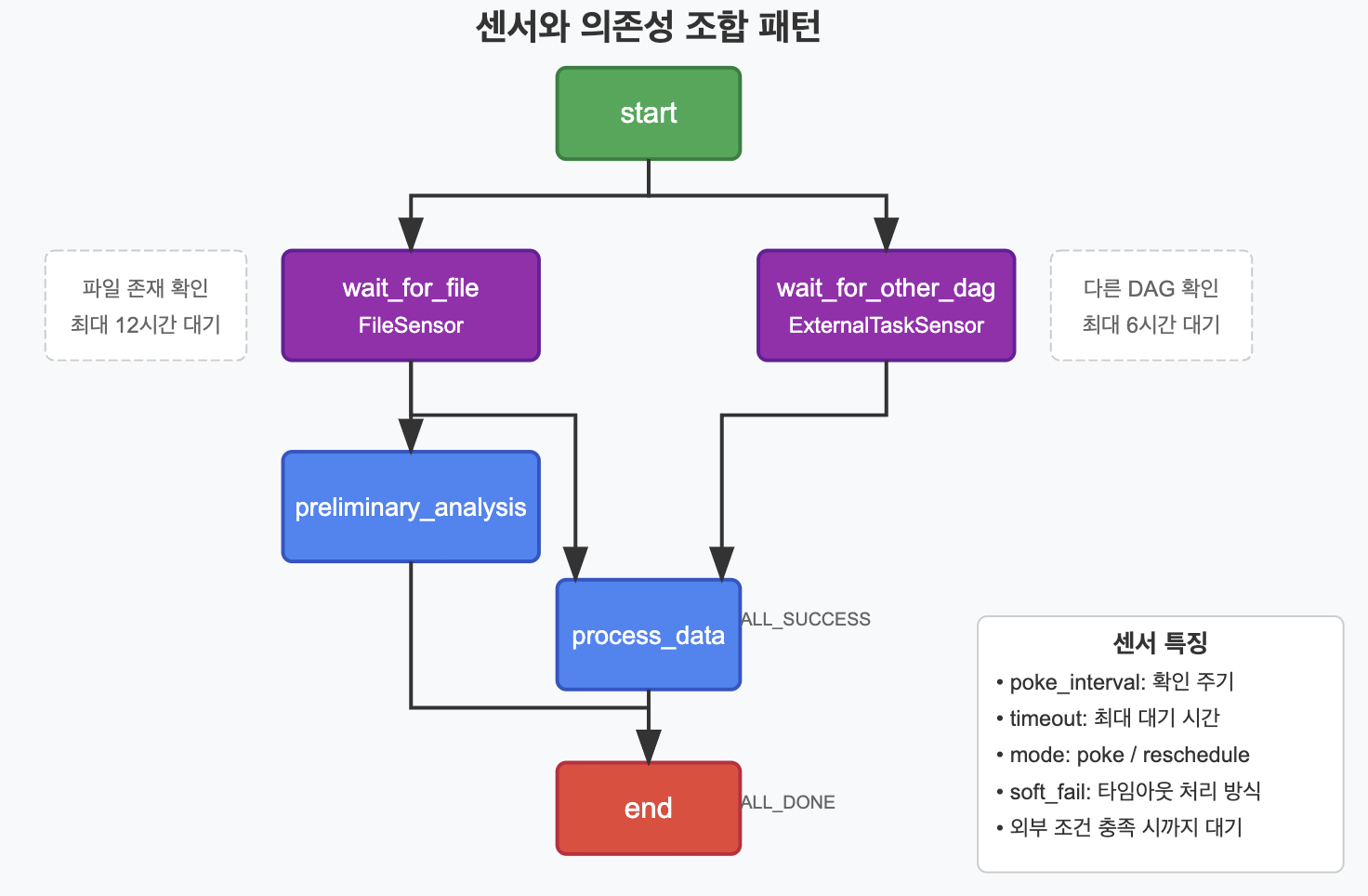
# 센서와 의존성을 조합한 예시
from airflow.sensors.filesystem import FileSensor
from airflow.sensors.external_task import ExternalTaskSensor
from airflow.operators.bash import BashOperator
from airflow.operators.dummy import DummyOperator
from datetime import datetime, timedelta
# DAG 정의
with DAG(
'sensor_dependency_pattern',
default_args={
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2023, 1, 1),
'retries': 0, # 센서는 기본적으로 재시도하지 않음
},
schedule_interval='@daily',
) as dag:
# 시작 태스크
start = DummyOperator(
task_id='start', # 태스크 ID
)
# 파일 센서 - 파일이 존재할 때까지 대기
wait_for_file = FileSensor(
task_id='wait_for_file', # 태스크 ID
filepath='/path/to/input/file.csv', # 감시할 파일 경로
fs_conn_id='fs_default', # 파일시스템 연결 ID
poke_interval=60, # 60초 간격으로 확인
timeout=60 * 60 * 12, # 최대 12시간 대기
mode='reschedule', # 다른 태스크가 실행될 수 있도록 슬롯 반환
soft_fail=False, # 타임아웃 시 실패로 처리
)
# 다른 DAG의 태스크 센서 - 다른 DAG의 특정 태스크가 완료될 때까지 대기
wait_for_other_dag = ExternalTaskSensor(
task_id='wait_for_other_dag', # 태스크 ID
external_dag_id='upstream_dag', # 대기할 외부 DAG ID
external_task_id='final_task', # 대기할 외부 태스크 ID
allowed_states=['success'], # 허용되는 상태 (성공만)
execution_delta=timedelta(hours=1), # 1시간 전 실행된 DAG 확인
mode='reschedule', # 다른 태스크가 실행될 수 있도록 슬롯 반환
timeout=60 * 60 * 6, # 최대 6시간 대기
poke_interval=60 * 5, # 5분 간격으로 확인
)
# 두 센서 모두 충족되면 실행할 태스크
process_data = BashOperator(
task_id='process_data', # 태스크 ID
bash_command='echo "Processing data from file" && cat /path/to/input/file.csv', # 실행할 명령어
trigger_rule=TriggerRule.ALL_SUCCESS, # 모든 업스트림 태스크가 성공해야 실행
)
# 파일만 있으면 실행할 수 있는 태스크
preliminary_analysis = BashOperator(
task_id='preliminary_analysis', # 태스크 ID
bash_command='echo "Running preliminary analysis on file"', # 실행할 명령어
)
# 모든 처리가 끝난 후 실행할 종료 태스크
end = DummyOperator(
task_id='end', # 태스크 ID
trigger_rule=TriggerRule.ALL_DONE, # 모든 업스트림 태스크가 완료되면 실행
)
# 의존성 설정
start >> [wait_for_file, wait_for_other_dag]
# 파일 센서가 성공하면 예비 분석 실행
wait_for_file >> preliminary_analysis
# 두 센서 모두 성공해야 주요 데이터 처리 실행
[wait_for_file, wait_for_other_dag] >> process_data
# 모든 처리가 끝난 후 종료 태스크 실행
[preliminary_analysis, process_data] >> end
Summary
- 기본 의존성 설정 방법으로는 비트시프트 연산자(>>, <<)와 set_upstream, set_downstream 메서드가 있으며, 이를 통해 태스크 간의 실행 순서를 정의할 수 있습니다.
- 고급 의존성 패턴에는 병렬 실행(Fan-Out), 합류 패턴(Fan-In), 다이아몬드 패턴, 크로스 의존성 등이 있으며, 이를 통해 복잡한 워크플로우를 구현할 수 있습니다.
- **트리거 규칙(Trigger Rules)**을 활용하면 기본적인 "모든 업스트림 태스크 성공 시 실행" 동작을 변경하여 특정 조건에서만 태스크가 실행되도록 설정할 수 있습니다.
- BranchPythonOperator를 사용하면 조건에 따라 다른 태스크 경로로 분기할 수 있어 동적인 워크플로우를 구현할 수 있습니다.
- 오류 처리 및 재시도 메커니즘을 구현하여 안정적인 워크플로우를 설계할 수 있으며, 센서 태스크와 의존성을 조합하여 외부 조건에 따른 워크플로우를 구현할 수 있습니다.
- 실무에서는 이러한 패턴들을 조합하여 비즈니스 요구사항에 맞는 복잡한 워크플로우를 구현할 수 있습니다.