EP02 [Part 1: Kubernetes 모니터링 기초 #2] Prometheus의 아키텍처와 작동 원리
이번 글에서는 Prometheus의 내부 아키텍처와 작동 원리를 더 깊이 살펴보겠습니다.
📌 Prometheus 아키텍처 개요
Prometheus는 단순한 도구가 아닌 여러 컴포넌트가 유기적으로 작동하는 완전한 모니터링 시스템입니다.

✅ 핵심 컴포넌트
- Retrieval (수집기): 타겟에서 메트릭을 가져오는 컴포넌트
- TSDB (시계열 데이터베이스): 메트릭을 저장하는 특수 목적 데이터베이스
- HTTP Server: API 및 웹 UI 제공
- PromQL Engine: 쿼리 처리 엔진
- Service Discovery: 모니터링 대상 자동 발견
- Alert Manager: 알림 관리 및 라우팅
▶️ 아키텍처 특징: Prometheus의 설계는 신뢰성과 확장성을 최우선으로 합니다. 각 컴포넌트가 독립적으로 작동하여 부분 실패에도 전체 시스템이 계속 작동합니다.
📌 데이터 수집 메커니즘: Pull 모델
Prometheus의 가장 큰 특징 중 하나는 'Pull(풀)' 방식의 데이터 수집 모델입니다.
✅ Pull 모델의 작동 방식
- Prometheus 서버는 설정된 간격(기본 15초)마다 타겟 엔드포인트로 HTTP 요청
- 타겟은 /metrics 엔드포인트를 통해 현재 메트릭 제공
- Prometheus는 받은 데이터를 파싱하여 저장
# prometheus.yml 설정 예시
scrape_configs:
- job_name: 'kubernetes-nodes' # 작업 이름 (메트릭에 job 레이블로 추가됨)
scrape_interval: 15s # 전체 기본값 재정의 (15초마다 메트릭 수집)
kubernetes_sd_configs: # 쿠버네티스 서비스 디스커버리 설정
- role: node # 노드 역할 지정 (클러스터의 모든 노드를 스크래핑 대상으로 발견)
relabel_configs: # 레이블 재작성 규칙
- source_labels: [__meta_kubernetes_node_name] # 소스 레이블 (쿠버네티스 노드 이름)
regex: (.+) # 모든 문자열과 일치하는 정규식
target_label: node # 대상 레이블 (node로 저장)
replacement: $1 # 캡처된 값 사용 (노드 이름 그대로 유지)
✅ Pull 모델의 장점
- 간편한 건강 확인: 메트릭을 가져올 수 없다면 타겟에 문제가 있다는 신호
- 중앙 집중식 제어: 수집 빈도, 타임아웃 등을 서버에서 관리
- 보안 강화: 모니터링 대상에서 외부로 연결 필요 없음
- 디버깅 용이성: /metrics 엔드포인트를 브라우저로 직접 확인 가능
✅ Pull 모델의 단점
- 방화벽 제약: Prometheus가 모든 타겟에 접근 가능해야 함
- 단기 배치 작업: 실행 중에만 존재하는 작업은 특별 처리 필요
- 높은 카디널리티: 수많은 짧은 수명의 타겟 관리 복잡성
▶️ 실무 팁: 방화벽이 엄격한 환경에서는 Prometheus 서버를 각 네트워크 구역에 배치하고, 상위 Prometheus가 이들을 통합하는 계층적 구조를 고려하세요.
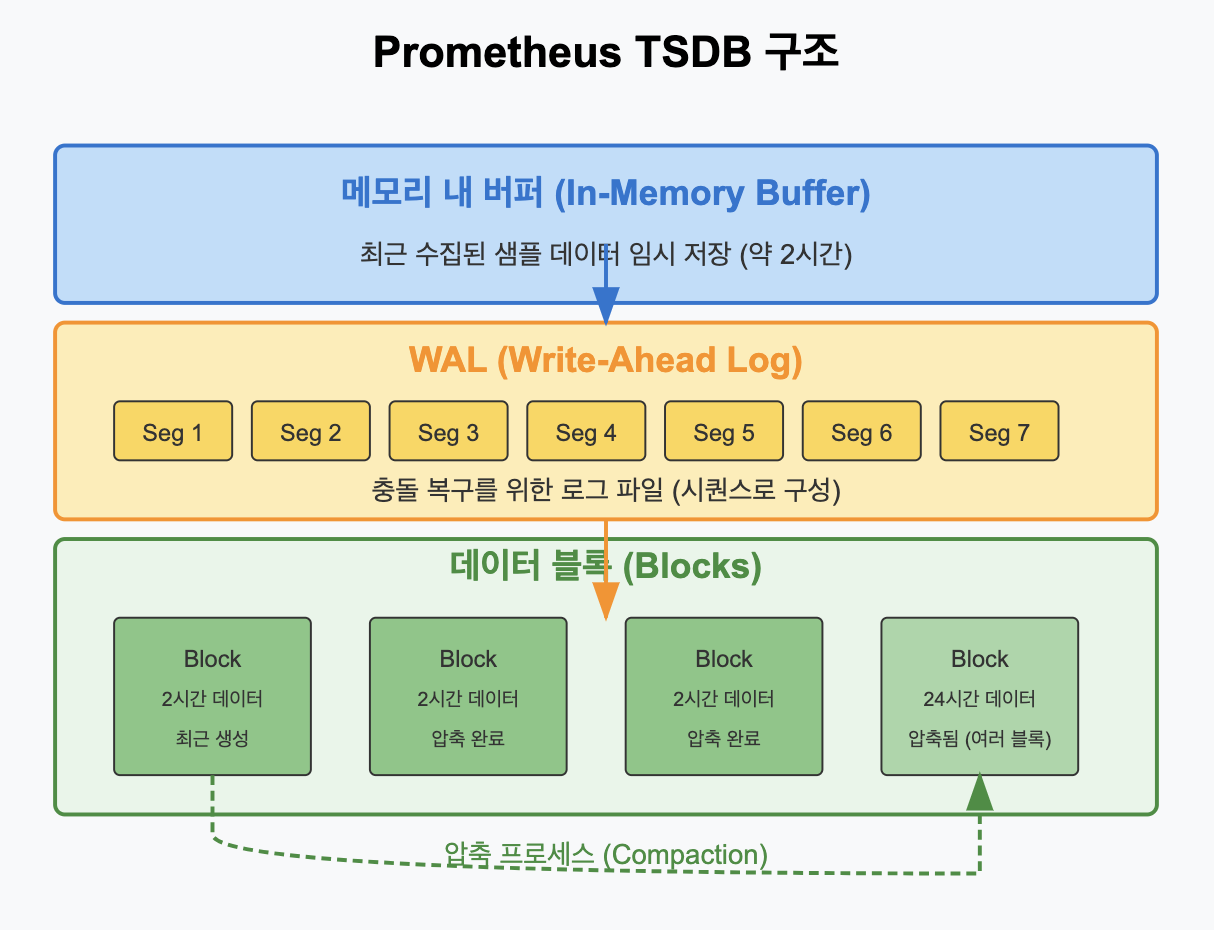
📌 시계열 데이터베이스 (TSDB)
Prometheus는 자체 개발한 시계열 데이터베이스를 사용하여 메트릭 데이터를 효율적으로 저장합니다.
✅ TSDB의 주요 특징
- 시계열 중심: 시간에 따른 데이터 포인트 최적화
- 압축 알고리즘: 데이터를 효율적으로 압축하여 저장
- 로컬 디스크 저장: 단순하지만 효과적인 접근법
- 블록 기반 구조: 2시간 단위의 블록으로 데이터 관리
✅ 데이터 저장 구조
- 메모리 내 버퍼: 최근 데이터는 메모리에 먼저 저장
- WAL(Write-Ahead Log): 충돌 복구를 위한 로그
- 블록: 2시간 데이터 세트로 디스크에 압축 저장
- 압축: 주기적으로 기존 블록들을 더 큰 블록으로 압축
✅ 보존 정책
기본적으로 Prometheus는 15일간 데이터를 보존하며, 이는 설정으로 조정 가능합니다:
# prometheus.yml 설정 예시 (데이터 보존 설정)
global:
scrape_interval: 15s # 기본 스크래핑 간격 (모든 작업에 적용)
evaluation_interval: 15s # 규칙 평가 간격 (알림 규칙 확인 빈도)
# 데이터 보존 기간 설정: 30d = 30일
# 이 기간이 지난 데이터는 자동으로 삭제됨
retention_time: 30d
# 또는 용량 기반: 1TB
# 데이터가 이 크기를 초과하면 가장 오래된 데이터부터 삭제
# retention_size: 1TB▶️ 스토리지 계산: 일반적인 쿠버네티스 클러스터에서 노드당 하루에 약 1-2GB 데이터가 생성됩니다. 10개 노드, 30일 보존 시 300-600GB의 스토리지가 필요합니다.
📌 서비스 디스커버리
동적인 클라우드 환경에서는 모니터링 대상이 계속 변화합니다. Prometheus는 다양한 서비스 디스커버리 메커니즘을 지원합니다.
✅ 지원하는 서비스 디스커버리 유형
- 파일 기반: 파일에 타겟 목록 정의
- DNS 기반: DNS SRV 레코드 조회
- 쿠버네티스: API 서버를 통한 자동 발견
- AWS, GCP, Azure: 클라우드 프로바이더 API 활용
- Consul, Etcd: 서비스 레지스트리 연동
✅ 쿠버네티스 서비스 디스커버리
쿠버네티스에서 Prometheus는 다양한 자원 유형을 자동으로 발견할 수 있습니다:
# kubernetes_sd_configs의 role 옵션
- role: node # 클러스터의 모든 노드
- role: service # 모든 서비스
- role: pod # 모든 파드
- role: endpoints # 서비스 엔드포인트
- role: ingress # 모든 인그레스
✅ 레이블 재작성(Relabeling)
서비스 디스커버리로 발견된 타겟을 필터링하거나 메타데이터를 변환하는 강력한 메커니즘:
scrape_configs:
- job_name: 'kubernetes-pods' # 작업 이름
kubernetes_sd_configs: # 쿠버네티스 서비스 디스커버리 설정
- role: pod # 파드 역할 지정 (모든 파드를 대상으로 발견)
relabel_configs: # 레이블 재작성 규칙들
# Prometheus 스크래핑을 활성화한 파드만 선택
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape] # 파드 어노테이션에서 가져온 값
action: keep # 조건 일치시 유지, 불일치시 제외
regex: true # 'true' 값과 일치하는지 확인
# 포트 지정 (파드 어노테이션에서 포트 정보 활용)
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_port] # 파드 어노테이션에서 포트 값 가져옴
action: replace # 값 교체
regex: (\d+) # 숫자만 캡처하는 정규식
target_label: __metrics_path__ # 메트릭 경로 타겟 레이블
replacement: /metrics # 메트릭 경로를 /metrics로 설정
# 파드 IP를 타겟 주소로 사용
- source_labels: [__meta_kubernetes_pod_ip] # 파드 IP 주소 가져옴
action: replace # 값 교체
target_label: __address__ # 주소 타겟 레이블
regex: (.*) # 모든 문자 캡처
replacement: ${1}:9100 # 파드 IP에 9100 포트 추가 (Node Exporter 기본 포트)▶️ 디버깅 팁: 서비스 디스커버리 문제를 디버깅할 때는 Prometheus 웹 UI의 Status > Targets 페이지를 확인하세요. 여기서 발견된 모든 타겟과 메타데이터를 볼 수 있습니다.
📌 PromQL 엔진의 작동 원리
Prometheus의 쿼리 언어인 PromQL은 시계열 데이터를 효율적으로 조회하고 분석하기 위해 설계되었습니다.
✅ 쿼리 실행 단계
- 파싱: 쿼리 문자열을 구문 트리로 변환
- 실행 계획: 최적의 데이터 접근 방법 결정
- 데이터 추출: TSDB에서 관련 시계열 로드
- 연산 실행: 필터링, 집계, 함수 적용
- 결과 포맷팅: 반환 형식에 맞게 데이터 가공
✅ 쿼리 유형
- 인스턴트 쿼리(Instant Query): 특정 시점의 값
- 범위 쿼리(Range Query): 시간 범위에 대한 값들
✅ PromQL 연산자
PromQL은 다양한 연산자를 제공합니다:
- 산술 연산자: +, -, *, /, %, ^
- 비교 연산자: ==, !=, >, <, >=, <=
- 논리 연산자: and, or, unless
- 집계 연산자: sum, avg, min, max, count
- 조인 연산: 라벨 매칭 기반 시계열 조인
# 복잡한 PromQL 예시 및 단계별 실행
# 1. 모든 HTTP 요청 비율 계산
rate(http_requests_total[5m])
# 2. 상태 코드별 그룹화
sum(rate(http_requests_total[5m])) by (status_code)
# 3. 에러 비율 계산
sum(rate(http_requests_total{status_code=~"5.."}[5m])) /
sum(rate(http_requests_total[5m])) * 100
▶️ 성능 팁: 복잡한 PromQL 쿼리는 많은 리소스를 소모할 수 있습니다. 필요한 데이터만 정확히 필터링하고, rate() 함수의 시간 창을 필요 이상으로 크게 잡지 마세요.
📌 알림 시스템
Prometheus는 강력한 알림 시스템을 제공하며, 이는 두 부분으로 구성됩니다.
✅ 알림 규칙 (Alert Rules)
Prometheus 서버에서 정의되며 지속적으로 평가됩니다:
# prometheus.yml 또는 별도 파일로 포함 - 알림 규칙 설정
groups:
- name: example # 알림 그룹 이름
rules:
- alert: HighErrorRate # 알림 이름
expr: sum(rate(http_requests_total{status_code=~"5.."}[5m])) / sum(rate(http_requests_total[5m])) > 0.1
# 표현식 설명: 5xx 에러 비율이 전체 요청의 10% 이상인지 확인
# rate(http_requests_total{status_code=~"5.."}[5m]) - 5분간 5xx 에러 발생 비율
# sum(...) / sum(...) - 모든 서비스/엔드포인트의 에러율 합산하여 비율 계산
# > 0.1 - 10% 임계값 설정
for: 10m # 지속 시간 (10분 동안 조건이 계속 충족되어야 알림 발생)
labels:
severity: critical # 심각도 레이블 (알림 분류 및 라우팅에 사용)
annotations:
summary: "High error rate detected" # 알림 요약 (간단한 문제 설명)
description: "Error rate is above 10% for 10 minutes (current value: {{ $value }})"
# 알림 상세 설명 ({{ $value }}는 실제 측정값으로 대체됨)✅ Alertmanager
알림을 수신하고 다양한 채널로 전달하는 별도 컴포넌트:
# alertmanager.yml - Alertmanager 설정
global:
resolve_timeout: 5m # 알림 해결 타임아웃 (5분 동안 알림이 해결되면 resolved 상태로 전환)
route: # 알림 라우팅 설정
group_by: ['alertname', 'job'] # 알림 그룹화 기준 (같은 alertname과 job 레이블을 가진 알림을 함께 그룹화)
group_wait: 30s # 첫 알림 후 그룹의 다른 알림을 기다리는 시간
group_interval: 5m # 같은 그룹에 대한 알림 전송 간격
repeat_interval: 12h # 알림 반복 간격 (해결되지 않은 알림 재전송)
receiver: 'slack-notifications' # 기본 수신자 지정
receivers: # 알림 수신자 설정
- name: 'slack-notifications' # 수신자 이름
slack_configs: # Slack 설정
- api_url: 'https://hooks.slack.com/services/T00000000/B00000000/XXXXXXXXXXXXXXXXXXXXXXXX' # Slack 웹훅 URL
channel: '#monitoring-alerts' # 알림을 보낼 Slack 채널
send_resolved: true # 알림 해결 시에도 메시지 전송 (해결 상태 통지)✅ 알림 상태 흐름
- Inactive: 규칙 조건이 충족되지 않음
- Pending: 조건 충족, 'for' 지속시간 대기 중
- Firing: 완전히 활성화된 알림, Alertmanager로 전송
- Resolved: 다시 조건이 충족되지 않아 해결됨

▶️ 알림 설계 원칙: "알림 피로(Alert Fatigue)"를 방지하기 위해 정말 인간의 개입이 필요한 상황에만 알림을 보내도록 설계하세요. 너무 많은 알림은 중요한 알림을 놓치는 원인이 됩니다.
📌 고가용성 및 확장성
Prometheus는 기본적으로 단일 인스턴스로 설계되었지만, 다양한 방법으로 고가용성과 확장성을 구현할 수 있습니다.
✅ 기본 HA 아키텍처
가장 간단한 HA 방식은 동일한 타겟을 스크래핑하는 여러 Prometheus 인스턴스를 실행하는 것입니다:
# Prometheus 1 및 Prometheus 2 모두 동일한 타겟 스크래핑
scrape_configs:
- job_name: 'kubernetes-nodes'
kubernetes_sd_configs:
- role: node
Alertmanager는 중복 알림을 자동으로 처리합니다:
# Alertmanager 클러스터링 설정
global:
# 기본 설정들...
cluster: # 클러스터 설정
peers: # 피어 노드 목록 (고가용성을 위한 Alertmanager 인스턴스들)
- alertmanager-1:9094 # 첫 번째 Alertmanager 인스턴스 (9094는 클러스터링 포트)
- alertmanager-2:9094 # 두 번째 Alertmanager 인스턴스
- alertmanager-3:9094 # 세 번째 Alertmanager 인스턴스
# 이렇게 구성하면 한 인스턴스가 다운되어도 알림 처리 가능
✅ 대규모 배포를 위한 아키텍처
대규모 환경에서는 다음과 같은 패턴을 사용합니다:
- 샤딩(Sharding): 타겟을 여러 Prometheus 인스턴스로 분할
- 계층화(Hierarchical): 하위 Prometheus가 데이터 수집, 상위는 집계
- 원격 스토리지: 장기 저장소로 데이터 전송
- 페더레이션(Federation): 여러 Prometheus 인스턴스에서 선택적 데이터 수집
- Thanos/Cortex: 분산 Prometheus 시스템
▶️ 스케일링 전략: 단일 Prometheus 인스턴스는 일반적으로 수천 개의 타겟에서 초당 수백만 개의 메트릭을 처리할 수 있습니다. 그 이상의 규모에서는 기능 샤딩(예: 노드 메트릭용 별도 인스턴스)을 고려하세요.
📌 원격 스토리지 통합
Prometheus의 로컬 스토리지는 제한적이므로, 장기 보관이나 고급 쿼리에는 원격 스토리지 통합이 필요합니다.
✅ 원격 스토리지 설정
# prometheus.yml - 원격 스토리지 설정
remote_write: # 원격 저장소 쓰기 설정
- url: "http://remote-storage:9201/write" # 데이터를 보낼 원격 저장소 URL
basic_auth: # 기본 인증 정보
username: "prometheus" # 사용자 이름
password: "password" # 비밀번호
# 여기에 추가 설정 가능:
# - queue_config: 쓰기 큐 설정
# - write_relabel_configs: 쓰기 전 레이블 재작성
# - tls_config: TLS/SSL 설정
remote_read: # 원격 저장소 읽기 설정
- url: "http://remote-storage:9201/read" # 데이터를 읽을 원격 저장소 URL
basic_auth: # 기본 인증 정보
username: "prometheus" # 사용자 이름
password: "password" # 비밀번호
# 추가 설정:
# - read_recent: 최근 데이터도 원격에서 읽을지 여부
# - required_matchers: 특정 레이블이 있는 데이터만 읽기
✅ 인기있는 원격 스토리지 솔루션
- Thanos: 무제한 보존 및 글로벌 쿼리
- Cortex: 멀티테넌트 Prometheus-as-a-Service
- M3DB: Uber의 분산형 TSDB
- VictoriaMetrics: 고성능 TSDB
- TimescaleDB: PostgreSQL 기반 시계열 DB
- InfluxDB: 전용 시계열 데이터베이스
▶️ 원격 스토리지 선택 팁: 이상적인 원격 스토리지는 PromQL 호환성을 제공하고, 효율적인 압축을 통해 스토리지 비용을 최적화하며, 쿼리 성능에 큰 영향을 주지 않아야 합니다.
📌 Summary: Prometheus 아키텍처의 강점
- Prometheus는 신뢰성과 단순성을 최우선으로 설계된 모니터링 시스템입니다.
- Pull 모델은 건강 상태 확인과 중앙 관리를 가능하게 합니다.
- 자체 TSDB는 시계열 데이터를 효율적으로 저장하고 쿼리합니다.
- 서비스 디스커버리와 레이블 재작성은 동적 환경에 적응합니다.
- PromQL은 시계열 데이터를 위한 강력한 쿼리 언어를 제공합니다.
- 알림 시스템은 문제를 조기에 발견하고 대응할 수 있게 합니다.
- 다양한 확장성 옵션을 통해 대규모 환경에도 적용 가능합니다.